MARL-LNS: Cooperative Multi-agent Reinforcement Learning via Large Neighborhoods Search
2404.03101
0
0
Abstract
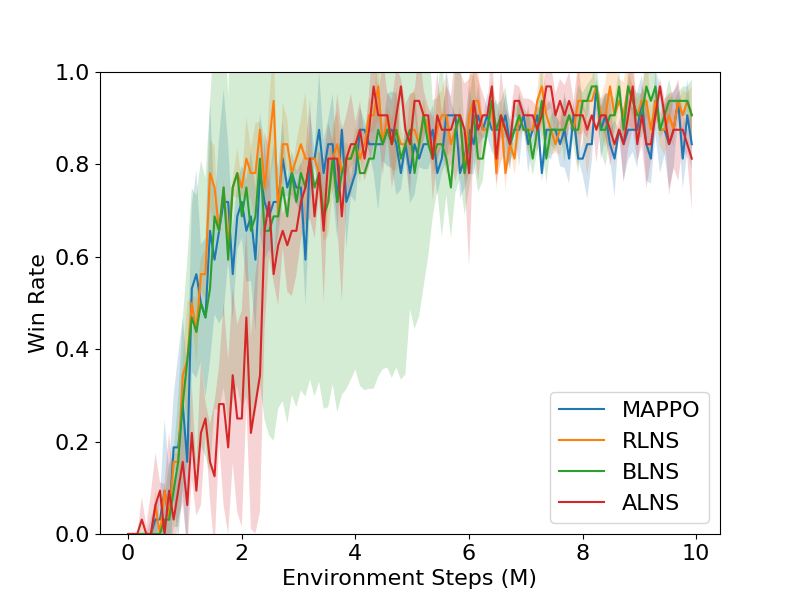
Cooperative multi-agent reinforcement learning (MARL) has been an increasingly important research topic in the last half-decade because of its great potential for real-world applications. Because of the curse of dimensionality, the popular centralized training decentralized execution framework requires a long time in training, yet still cannot converge efficiently. In this paper, we propose a general training framework, MARL-LNS, to algorithmically address these issues by training on alternating subsets of agents using existing deep MARL algorithms as low-level trainers, while not involving any additional parameters to be trained. Based on this framework, we provide three algorithm variants based on the framework: random large neighborhood search (RLNS), batch large neighborhood search (BLNS), and adaptive large neighborhood search (ALNS), which alternate the subsets of agents differently. We test our algorithms on both the StarCraft Multi-Agent Challenge and Google Research Football, showing that our algorithms can automatically reduce at least 10% of training time while reaching the same final skill level as the original algorithm.
Create account to get full access
Overview
- This paper introduces MARL-LNS, a new approach to cooperative multi-agent reinforcement learning that leverages large neighborhood search.
- The key idea is to have agents coordinate their actions by searching over large neighborhoods of joint actions, rather than just their individual actions.
- This allows the agents to better explore the space of possible joint behaviors and find more optimal solutions to cooperative tasks.
- The paper presents the technical details of the MARL-LNS algorithm and evaluates its performance on several benchmark multi-agent environments.
Plain English Explanation
The paper describes a new way for multiple AI agents to work together and learn how to complete tasks more effectively. Traditional reinforcement learning has each agent optimize its own actions independently. In contrast, MARL-LNS allows the agents to consider the actions of all the other agents when deciding what to do.
Imagine a team of robots trying to move objects around a warehouse. With the standard approach, each robot would just focus on its own movements without considering how the other robots are moving. But with MARL-LNS, the robots can look at the bigger picture - they can see all the possible combinations of what each robot could do, and then choose the set of actions that works best for the whole team.
This gives the agents a richer search space to explore, enabling them to find more optimal joint strategies. For example, the robots might discover that by coordinating their movements, they can move objects more efficiently or avoid collisions. The paper shows that this collaborative approach leads to better performance on benchmark multi-agent tasks compared to having each agent act independently.
Technical Explanation
MARL-LNS is a multi-agent reinforcement learning algorithm that aims to improve cooperation between agents by allowing them to reason about joint actions, rather than just individual actions. The key components are:
- State Representation: Each agent maintains its own local state, which is combined with the states of the other agents to form the joint state.
- Action Space: Instead of just selecting its own action, each agent searches over the space of joint actions - i.e. the Cartesian product of all the agents' individual action spaces.
- Policy Learning: The agents learn a joint policy that maps the joint state to the optimal joint action, using a policy gradient method.
- Exploration: Rather than random exploration, MARL-LNS uses a large neighborhood search to efficiently explore the joint action space.
The paper shows that this joint planning and exploration approach leads to superior performance compared to independent Q-learning or policy gradient methods on several multi-agent benchmark tasks, including cooperative navigation, predator-prey, and resource collection.
Critical Analysis
The paper provides a thoughtful and technically sound approach to improving cooperation in multi-agent reinforcement learning. By having agents reason about joint actions rather than just individual ones, MARL-LNS is able to find more globally optimal solutions.
However, the approach does come with some limitations. Searching over the joint action space can be computationally expensive, especially as the number of agents increases. The paper notes that scalability may be a challenge in large-scale multi-agent systems.
Additionally, the algorithm assumes that the agents have full observability of the joint state. In many real-world scenarios, agents may have partial or noisy observations of the overall system state, which could make the joint planning problem much harder.
Further research could explore ways to make MARL-LNS more scalable, such as using hierarchical or decentralized approaches. Incorporating partial observability and communication constraints would also be an important next step to make the algorithm more applicable to realistic multi-agent settings.
Conclusion
Overall, the MARL-LNS algorithm represents a promising advance in multi-agent reinforcement learning. By shifting the focus from individual to joint action optimization, it allows agents to better coordinate their behaviors and find more globally optimal solutions to cooperative tasks. While there are some technical challenges to address, the core idea of collaborative planning holds significant potential for improving the performance of multi-agent systems in a wide range of applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

LNS2+RL: Combining Multi-agent Reinforcement Learning with Large Neighborhood Search in Multi-agent Path Finding
Yutong Wang, Tanishq Duhan, Jiaoyang Li, Guillaume Sartoretti
0
0
Multi-Agent Path Finding (MAPF) is a critical component of logistics and warehouse management, which focuses on planning collision-free paths for a team of robots in a known environment. Recent work introduced a novel MAPF approach, LNS2, which proposed to repair a quickly-obtainable set of infeasible paths via iterative re-planning, by relying on a fast, yet lower-quality, priority-based planner. At the same time, there has been a recent push for Multi-Agent Reinforcement Learning (MARL) based MAPF algorithms, which let agents learn decentralized policies that exhibit improved cooperation over such priority planning, although inevitably remaining slower. In this paper, we introduce a new MAPF algorithm, LNS2+RL, which combines the distinct yet complementary characteristics of LNS2 and MARL to effectively balance their individual limitations and get the best from both worlds. During early iterations, LNS2+RL relies on MARL for low-level re-planning, which we show eliminates collisions much more than a priority-based planner. There, our MARL-based planner allows agents to reason about past and future/predicted information to gradually learn cooperative decision-making through a finely designed curriculum learning. At later stages of planning, LNS2+RL adaptively switches to priority-based planning to quickly resolve the remaining collisions, naturally trading-off solution quality and computational efficiency. Our comprehensive experiments on challenging tasks across various team sizes, world sizes, and map structures consistently demonstrate the superior performance of LNS2+RL compared to many MAPF algorithms, including LNS2, LaCAM, and EECBS, where LNS2+RL shows significantly better performance in complex scenarios. We finally experimentally validate our algorithm in a hybrid simulation of a warehouse mockup involving a team of 100 (real-world and simulated) robots.
5/29/2024

Efficient Multi-agent Reinforcement Learning by Planning
Qihan Liu, Jianing Ye, Xiaoteng Ma, Jun Yang, Bin Liang, Chongjie Zhang
0
0
Multi-agent reinforcement learning (MARL) algorithms have accomplished remarkable breakthroughs in solving large-scale decision-making tasks. Nonetheless, most existing MARL algorithms are model-free, limiting sample efficiency and hindering their applicability in more challenging scenarios. In contrast, model-based reinforcement learning (MBRL), particularly algorithms integrating planning, such as MuZero, has demonstrated superhuman performance with limited data in many tasks. Hence, we aim to boost the sample efficiency of MARL by adopting model-based approaches. However, incorporating planning and search methods into multi-agent systems poses significant challenges. The expansive action space of multi-agent systems often necessitates leveraging the nearly-independent property of agents to accelerate learning. To tackle this issue, we propose the MAZero algorithm, which combines a centralized model with Monte Carlo Tree Search (MCTS) for policy search. We design a novel network structure to facilitate distributed execution and parameter sharing. To enhance search efficiency in deterministic environments with sizable action spaces, we introduce two novel techniques: Optimistic Search Lambda (OS($lambda$)) and Advantage-Weighted Policy Optimization (AWPO). Extensive experiments on the SMAC benchmark demonstrate that MAZero outperforms model-free approaches in terms of sample efficiency and provides comparable or better performance than existing model-based methods in terms of both sample and computational efficiency. Our code is available at https://github.com/liuqh16/MAZero.
5/21/2024
🤿
Online Control of Adaptive Large Neighborhood Search using Deep Reinforcement Learning
Robbert Reijnen, Yingqian Zhang, Hoong Chuin Lau, Zaharah Bukhsh
0
0
The Adaptive Large Neighborhood Search (ALNS) algorithm has shown considerable success in solving combinatorial optimization problems (COPs). Nonetheless, the performance of ALNS relies on the proper configuration of its selection and acceptance parameters, which is known to be a complex and resource-intensive task. To address this, we introduce a Deep Reinforcement Learning (DRL) based approach called DR-ALNS that selects operators, adjusts parameters, and controls the acceptance criterion throughout the search. The proposed method aims to learn, based on the state of the search, to configure ALNS for the next iteration to yield more effective solutions for the given optimization problem. We evaluate the proposed method on an orienteering problem with stochastic weights and time windows, as presented in an IJCAI competition. The results show that our approach outperforms vanilla ALNS, ALNS tuned with Bayesian optimization, and two state-of-the-art DRL approaches that were the winning methods of the competition, achieving this with significantly fewer training observations. Furthermore, we demonstrate several good properties of the proposed DR-ALNS method: it is easily adapted to solve different routing problems, its learned policies perform consistently well across various instance sizes, and these policies can be directly applied to different problem variants.
4/4/2024
🏅
Distributed Multi-Agent Reinforcement Learning Based on Graph-Induced Local Value Functions
Gangshan Jing, He Bai, Jemin George, Aranya Chakrabortty, Piyush K. Sharma
0
0
Achieving distributed reinforcement learning (RL) for large-scale cooperative multi-agent systems (MASs) is challenging because: (i) each agent has access to only limited information; (ii) issues on convergence or computational complexity emerge due to the curse of dimensionality. In this paper, we propose a general computationally efficient distributed framework for cooperative multi-agent reinforcement learning (MARL) by utilizing the structures of graphs involved in this problem. We introduce three coupling graphs describing three types of inter-agent couplings in MARL, namely, the state graph, the observation graph and the reward graph. By further considering a communication graph, we propose two distributed RL approaches based on local value-functions derived from the coupling graphs. The first approach is able to reduce sample complexity significantly under specific conditions on the aforementioned four graphs. The second approach provides an approximate solution and can be efficient even for problems with dense coupling graphs. Here there is a trade-off between minimizing the approximation error and reducing the computational complexity. Simulations show that our RL algorithms have a significantly improved scalability to large-scale MASs compared with centralized and consensus-based distributed RL algorithms.
4/15/2024