LAGMA: LAtent Goal-guided Multi-Agent Reinforcement Learning
2405.19998
0
0
Abstract
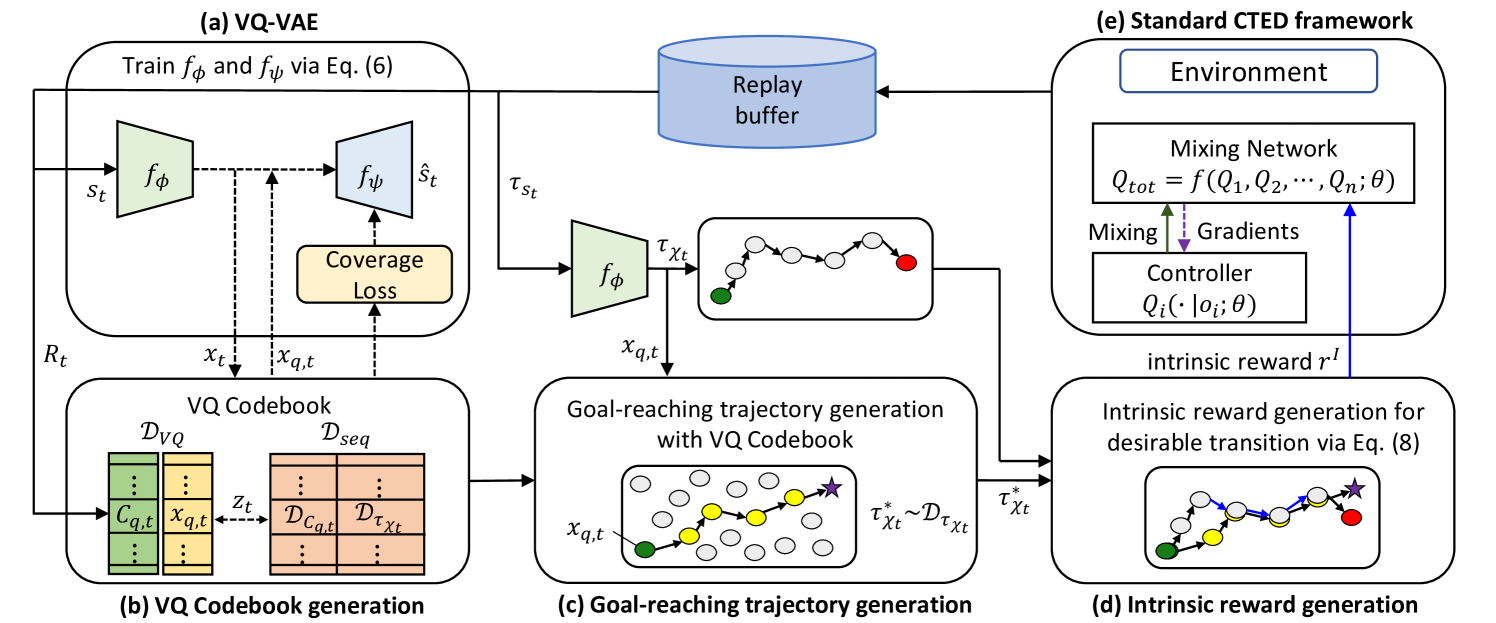
In cooperative multi-agent reinforcement learning (MARL), agents collaborate to achieve common goals, such as defeating enemies and scoring a goal. However, learning goal-reaching paths toward such a semantic goal takes a considerable amount of time in complex tasks and the trained model often fails to find such paths. To address this, we present LAtent Goal-guided Multi-Agent reinforcement learning (LAGMA), which generates a goal-reaching trajectory in latent space and provides a latent goal-guided incentive to transitions toward this reference trajectory. LAGMA consists of three major components: (a) quantized latent space constructed via a modified VQ-VAE for efficient sample utilization, (b) goal-reaching trajectory generation via extended VQ codebook, and (c) latent goal-guided intrinsic reward generation to encourage transitions towards the sampled goal-reaching path. The proposed method is evaluated by StarCraft II with both dense and sparse reward settings and Google Research Football. Empirical results show further performance improvement over state-of-the-art baselines.
Create account to get full access
Overview
- This paper proposes a novel reinforcement learning approach called LAGMA (LAtent Goal-guided Multi-Agent) for training multiple agents to collaborate effectively.
- The key idea is to learn a latent representation of the agents' shared goals, which helps them coordinate their actions more efficiently.
- The authors demonstrate LAGMA's effectiveness on several multi-agent benchmark tasks, showing improved performance compared to previous methods.
Plain English Explanation
In this paper, the researchers present a new way for multiple AI agents to work together called LAGMA (LAtent Goal-guided Multi-Agent). The main challenge in multi-agent systems is getting the agents to coordinate their actions to achieve a common goal. The LAGMA approach tries to address this by learning a hidden or "latent" representation of the agents' shared objectives.
This latent goal representation acts as a communication channel, allowing the agents to better understand each other's intentions and align their behaviors accordingly. Rather than each agent pursuing its own individual objectives, the latent goal guides them toward a collaborative solution.
The researchers tested LAGMA on various benchmark tasks involving multiple agents and found that it outperformed previous multi-agent reinforcement learning methods. By leveraging this shared latent goal, the agents were able to coordinate more effectively and achieve better overall performance.
The key insight is that explicitly modeling the agents' common objectives, even in a hidden way, can significantly improve collaboration and task completion in multi-agent settings. This builds on related work in multi-agent reinforcement learning and language model grounding.
Technical Explanation
The LAGMA approach consists of several key components. First, the agents learn a shared latent goal representation through a goal encoder network. This latent goal captures the common objective that the agents are trying to achieve, even if it is not directly observable.
Each agent then uses this latent goal, along with its own local observations, to select actions that move the system toward the shared goal. This is implemented through a goal-conditioned policy network for each agent. The policies are trained via multi-agent reinforcement learning, with the latent goal guiding the exploration and learning process.
The authors demonstrate LAGMA's effectiveness on several multi-agent benchmark tasks, including cooperative navigation, predator-prey, and reference game environments. Compared to baselines like QMIX and MAVEN, LAGMA shows improved performance, especially in tasks requiring tight coordination among the agents.
Critical Analysis
The LAGMA approach makes a compelling contribution to the field of multi-agent reinforcement learning. By explicitly modeling the shared latent goal, the agents are able to coordinate their actions more effectively, leading to better overall task performance.
However, the paper does not extensively explore the limitations or failure modes of the LAGMA method. For example, it would be interesting to see how it handles environments with conflicting or shifting goals, where the latent representation may need to be more dynamic.
Additionally, the paper could delve deeper into the interpretability of the learned latent goal. Understanding how this representation captures the agents' shared objectives could provide valuable insights for multi-agent system design and deployment.
Further research is also needed to understand the scalability of LAGMA as the number of agents and the complexity of the environment increases. The paper's experiments are relatively small-scale, and it's unclear how well the method would generalize to larger, more realistic multi-agent scenarios.
Conclusion
The LAGMA approach proposed in this paper represents an important step forward in multi-agent reinforcement learning. By learning a shared latent goal representation, the agents are able to coordinate their actions more effectively, leading to improved performance on a variety of benchmark tasks.
This work builds on and extends previous research in areas like multi-agent coordination and language model grounding, demonstrating the potential of integrating latent representations into multi-agent systems.
As the field of multi-agent AI continues to evolve, techniques like LAGMA will become increasingly important for enabling effective collaboration and coordination among intelligent agents, whether in simulated environments or real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Representation Learning For Efficient Deep Multi-Agent Reinforcement Learning
Dom Huh, Prasant Mohapatra
0
0
Sample efficiency remains a key challenge in multi-agent reinforcement learning (MARL). A promising approach is to learn a meaningful latent representation space through auxiliary learning objectives alongside the MARL objective to aid in learning a successful control policy. In our work, we present MAPO-LSO (Multi-Agent Policy Optimization with Latent Space Optimization) which applies a form of comprehensive representation learning devised to supplement MARL training. Specifically, MAPO-LSO proposes a multi-agent extension of transition dynamics reconstruction and self-predictive learning that constructs a latent state optimization scheme that can be trivially extended to current state-of-the-art MARL algorithms. Empirical results demonstrate MAPO-LSO to show notable improvements in sample efficiency and learning performance compared to its vanilla MARL counterpart without any additional MARL hyperparameter tuning on a diverse suite of MARL tasks.
6/6/2024
🏅
LLM-based Multi-Agent Reinforcement Learning: Current and Future Directions
Chuanneng Sun, Songjun Huang, Dario Pompili
0
0
In recent years, Large Language Models (LLMs) have shown great abilities in various tasks, including question answering, arithmetic problem solving, and poem writing, among others. Although research on LLM-as-an-agent has shown that LLM can be applied to Reinforcement Learning (RL) and achieve decent results, the extension of LLM-based RL to Multi-Agent System (MAS) is not trivial, as many aspects, such as coordination and communication between agents, are not considered in the RL frameworks of a single agent. To inspire more research on LLM-based MARL, in this letter, we survey the existing LLM-based single-agent and multi-agent RL frameworks and provide potential research directions for future research. In particular, we focus on the cooperative tasks of multiple agents with a common goal and communication among them. We also consider human-in/on-the-loop scenarios enabled by the language component in the framework.
5/21/2024

Efficient Multi-agent Reinforcement Learning by Planning
Qihan Liu, Jianing Ye, Xiaoteng Ma, Jun Yang, Bin Liang, Chongjie Zhang
0
0
Multi-agent reinforcement learning (MARL) algorithms have accomplished remarkable breakthroughs in solving large-scale decision-making tasks. Nonetheless, most existing MARL algorithms are model-free, limiting sample efficiency and hindering their applicability in more challenging scenarios. In contrast, model-based reinforcement learning (MBRL), particularly algorithms integrating planning, such as MuZero, has demonstrated superhuman performance with limited data in many tasks. Hence, we aim to boost the sample efficiency of MARL by adopting model-based approaches. However, incorporating planning and search methods into multi-agent systems poses significant challenges. The expansive action space of multi-agent systems often necessitates leveraging the nearly-independent property of agents to accelerate learning. To tackle this issue, we propose the MAZero algorithm, which combines a centralized model with Monte Carlo Tree Search (MCTS) for policy search. We design a novel network structure to facilitate distributed execution and parameter sharing. To enhance search efficiency in deterministic environments with sizable action spaces, we introduce two novel techniques: Optimistic Search Lambda (OS($lambda$)) and Advantage-Weighted Policy Optimization (AWPO). Extensive experiments on the SMAC benchmark demonstrate that MAZero outperforms model-free approaches in terms of sample efficiency and provides comparable or better performance than existing model-based methods in terms of both sample and computational efficiency. Our code is available at https://github.com/liuqh16/MAZero.
5/21/2024

World Models with Hints of Large Language Models for Goal Achieving
Zeyuan Liu, Ziyu Huan, Xiyao Wang, Jiafei Lyu, Jian Tao, Xiu Li, Furong Huang, Huazhe Xu
0
0
Reinforcement learning struggles in the face of long-horizon tasks and sparse goals due to the difficulty in manual reward specification. While existing methods address this by adding intrinsic rewards, they may fail to provide meaningful guidance in long-horizon decision-making tasks with large state and action spaces, lacking purposeful exploration. Inspired by human cognition, we propose a new multi-modal model-based RL approach named Dreaming with Large Language Models (DLLM). DLLM integrates the proposed hinting subgoals from the LLMs into the model rollouts to encourage goal discovery and reaching in challenging tasks. By assigning higher intrinsic rewards to samples that align with the hints outlined by the language model during model rollouts, DLLM guides the agent toward meaningful and efficient exploration. Extensive experiments demonstrate that the DLLM outperforms recent methods in various challenging, sparse-reward environments such as HomeGrid, Crafter, and Minecraft by 27.7%, 21.1%, and 9.9%, respectively.
6/12/2024