GrowOVER: How Can LLMs Adapt to Growing Real-World Knowledge?

0

Sign in to get full access
Overview
- This paper, "GrowOVER: How Can LLMs Adapt to Growing Real-World Knowledge?", explores how large language models (LLMs) can keep up with the constantly evolving real-world knowledge.
- The authors propose GrowOVER, a framework that enables LLMs to continually update their knowledge and adapt to new information without forgetting what they've already learned.
- The paper investigates techniques for efficiently incorporating new knowledge into LLMs, while maintaining their performance on existing tasks.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have become incredibly powerful at understanding and generating human-like text. However, the real-world knowledge these models are trained on can quickly become outdated as new information emerges. The authors of this paper want to find a way for LLMs to continuously learn and adapt to growing knowledge, rather than becoming stagnant.
They propose a framework called "GrowOVER" that allows LLMs to continuously update their knowledge without forgetting what they've already learned. Imagine an AI assistant that can keep up with the latest news, scientific discoveries, and cultural trends, rather than being limited to the information it was trained on years ago.
The key is finding efficient ways to incorporate new knowledge into the LLM without disrupting its existing capabilities. The paper explores different techniques for doing this, such as selectively updating parts of the model or using specialized modules to handle new information. The goal is to create LLMs that can adapt and grow along with the real world, becoming more useful and relevant over time.
This research on continual learning for LLMs and techniques for enhancing question-answering with external knowledge are closely related and could inform the development of the GrowOVER framework.
Technical Explanation
The GrowOVER framework proposed in this paper aims to enable large language models (LLMs) to continuously update their knowledge to keep up with the constantly evolving real-world information. The authors identify two key challenges: 1) efficiently incorporating new knowledge without catastrophically forgetting existing knowledge, and 2) maintaining the model's performance on existing tasks as new knowledge is added.
To address these challenges, the GrowOVER framework introduces several key components:
-
Selective Knowledge Update: Rather than updating the entire model, GrowOVER selectively updates only the relevant parts of the LLM to incorporate new knowledge. This helps prevent forgetting of existing information.
-
Knowledge Distillation: GrowOVER uses knowledge distillation techniques to transfer knowledge from specialized modules that handle new information into the main LLM. This allows the model to learn new concepts without compromising its overall performance.
-
Retrieval-Augmented Generation: The framework integrates a retrieval module that can dynamically access external knowledge sources, such as domain-specific question-answering knowledge bases, to supplement the LLM's responses with up-to-date information.
-
Continual Learning Strategies: GrowOVER employs advanced continual learning techniques, such as cross-data knowledge graph construction and dynamic learning strategies, to enable the LLM to continuously adapt to new knowledge without forgetting its previous learning.
Through extensive experiments, the authors demonstrate the effectiveness of the GrowOVER framework in adapting LLMs to growing real-world knowledge while preserving their performance on existing tasks.
Critical Analysis
The GrowOVER framework presented in this paper addresses an important challenge in the field of large language models (LLMs): how to keep these models up-to-date with the constantly evolving real-world knowledge. The authors' approach of selectively updating the LLM, using knowledge distillation, and integrating retrieval-augmented generation is a promising step towards achieving this goal.
However, the paper does not fully address some potential limitations and concerns:
-
Scalability: The authors do not extensively discuss how the GrowOVER framework would scale to handle the vast amounts of new information being generated in the real world. Incorporating knowledge at a large scale while maintaining model performance remains a significant challenge.
-
Bias and Fairness: As LLMs continue to adapt and update their knowledge, there is a risk of introducing new biases or perpetuating existing ones. The paper does not address how the GrowOVER framework might mitigate such issues.
-
Transparency and Explainability: The inner workings of the GrowOVER framework, particularly the selective knowledge update and knowledge distillation processes, could benefit from greater transparency and explainability. This would help users understand how the model's knowledge is evolving and build trust in the system.
-
Real-World Deployment: The paper focuses on the technical aspects of the GrowOVER framework but does not discuss the practical challenges of deploying such a system in real-world scenarios, where factors like data availability, privacy, and user expectations must be carefully considered.
Overall, the GrowOVER framework represents an important step towards addressing the challenge of adapting LLMs to growing real-world knowledge. However, further research is needed to address the limitations and ensure the long-term viability and responsible deployment of such systems.
Conclusion
The "GrowOVER: How Can LLMs Adapt to Growing Real-World Knowledge?" paper proposes a novel framework for enabling large language models (LLMs) to continuously update their knowledge and adapt to the constantly evolving real-world information. By selectively updating the model, using knowledge distillation techniques, and integrating retrieval-augmented generation, the GrowOVER framework aims to help LLMs stay relevant and useful over time.
The research presented in this paper represents an important advancement in the field of continual learning for LLMs, with potential implications for a wide range of applications, from virtual assistants to question-answering systems. As the real-world knowledge landscape continues to expand, the ability of LLMs to adapt and grow alongside it will be crucial for maintaining their effectiveness and relevance. The GrowOVER framework and the related research on continual learning and knowledge integration highlighted in this summary provide a promising path forward in this direction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GrowOVER: How Can LLMs Adapt to Growing Real-World Knowledge?
Dayoon Ko, Jinyoung Kim, Hahyeon Choi, Gunhee Kim
In the real world, knowledge is constantly evolving, which can render existing knowledge-based datasets outdated. This unreliability highlights the critical need for continuous updates to ensure both accuracy and relevance in knowledge-intensive tasks. To address this, we propose GrowOVER-QA and GrowOVER-Dialogue, dynamic open-domain QA and dialogue benchmarks that undergo a continuous cycle of updates, keeping pace with the rapid evolution of knowledge. Our research indicates that retrieval-augmented language models (RaLMs) struggle with knowledge that has not been trained on or recently updated. Consequently, we introduce a novel retrieval-interactive language model framework, where the language model evaluates and reflects on its answers for further re-retrieval. Our exhaustive experiments demonstrate that our training-free framework significantly improves upon existing methods, performing comparably to or even surpassing continuously trained language models.
Read more6/11/2024
💬
0
Carpe Diem: On the Evaluation of World Knowledge in Lifelong Language Models
Yujin Kim, Jaehong Yoon, Seonghyeon Ye, Sangmin Bae, Namgyu Ho, Sung Ju Hwang, Se-young Yun
The dynamic nature of knowledge in an ever-changing world presents challenges for language models trained on static data; the model in the real world often requires not only acquiring new knowledge but also overwriting outdated information into updated ones. To study the ability of language models for these time-dependent dynamics in human language, we introduce a novel task, EvolvingQA, a temporally evolving question-answering benchmark designed for training and evaluating LMs on an evolving Wikipedia database. The construction of EvolvingQA is automated with our pipeline using large language models. We uncover that existing continual learning baselines suffer from updating and removing outdated knowledge. Our analysis suggests that models fail to rectify knowledge due to small weight gradients. In addition, we elucidate that language models particularly struggle to reflect the change of numerical or temporal information. Our work aims to model the dynamic nature of real-world information, suggesting faithful evaluations of the evolution-adaptability of language models.
Read more4/23/2024
0
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
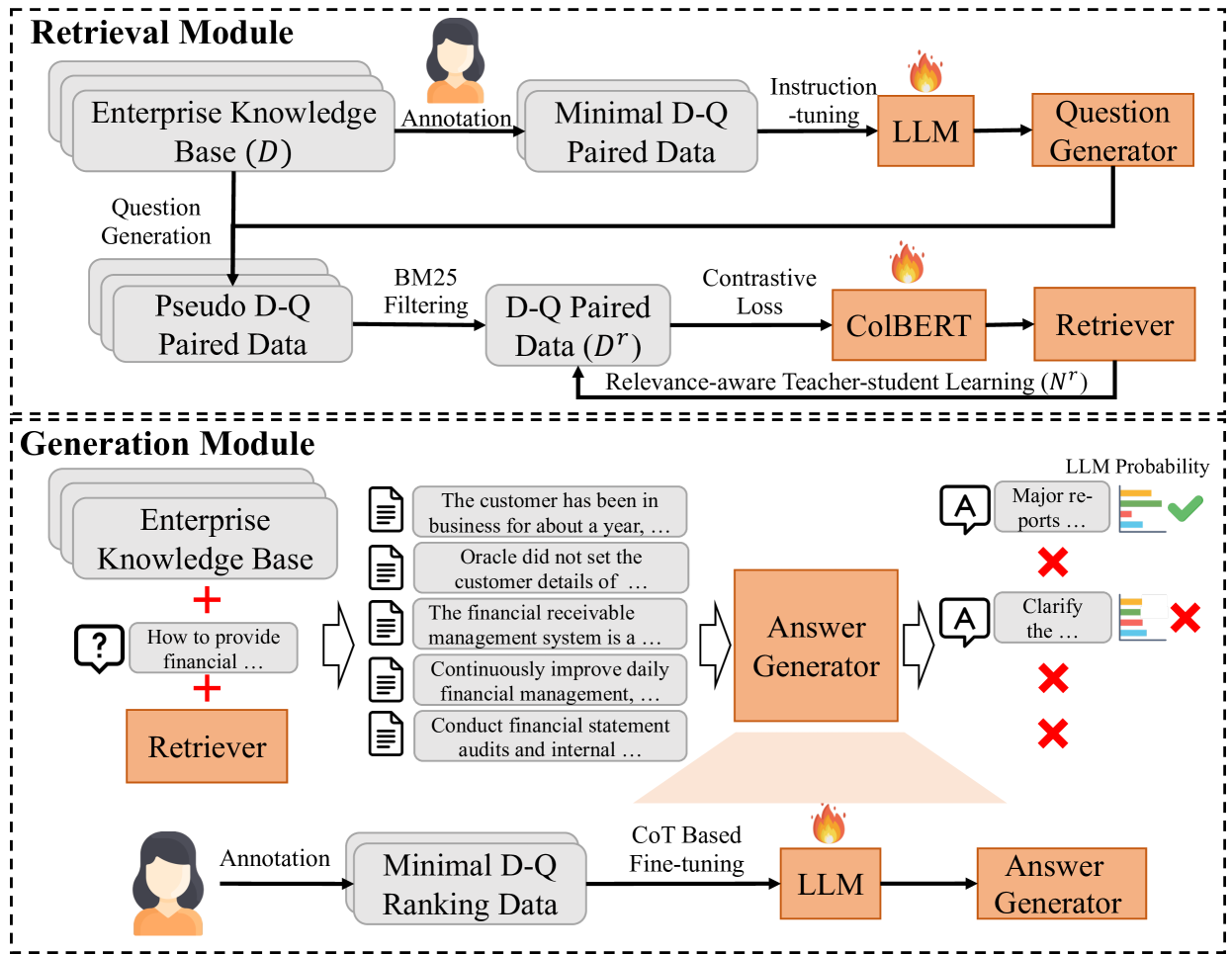
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
Read more4/23/2024
0
Learning to Plan for Retrieval-Augmented Large Language Models from Knowledge Graphs
Junjie Wang, Mingyang Chen, Binbin Hu, Dan Yang, Ziqi Liu, Yue Shen, Peng Wei, Zhiqiang Zhang, Jinjie Gu, Jun Zhou, Jeff Z. Pan, Wen Zhang, Huajun Chen
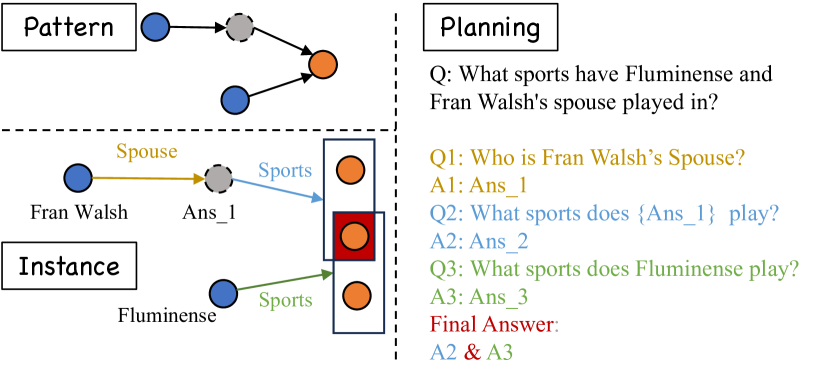
Improving the performance of large language models (LLMs) in complex question-answering (QA) scenarios has always been a research focal point. Recent studies have attempted to enhance LLMs' performance by combining step-wise planning with external retrieval. While effective for advanced models like GPT-3.5, smaller LLMs face challenges in decomposing complex questions, necessitating supervised fine-tuning. Previous work has relied on manual annotation and knowledge distillation from teacher LLMs, which are time-consuming and not accurate enough. In this paper, we introduce a novel framework for enhancing LLMs' planning capabilities by using planning data derived from knowledge graphs (KGs). LLMs fine-tuned with this data have improved planning capabilities, better equipping them to handle complex QA tasks that involve retrieval. Evaluations on multiple datasets, including our newly proposed benchmark, highlight the effectiveness of our framework and the benefits of KG-derived planning data.
Read more6/21/2024