Learning to Plan for Retrieval-Augmented Large Language Models from Knowledge Graphs
2406.14282
0
0
Abstract
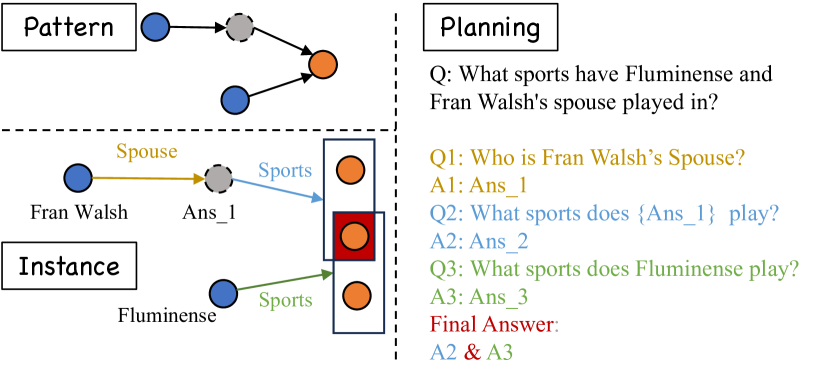
Improving the performance of large language models (LLMs) in complex question-answering (QA) scenarios has always been a research focal point. Recent studies have attempted to enhance LLMs' performance by combining step-wise planning with external retrieval. While effective for advanced models like GPT-3.5, smaller LLMs face challenges in decomposing complex questions, necessitating supervised fine-tuning. Previous work has relied on manual annotation and knowledge distillation from teacher LLMs, which are time-consuming and not accurate enough. In this paper, we introduce a novel framework for enhancing LLMs' planning capabilities by using planning data derived from knowledge graphs (KGs). LLMs fine-tuned with this data have improved planning capabilities, better equipping them to handle complex QA tasks that involve retrieval. Evaluations on multiple datasets, including our newly proposed benchmark, highlight the effectiveness of our framework and the benefits of KG-derived planning data.
Create account to get full access
Overview
- This paper explores a novel approach to improving the performance of large language models (LLMs) on retrieval-augmented tasks by learning to plan effective retrieval strategies from knowledge graphs.
- The authors propose a model that can learn to plan a sequence of retrieval steps to gather relevant information from a knowledge graph, which is then used to enhance the LLM's reasoning and output.
- The goal is to enable LLMs to better leverage structured knowledge from knowledge graphs to improve their understanding and reasoning capabilities, particularly for tasks that require retrieving and integrating information from multiple sources.
Plain English Explanation
Large language models (LLMs) like GPT-3 are incredibly powerful, but they can struggle with certain types of tasks that require integrating information from multiple sources or reasoning about structured knowledge. This paper explores a way to help LLMs perform better on these kinds of "retrieval-augmented" tasks.
The key idea is to teach the LLM how to effectively plan a sequence of retrieval steps to gather relevant information from a knowledge graph, which is a structured database of facts and relationships. By learning this retrieval planning skill, the LLM can then use the gathered information to enhance its reasoning and output for tasks that require drawing insights from multiple pieces of knowledge.
For example, imagine a task where the LLM needs to answer a question that requires understanding the relationship between different entities, like "How are the functions of the heart and lungs connected?" To answer this, the LLM would need to retrieve relevant information about the heart, lungs, and their physiological connections from a knowledge graph, and then reason about how to integrate that information to provide a complete answer. This paper explores how knowledge graphs can guide LLMs to reason more effectively.
By learning to plan efficient retrieval strategies, the LLM can become better at identifying and gathering the specific pieces of information it needs to tackle complex, multi-step reasoning tasks like this one. This approach could help LLMs leverage structured knowledge more effectively and improve their overall performance on a variety of real-world applications.
Technical Explanation
The authors propose a novel model architecture called the Knowledge-Augmented Planner (KAP) that combines a large language model (LLM) with a retrieval planning module. The LLM serves as the primary reasoning engine, while the retrieval planner learns to dynamically construct a sequence of retrieval steps from a knowledge graph to gather relevant information to enhance the LLM's understanding and output.
The key components of the KAP model are:
- Retrieval Planner: This module takes the current input task and the knowledge graph as input, and learns to predict a sequence of retrieval steps that will gather the most relevant information to solve the task.
- Knowledge Retriever: This module executes the retrieval plan produced by the Retrieval Planner, fetching the necessary information from the knowledge graph.
- Knowledge-Augmented LLM: The LLM takes the original input along with the retrieved knowledge to generate the final output.
The authors train the Retrieval Planner using reinforcement learning, where the model learns to optimize its retrieval plans to maximize the LLM's performance on the target tasks. This approach of integrating structured knowledge from a knowledge graph can help LLMs reason more effectively and improve their performance on tasks that require retrieving and combining information from multiple sources.
Critical Analysis
The authors present a compelling approach to enhancing the capabilities of large language models by enabling them to better leverage structured knowledge from knowledge graphs. The proposed KAP model offers a promising way to address the limitations of LLMs in handling retrieval-augmented tasks that require integrating information from multiple sources.
However, the authors acknowledge several limitations and areas for further research:
- Scalability: The current implementation of the Retrieval Planner may not scale well to very large knowledge graphs, as the planning process could become computationally expensive. Exploring more efficient planning algorithms could be an important area of future work.
- Generalization: The authors note that the KAP model may not generalize well to tasks or knowledge domains that are significantly different from those used during training. Developing more robust and adaptable planning strategies could help address this challenge.
- Real-world Applicability: While the paper demonstrates the effectiveness of the KAP model on synthetic and benchmark tasks, it remains to be seen how well the approach would translate to real-world applications with noisier, less structured data. Evaluating the model's performance on more realistic, enterprise-level knowledge bases could provide valuable insights.
Overall, the research presented in this paper represents an important step towards enabling large language models to better leverage structured knowledge and improve their reasoning capabilities. The proposed KAP model offers a promising direction for further exploration and development in the field of knowledge-enhanced language understanding.
Conclusion
This paper introduces a novel approach to improving the performance of large language models on retrieval-augmented tasks by enabling them to effectively plan and execute retrieval strategies from knowledge graphs. The proposed Knowledge-Augmented Planner (KAP) model combines an LLM with a retrieval planning module that learns to dynamically construct a sequence of retrieval steps to gather relevant information and enhance the LLM's reasoning and output.
The authors demonstrate the effectiveness of the KAP model on a range of synthetic and benchmark tasks, showing that it can outperform standalone LLMs on retrieval-augmented reasoning and question-answering activities. This research represents an important step towards enabling LLMs to better leverage structured knowledge and improve their overall capabilities, which could have significant implications for a wide range of real-world applications that require integrating information from multiple sources.
While the paper identifies several limitations and areas for further work, the core ideas presented in this research offer a compelling path forward for enhancing the knowledge-reasoning abilities of large language models and advancing the field of AI-powered language understanding.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
Xinbang Dai, Yuncheng Hua, Tongtong Wu, Yang Sheng, Qiu Ji, Guilin Qi
0
0
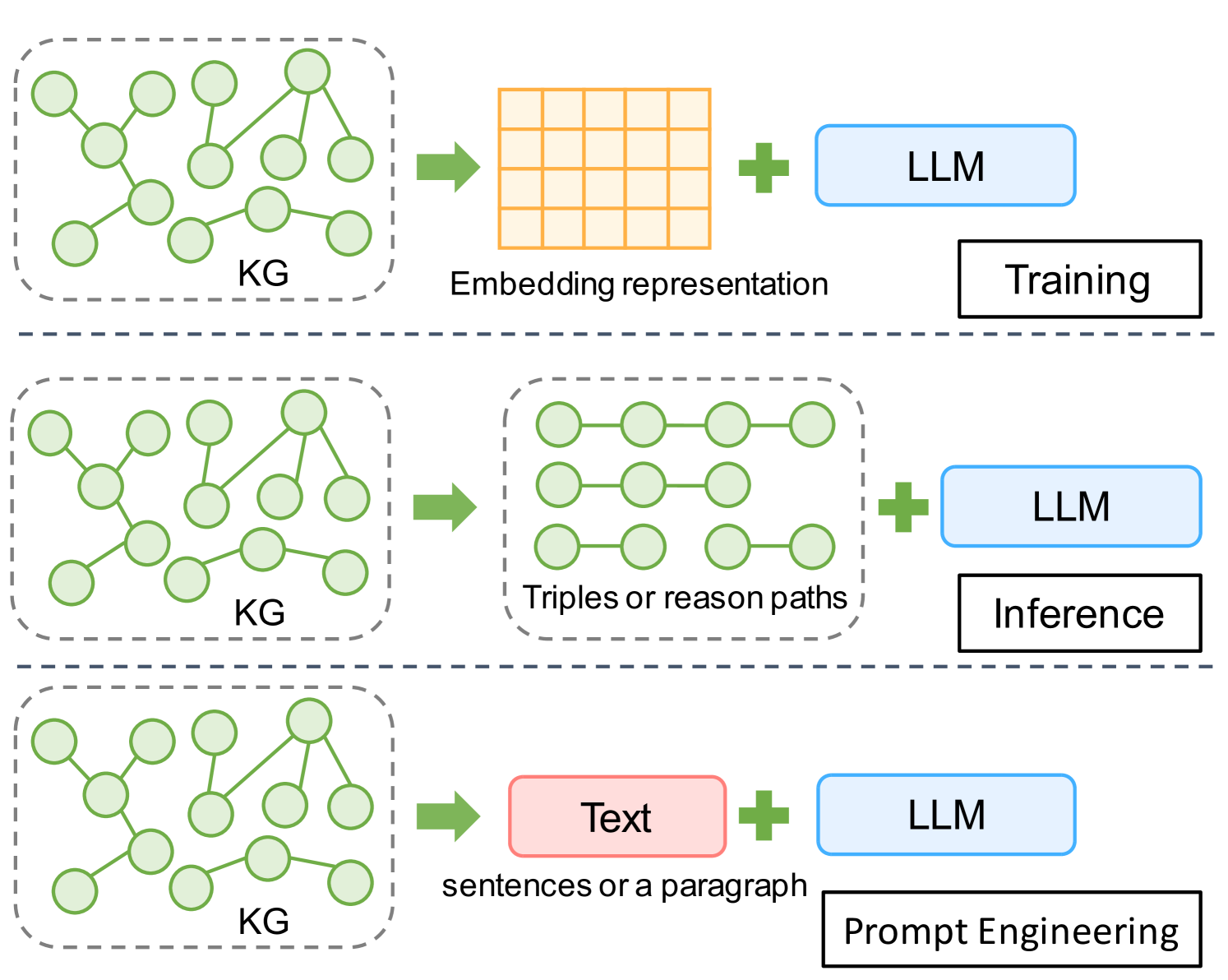
As the parameter scale of large language models (LLMs) grows, jointly training knowledge graph (KG) embeddings with model parameters to enhance LLM capabilities becomes increasingly costly. Consequently, the community has shown interest in developing prompt strategies that effectively integrate KG information into LLMs. However, the format for incorporating KGs into LLMs lacks standardization; for instance, KGs can be transformed into linearized triples or natural language (NL) text. Current prompting methods often rely on a trial-and-error approach, leaving researchers with an incomplete understanding of which KG input format best facilitates LLM comprehension of KG content. To elucidate this, we design a series of experiments to explore LLMs' understanding of different KG input formats within the context of prompt engineering. Our analysis examines both literal and attention distribution levels. Through extensive experiments, we indicate a counter-intuitive phenomenon: when addressing fact-related questions, unordered linearized triples are more effective for LLMs' understanding of KGs compared to fluent NL text. Furthermore, noisy, incomplete, or marginally relevant subgraphs can still enhance LLM performance. Finally, different LLMs have distinct preferences for different formats of organizing unordered triples.
6/18/2024
Reasoning on Efficient Knowledge Paths:Knowledge Graph Guides Large Language Model for Domain Question Answering
Yuqi Wang, Boran Jiang, Yi Luo, Dawei He, Peng Cheng, Liangcai Gao
0
0
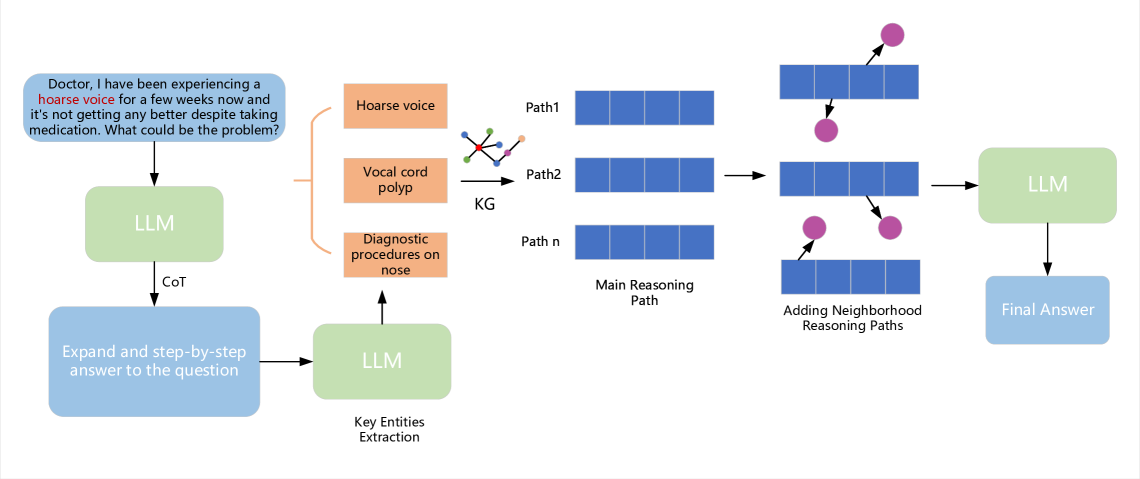
Large language models (LLMs), such as GPT3.5, GPT4 and LLAMA2 perform surprisingly well and outperform human experts on many tasks. However, in many domain-specific evaluations, these LLMs often suffer from hallucination problems due to insufficient training of relevant corpus. Furthermore, fine-tuning large models may face problems such as the LLMs are not open source or the construction of high-quality domain instruction is difficult. Therefore, structured knowledge databases such as knowledge graph can better provide domain back- ground knowledge for LLMs and make full use of the reasoning and analysis capabilities of LLMs. In some previous works, LLM was called multiple times to determine whether the current triplet was suitable for inclusion in the subgraph when retrieving subgraphs through a question. Especially for the question that require a multi-hop reasoning path, frequent calls to LLM will consume a lot of computing power. Moreover, when choosing the reasoning path, LLM will be called once for each step, and if one of the steps is selected incorrectly, it will lead to the accumulation of errors in the following steps. In this paper, we integrated and optimized a pipeline for selecting reasoning paths from KG based on LLM, which can reduce the dependency on LLM. In addition, we propose a simple and effective subgraph retrieval method based on chain of thought (CoT) and page rank which can returns the paths most likely to contain the answer. We conduct experiments on three datasets: GenMedGPT-5k [14], WebQuestions [2], and CMCQA [21]. Finally, RoK can demonstrate that using fewer LLM calls can achieve the same results as previous SOTAs models.
4/17/2024
🌀
An Enhanced Prompt-Based LLM Reasoning Scheme via Knowledge Graph-Integrated Collaboration
Yihao Li, Ru Zhang, Jianyi Liu
0
0
While Large Language Models (LLMs) demonstrate exceptional performance in a multitude of Natural Language Processing (NLP) tasks, they encounter challenges in practical applications, including issues with hallucinations, inadequate knowledge updating, and limited transparency in the reasoning process. To overcome these limitations, this study innovatively proposes a collaborative training-free reasoning scheme involving tight cooperation between Knowledge Graph (KG) and LLMs. This scheme first involves using LLMs to iteratively explore KG, selectively retrieving a task-relevant knowledge subgraph to support reasoning. The LLMs are then guided to further combine inherent implicit knowledge to reason on the subgraph while explicitly elucidating the reasoning process. Through such a cooperative approach, our scheme achieves more reliable knowledge-based reasoning and facilitates the tracing of the reasoning results. Experimental results show that our scheme significantly progressed across multiple datasets, notably achieving over a 10% improvement on the QALD10 dataset compared to the best baseline and the fine-tuned state-of-the-art (SOTA) work. Building on this success, this study hopes to offer a valuable reference for future research in the fusion of KG and LLMs, thereby enhancing LLMs' proficiency in solving complex issues.
6/13/2024
Enhancing Question Answering for Enterprise Knowledge Bases using Large Language Models
Feihu Jiang, Chuan Qin, Kaichun Yao, Chuyu Fang, Fuzhen Zhuang, Hengshu Zhu, Hui Xiong
0
0
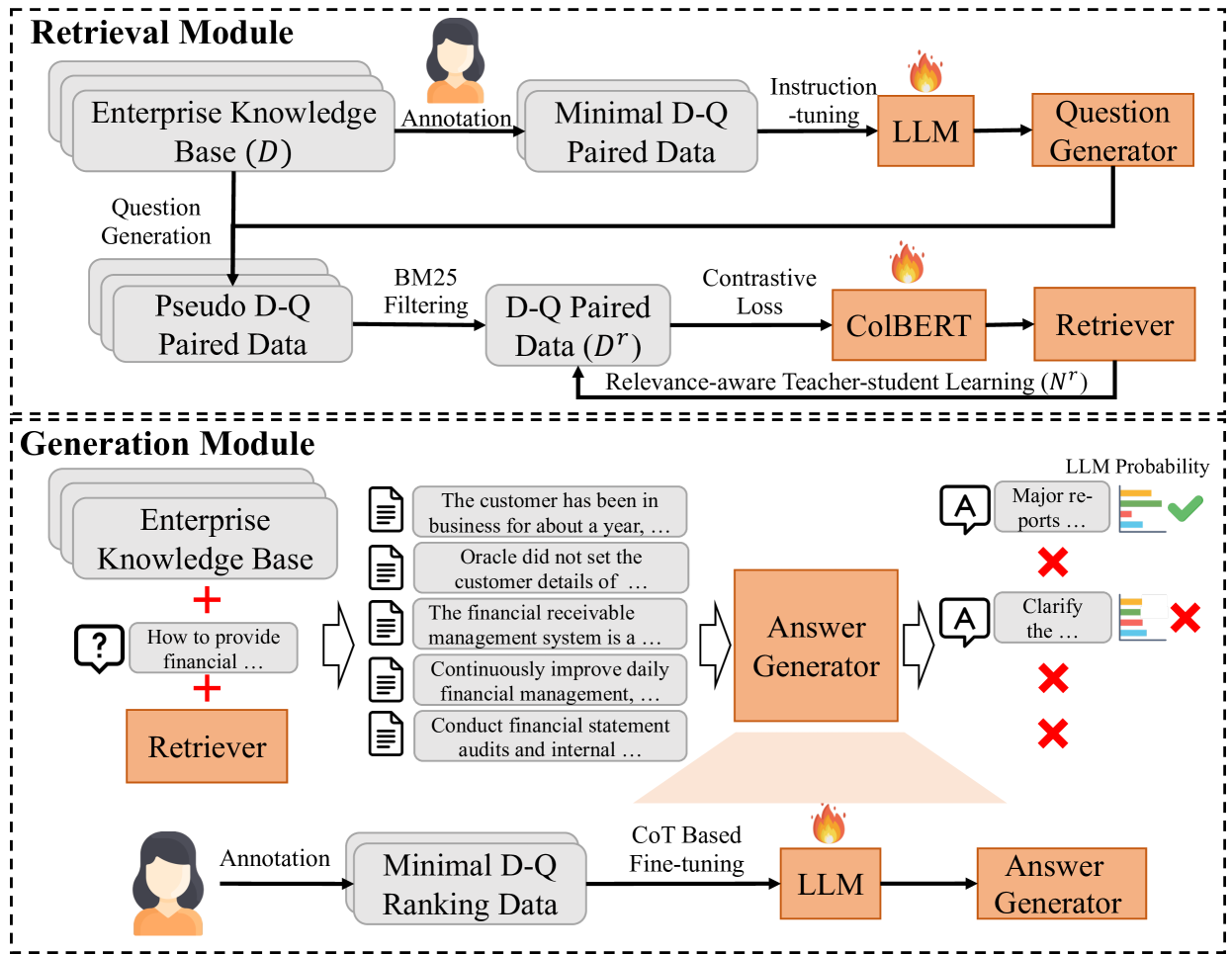
Efficient knowledge management plays a pivotal role in augmenting both the operational efficiency and the innovative capacity of businesses and organizations. By indexing knowledge through vectorization, a variety of knowledge retrieval methods have emerged, significantly enhancing the efficacy of knowledge management systems. Recently, the rapid advancements in generative natural language processing technologies paved the way for generating precise and coherent answers after retrieving relevant documents tailored to user queries. However, for enterprise knowledge bases, assembling extensive training data from scratch for knowledge retrieval and generation is a formidable challenge due to the privacy and security policies of private data, frequently entailing substantial costs. To address the challenge above, in this paper, we propose EKRG, a novel Retrieval-Generation framework based on large language models (LLMs), expertly designed to enable question-answering for Enterprise Knowledge bases with limited annotation costs. Specifically, for the retrieval process, we first introduce an instruction-tuning method using an LLM to generate sufficient document-question pairs for training a knowledge retriever. This method, through carefully designed instructions, efficiently generates diverse questions for enterprise knowledge bases, encompassing both fact-oriented and solution-oriented knowledge. Additionally, we develop a relevance-aware teacher-student learning strategy to further enhance the efficiency of the training process. For the generation process, we propose a novel chain of thought (CoT) based fine-tuning method to empower the LLM-based generator to adeptly respond to user questions using retrieved documents. Finally, extensive experiments on real-world datasets have demonstrated the effectiveness of our proposed framework.
4/23/2024