GS-LRM: Large Reconstruction Model for 3D Gaussian Splatting

0
📈
Sign in to get full access
Overview
- Proposes a scalable large reconstruction model (GS-LRM) that can quickly predict high-quality 3D Gaussian primitives from 2-4 sparse input images
- GS-LRM uses a simple transformer-based architecture to process the input images and directly decode per-pixel Gaussian parameters
- Outperforms state-of-the-art baselines on both object and scene reconstruction tasks
Plain English Explanation
GS-LRM is a new machine learning model that can quickly create high-quality 3D reconstructions from just a few 2D photos. Unlike previous models that could only reconstruct individual objects, GS-LRM can handle complex scenes with varying scales by predicting a Gaussian primitive for each pixel.
The key idea is to use a transformer-based neural network architecture. The input photos are first broken up into small patches, which are then fed into a sequence of transformer blocks. This allows the model to understand the relationships between different parts of the images. The final output is a set of Gaussian parameters for each pixel, which can be used to render a 3D reconstruction.
The researchers show that GS-LRM outperforms other state-of-the-art 3D reconstruction models on both object-level and scene-level datasets. This demonstrates the flexibility and power of the approach. They also discuss how GS-LRM could be used in downstream tasks like 3D generation.
Technical Explanation
GS-LRM uses a simple transformer-based architecture to process the input 2-4 posed images and predict high-quality 3D Gaussian primitives. The input images are first "patchified" by dividing them into small spatial regions. These image patches are then concatenated with position encodings and passed through a sequence of transformer blocks.
The transformer blocks allow the model to understand the relationships between different parts of the input images. Finally, the model directly decodes per-pixel Gaussian parameters from the output tokens of the transformer. This differentiable rendering approach enables efficient 3D reconstruction without the need for an explicit 3D representation.
The researchers evaluate GS-LRM on both object-level (Objaverse) and scene-level (RealEstate10K) datasets. They show that GS-LRM significantly outperforms previous large reconstruction models (LRMs) and other baselines in terms of reconstruction quality. GS-LRM can also run at interactive speeds, taking only 0.23 seconds on a single A100 GPU.
Critical Analysis
The key innovation of GS-LRM is its ability to handle scenes with large variations in scale and complexity by predicting per-pixel Gaussian primitives. This is a significant advance over previous LRMs, which were limited to reconstructing individual objects.
However, the paper does not extensively discuss the limitations of the approach. For example, it's unclear how well GS-LRM would perform on more challenging scenes with occlusions, dynamic elements, or fine-grained details. Additionally, the paper focuses on reconstruction quality and speed, but does not explore the potential downstream applications of the predicted Gaussian primitives beyond 3D generation.
Further research could investigate the robustness of GS-LRM to more complex scenes, as well as explore novel use cases for the Gaussian representation, such as in SLAM or dense visual SLAM systems. Additionally, the performance of GS-LRM on larger-scale city-level reconstructions could be an interesting area for future work.
Conclusion
GS-LRM is a promising new 3D reconstruction model that can quickly predict high-quality Gaussian primitives from just a few input images. By using a simple transformer-based architecture and a differentiable rendering approach, the model is able to handle complex scenes with varying scales, outperforming previous state-of-the-art methods.
While the paper focuses on reconstruction quality and speed, further research could explore the robustness of the approach and investigate novel applications of the Gaussian representation. Overall, GS-LRM represents an exciting step forward in the field of large-scale 3D reconstruction.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
0
GS-LRM: Large Reconstruction Model for 3D Gaussian Splatting
Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, Zexiang Xu
We propose GS-LRM, a scalable large reconstruction model that can predict high-quality 3D Gaussian primitives from 2-4 posed sparse images in 0.23 seconds on single A100 GPU. Our model features a very simple transformer-based architecture; we patchify input posed images, pass the concatenated multi-view image tokens through a sequence of transformer blocks, and decode final per-pixel Gaussian parameters directly from these tokens for differentiable rendering. In contrast to previous LRMs that can only reconstruct objects, by predicting per-pixel Gaussians, GS-LRM naturally handles scenes with large variations in scale and complexity. We show that our model can work on both object and scene captures by training it on Objaverse and RealEstate10K respectively. In both scenarios, the models outperform state-of-the-art baselines by a wide margin. We also demonstrate applications of our model in downstream 3D generation tasks. Our project webpage is available at: https://sai-bi.github.io/project/gs-lrm/ .
Read more5/1/2024
0
GeoLRM: Geometry-Aware Large Reconstruction Model for High-Quality 3D Gaussian Generation
Chubin Zhang, Hongliang Song, Yi Wei, Yu Chen, Jiwen Lu, Yansong Tang
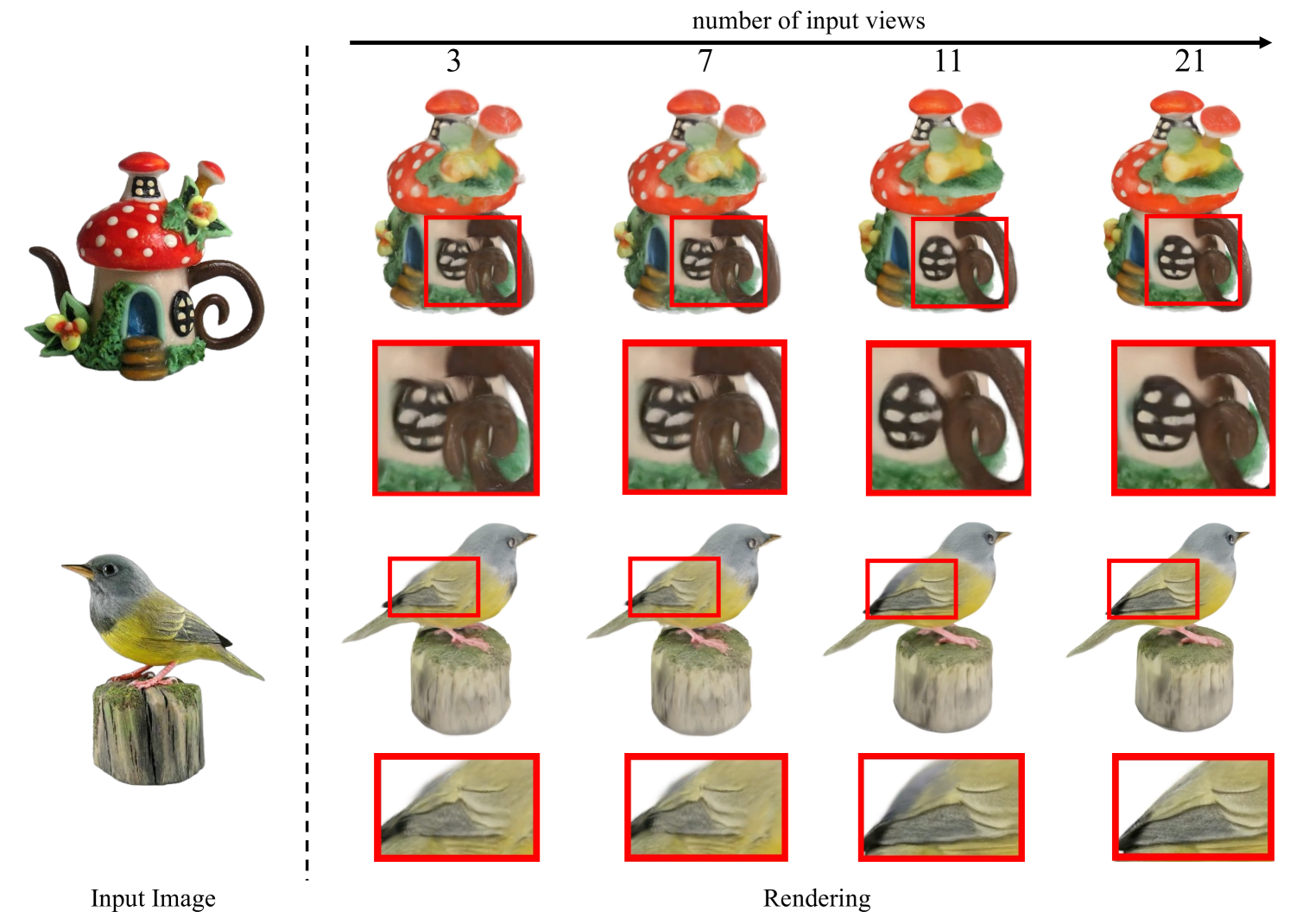
In this work, we introduce the Geometry-Aware Large Reconstruction Model (GeoLRM), an approach which can predict high-quality assets with 512k Gaussians and 21 input images in only 11 GB GPU memory. Previous works neglect the inherent sparsity of 3D structure and do not utilize explicit geometric relationships between 3D and 2D images. This limits these methods to a low-resolution representation and makes it difficult to scale up to the dense views for better quality. GeoLRM tackles these issues by incorporating a novel 3D-aware transformer structure that directly processes 3D points and uses deformable cross-attention mechanisms to effectively integrate image features into 3D representations. We implement this solution through a two-stage pipeline: initially, a lightweight proposal network generates a sparse set of 3D anchor points from the posed image inputs; subsequently, a specialized reconstruction transformer refines the geometry and retrieves textural details. Extensive experimental results demonstrate that GeoLRM significantly outperforms existing models, especially for dense view inputs. We also demonstrate the practical applicability of our model with 3D generation tasks, showcasing its versatility and potential for broader adoption in real-world applications.
Read more6/24/2024

0
LI-GS: Gaussian Splatting with LiDAR Incorporated for Accurate Large-Scale Reconstruction
Changjian Jiang, Ruilan Gao, Kele Shao, Yue Wang, Rong Xiong, Yu Zhang
Large-scale 3D reconstruction is critical in the field of robotics, and the potential of 3D Gaussian Splatting (3DGS) for achieving accurate object-level reconstruction has been demonstrated. However, ensuring geometric accuracy in outdoor and unbounded scenes remains a significant challenge. This study introduces LI-GS, a reconstruction system that incorporates LiDAR and Gaussian Splatting to enhance geometric accuracy in large-scale scenes. 2D Gaussain surfels are employed as the map representation to enhance surface alignment. Additionally, a novel modeling method is proposed to convert LiDAR point clouds to plane-constrained multimodal Gaussian Mixture Models (GMMs). The GMMs are utilized during both initialization and optimization stages to ensure sufficient and continuous supervision over the entire scene while mitigating the risk of over-fitting. Furthermore, GMMs are employed in mesh extraction to eliminate artifacts and improve the overall geometric quality. Experiments demonstrate that our method outperforms state-of-the-art methods in large-scale 3D reconstruction, achieving higher accuracy compared to both LiDAR-based methods and Gaussian-based methods with improvements of 52.6% and 68.7%, respectively.
Read more9/20/2024

0
L4GM: Large 4D Gaussian Reconstruction Model
Jiawei Ren, Kevin Xie, Ashkan Mirzaei, Hanxue Liang, Xiaohui Zeng, Karsten Kreis, Ziwei Liu, Antonio Torralba, Sanja Fidler, Seung Wook Kim, Huan Ling
We present L4GM, the first 4D Large Reconstruction Model that produces animated objects from a single-view video input -- in a single feed-forward pass that takes only a second. Key to our success is a novel dataset of multiview videos containing curated, rendered animated objects from Objaverse. This dataset depicts 44K diverse objects with 110K animations rendered in 48 viewpoints, resulting in 12M videos with a total of 300M frames. We keep our L4GM simple for scalability and build directly on top of LGM, a pretrained 3D Large Reconstruction Model that outputs 3D Gaussian ellipsoids from multiview image input. L4GM outputs a per-frame 3D Gaussian Splatting representation from video frames sampled at a low fps and then upsamples the representation to a higher fps to achieve temporal smoothness. We add temporal self-attention layers to the base LGM to help it learn consistency across time, and utilize a per-timestep multiview rendering loss to train the model. The representation is upsampled to a higher framerate by training an interpolation model which produces intermediate 3D Gaussian representations. We showcase that L4GM that is only trained on synthetic data generalizes extremely well on in-the-wild videos, producing high quality animated 3D assets.
Read more6/18/2024