MeshLRM: Large Reconstruction Model for High-Quality Mesh
2404.12385
0
0
📈
Abstract
We propose MeshLRM, a novel LRM-based approach that can reconstruct a high-quality mesh from merely four input images in less than one second. Different from previous large reconstruction models (LRMs) that focus on NeRF-based reconstruction, MeshLRM incorporates differentiable mesh extraction and rendering within the LRM framework. This allows for end-to-end mesh reconstruction by fine-tuning a pre-trained NeRF LRM with mesh rendering. Moreover, we improve the LRM architecture by simplifying several complex designs in previous LRMs. MeshLRM's NeRF initialization is sequentially trained with low- and high-resolution images; this new LRM training strategy enables significantly faster convergence and thereby leads to better quality with less compute. Our approach achieves state-of-the-art mesh reconstruction from sparse-view inputs and also allows for many downstream applications, including text-to-3D and single-image-to-3D generation. Project page: https://sarahweiii.github.io/meshlrm/
Get summaries of the top AI research delivered straight to your inbox:
Overview
- Proposes MeshLRM, a novel approach that can reconstruct high-quality 3D meshes from just 4 input images in under a second
- Differs from previous large reconstruction models (LRMs) by incorporating differentiable mesh extraction and rendering into the LRM framework
- Simplifies the LRM architecture and uses a new training strategy for faster convergence and better quality with less compute
- Achieves state-of-the-art mesh reconstruction from sparse-view inputs and enables downstream applications like text-to-3D and single-image-to-3D generation
Plain English Explanation
The researchers present a new method called MeshLRM that can quickly create detailed 3D mesh models from just a few photographs. Unlike previous large reconstruction models (LRMs) that focus on NeRF-based reconstruction, MeshLRM integrates the process of extracting a 3D mesh and rendering it directly into the LRM framework. This allows the model to be trained end-to-end to reconstruct high-quality meshes.
Additionally, the researchers simplified the LRM architecture and used a new training approach. They first train the model on low-resolution images, then fine-tune it on higher-resolution images. This new strategy enables the model to converge much faster and produce better results using less computational power.
The end result is a system that can generate detailed 3D mesh models from just 4 input photos in less than a second. This fast and efficient mesh reconstruction opens up new possibilities, like automatically converting text or single images into 3D content.
Technical Explanation
MeshLRM builds on the success of large reconstruction models (LRMs) for 3D reconstruction, but with a key difference. Rather than focusing solely on neural radiance field (NeRF) reconstruction like previous LRMs, MeshLRM incorporates differentiable mesh extraction and rendering directly into the LRM framework.
This end-to-end mesh reconstruction approach allows MeshLRM to fine-tune a pre-trained NeRF LRM to output high-quality 3D meshes. The researchers also simplified several complex design elements found in prior LRMs, streamlining the overall architecture.
Additionally, MeshLRM uses a new training strategy. It first trains the NeRF initialization on low-resolution images, then fine-tunes the model on higher-resolution inputs. This sequential training approach leads to significantly faster convergence and better reconstruction quality, all while using less computational resources.
The end result is a system that can produce state-of-the-art 3D mesh reconstructions from just 4 input images in less than a second. This fast and efficient mesh generation enables exciting downstream applications, such as text-to-3D and single-image-to-3D content creation.
Critical Analysis
The MeshLRM approach represents an impressive advance in 3D mesh reconstruction from sparse-view inputs. By integrating mesh extraction and rendering directly into the LRM framework, the researchers have created a highly efficient system that can produce high-quality results much faster than previous methods.
However, the paper does not delve into potential limitations or caveats of the MeshLRM approach. For example, it's unclear how the method would handle more complex, irregular mesh topologies, or how it might perform on very challenging or occluded scenes.
Additionally, while the researchers highlight the potential for applications like text-to-3D and single-image-to-3D generation, the paper does not provide any concrete examples or evaluations of these downstream use cases. Further exploration and validation of these applications would help strengthen the overall contribution.
Overall, MeshLRM is a promising advance in efficient 3D mesh reconstruction. But a more thorough discussion of the approach's limitations and extension to broader applications would help readers assess the true significance and potential impact of this research.
Conclusion
The MeshLRM system presented in this paper represents an exciting step forward in the field of 3D reconstruction. By seamlessly integrating mesh extraction and rendering into a large reconstruction model, the researchers have created a fast and efficient method for generating high-quality 3D meshes from just a few input images.
The key innovations, including the simplified LRM architecture and the sequential training strategy, enable MeshLRM to produce state-of-the-art results with significantly less computational resources. This efficiency opens up new possibilities for applications like text-to-3D and single-image-to-3D content creation, which could have a transformative impact on fields like art, design, and education.
While the paper could benefit from a more in-depth exploration of potential limitations and broader applications, MeshLRM clearly demonstrates the power of rethinking and optimizing the 3D reconstruction pipeline. This research represents an important advance that is sure to inspire further innovations in this rapidly evolving field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
GS-LRM: Large Reconstruction Model for 3D Gaussian Splatting
Kai Zhang, Sai Bi, Hao Tan, Yuanbo Xiangli, Nanxuan Zhao, Kalyan Sunkavalli, Zexiang Xu
0
0
We propose GS-LRM, a scalable large reconstruction model that can predict high-quality 3D Gaussian primitives from 2-4 posed sparse images in 0.23 seconds on single A100 GPU. Our model features a very simple transformer-based architecture; we patchify input posed images, pass the concatenated multi-view image tokens through a sequence of transformer blocks, and decode final per-pixel Gaussian parameters directly from these tokens for differentiable rendering. In contrast to previous LRMs that can only reconstruct objects, by predicting per-pixel Gaussians, GS-LRM naturally handles scenes with large variations in scale and complexity. We show that our model can work on both object and scene captures by training it on Objaverse and RealEstate10K respectively. In both scenarios, the models outperform state-of-the-art baselines by a wide margin. We also demonstrate applications of our model in downstream 3D generation tasks. Our project webpage is available at: https://sai-bi.github.io/project/gs-lrm/ .
5/1/2024
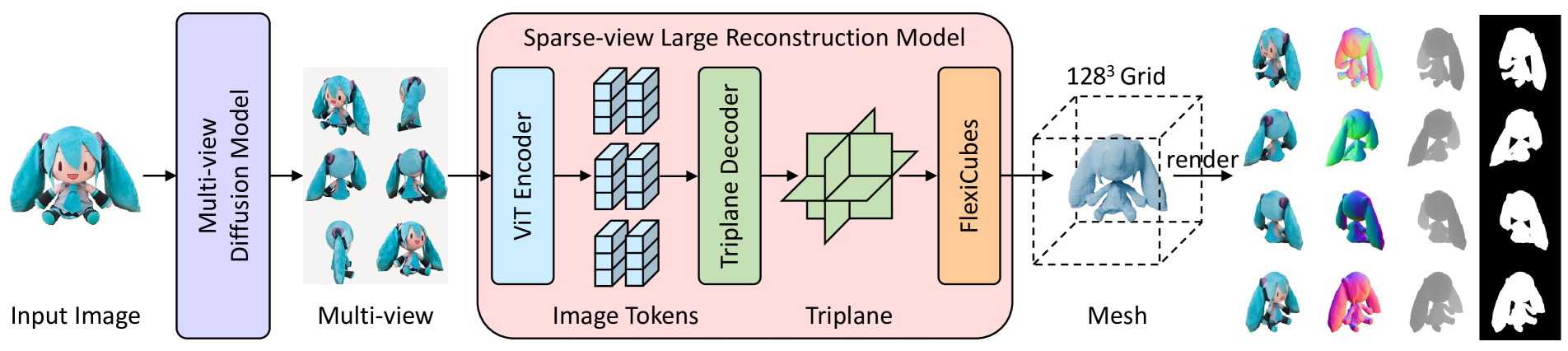
InstantMesh: Efficient 3D Mesh Generation from a Single Image with Sparse-view Large Reconstruction Models
Jiale Xu, Weihao Cheng, Yiming Gao, Xintao Wang, Shenghua Gao, Ying Shan
0
0
We present InstantMesh, a feed-forward framework for instant 3D mesh generation from a single image, featuring state-of-the-art generation quality and significant training scalability. By synergizing the strengths of an off-the-shelf multiview diffusion model and a sparse-view reconstruction model based on the LRM architecture, InstantMesh is able to create diverse 3D assets within 10 seconds. To enhance the training efficiency and exploit more geometric supervisions, e.g, depths and normals, we integrate a differentiable iso-surface extraction module into our framework and directly optimize on the mesh representation. Experimental results on public datasets demonstrate that InstantMesh significantly outperforms other latest image-to-3D baselines, both qualitatively and quantitatively. We release all the code, weights, and demo of InstantMesh, with the intention that it can make substantial contributions to the community of 3D generative AI and empower both researchers and content creators.
4/16/2024
🧠
CuNeRF: Cube-Based Neural Radiance Field for Zero-Shot Medical Image Arbitrary-Scale Super Resolution
Zixuan Chen, Jian-Huang Lai, Lingxiao Yang, Xiaohua Xie
0
0
Medical image arbitrary-scale super-resolution (MIASSR) has recently gained widespread attention, aiming to super sample medical volumes at arbitrary scales via a single model. However, existing MIASSR methods face two major limitations: (i) reliance on high-resolution (HR) volumes and (ii) limited generalization ability, which restricts their application in various scenarios. To overcome these limitations, we propose Cube-based Neural Radiance Field (CuNeRF), a zero-shot MIASSR framework that can yield medical images at arbitrary scales and viewpoints in a continuous domain. Unlike existing MIASSR methods that fit the mapping between low-resolution (LR) and HR volumes, CuNeRF focuses on building a coordinate-intensity continuous representation from LR volumes without the need for HR references. This is achieved by the proposed differentiable modules: including cube-based sampling, isotropic volume rendering, and cube-based hierarchical rendering. Through extensive experiments on magnetic resource imaging (MRI) and computed tomography (CT) modalities, we demonstrate that CuNeRF outperforms state-of-the-art MIASSR methods. CuNeRF yields better visual verisimilitude and reduces aliasing artifacts at various upsampling factors. Moreover, our CuNeRF does not need any LR-HR training pairs, which is more flexible and easier to be used than others. Our code is released at https://github.com/NarcissusEx/CuNeRF.
4/17/2024

DistGrid: Scalable Scene Reconstruction with Distributed Multi-resolution Hash Grid
Sidun Liu, Peng Qiao, Zongxin Ye, Wenyu Li, Yong Dou
0
0
Neural Radiance Field~(NeRF) achieves extremely high quality in object-scaled and indoor scene reconstruction. However, there exist some challenges when reconstructing large-scale scenes. MLP-based NeRFs suffer from limited network capacity, while volume-based NeRFs are heavily memory-consuming when the scene resolution increases. Recent approaches propose to geographically partition the scene and learn each sub-region using an individual NeRF. Such partitioning strategies help volume-based NeRF exceed the single GPU memory limit and scale to larger scenes. However, this approach requires multiple background NeRF to handle out-of-partition rays, which leads to redundancy of learning. Inspired by the fact that the background of current partition is the foreground of adjacent partition, we propose a scalable scene reconstruction method based on joint Multi-resolution Hash Grids, named DistGrid. In this method, the scene is divided into multiple closely-paved yet non-overlapped Axis-Aligned Bounding Boxes, and a novel segmented volume rendering method is proposed to handle cross-boundary rays, thereby eliminating the need for background NeRFs. The experiments demonstrate that our method outperforms existing methods on all evaluated large-scale scenes, and provides visually plausible scene reconstruction. The scalability of our method on reconstruction quality is further evaluated qualitatively and quantitatively.
5/9/2024