GUIDE: Graphical User Interface Data for Execution

0
📊
Sign in to get full access
Overview
- Introduces a new dataset called GUIDE designed for Multimodal Large Language Model (MLLM) applications, particularly for Robotic Process Automation (RPA) use cases
- The dataset includes diverse data from various websites like Apollo, Gmail, Calendar, and Canva
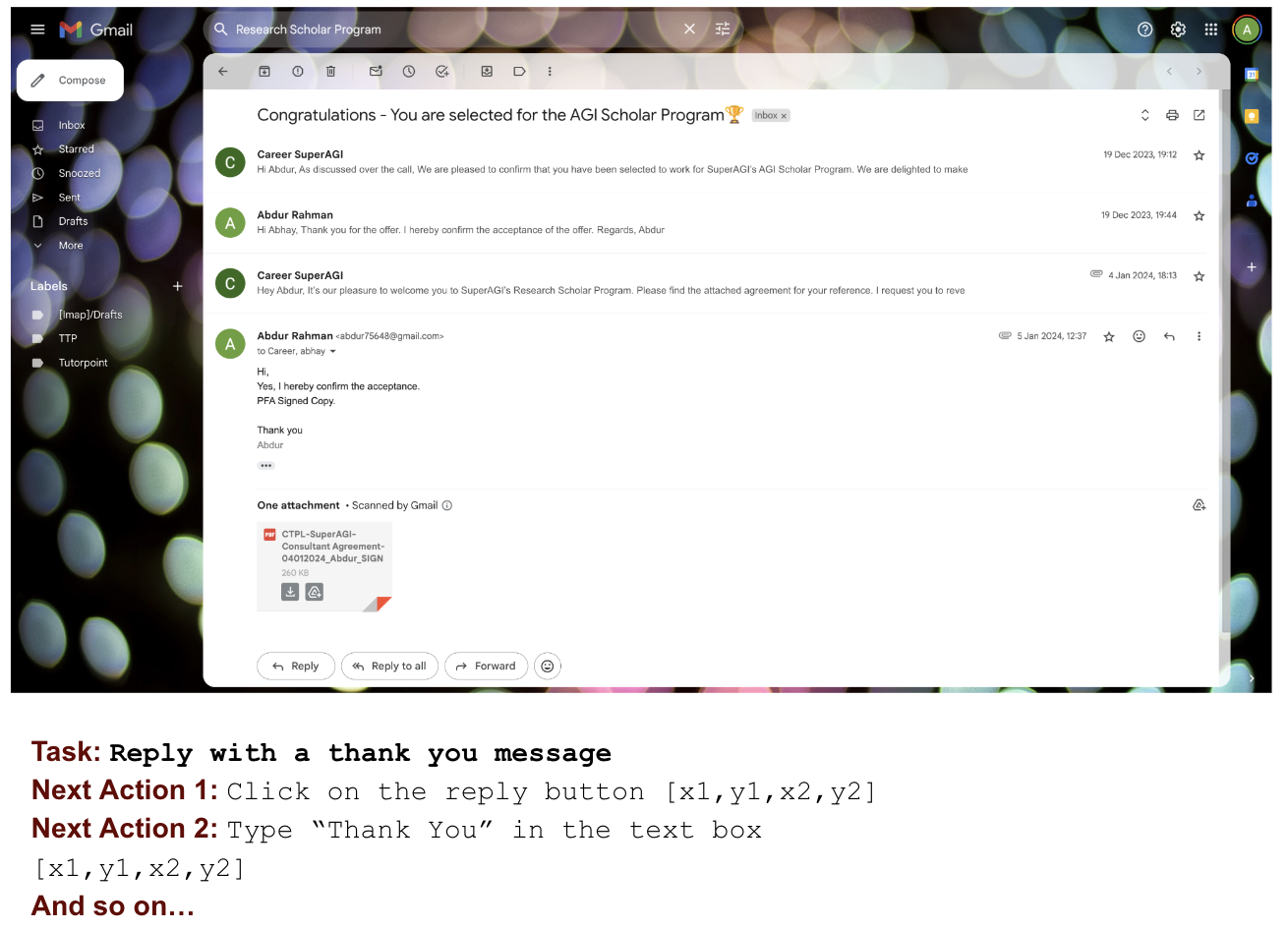
- Each data entry includes an image, task description, last action taken, Chain of Thought (CoT), and the next action to be performed, along with grounding information
- The data is collected using an in-house annotation tool called NEXTAG and is adapted for multiple operating systems, browsers, and display types
- The goal is to facilitate research and development in the realm of LLMs for graphical user interfaces, particularly in RPA tasks
Plain English Explanation
The researchers have created a new dataset called GUIDE that is designed to help advance the development of Multimodal Large Language Models (MLLMs) - a type of AI system that can understand and interact with both text and visual information. The primary focus of this dataset is on Robotic Process Automation (RPA) - a technology that allows computers to automate repetitive tasks on websites and applications.
The GUIDE dataset includes a diverse range of data collected from various popular websites such as Apollo, Gmail, Calendar, and Canva. Each entry in the dataset includes an image of a website or application, a description of the task, the last action taken by the user, a "Chain of Thought" (a step-by-step explanation of how to complete the task), and the next action that should be performed. This information is designed to help train AI systems to understand the context and flow of tasks on different platforms.
The researchers used an in-house tool called NEXTAG to collect and annotate the data, ensuring that it is compatible with multiple operating systems, browsers, and display types. This multi-platform nature of the dataset is intended to enable the exploration of cross-interface capabilities in automation tasks, which could lead to more robust and versatile RPA solutions.
By making this GUIDE dataset available to the research community, the researchers hope to spur further advancements in the field of large language models for graphical user interfaces and voice-based user interfaces. This could potentially lead to more powerful and user-friendly automation tools that can operate seamlessly across a wide range of platforms and applications.
Technical Explanation
The researchers introduce a novel dataset called GUIDE (Graphical User Interface Dataset for Exploration) that is specifically designed to advance the development of Multimodal Large Language Models (MLLMs) for Robotic Process Automation (RPA) use cases. The dataset encompasses diverse data from various websites, including Apollo (62.67%), Gmail (3.43%), Calendar (10.98%), and Canva (22.92%).
Each data entry in the GUIDE dataset includes an image of the website or application, a task description, the last action taken by the user, a Chain of Thought (CoT) explaining the steps to complete the task, and the next action to be performed, along with grounding information on where the action needs to be executed. The data is collected using an in-house advanced annotation tool called NEXTAG (Next Action Grounding and Annotation Tool).
The dataset is designed to be adaptable for multiple operating systems, browsers, and display types, and it is collected by multiple annotators to capture the variation in website design and user interaction. This multi-platform nature and coverage of diverse websites enable the exploration of cross-interface capabilities in automation tasks.
By providing this GUIDE dataset, the researchers aim to facilitate research and development in the realm of large language models for graphical user interfaces, particularly in tasks related to RPA. The dataset is intended to serve as a valuable resource for advancing the capabilities of multi-platform LLMs in practical applications, fostering innovation in the field of automation and natural language understanding.
The researchers have also built a model called V-Zen, which is the first RPA model to automate multiple websites using their in-house automation tool, AUTONODE. The V-Zen model is developed and evaluated using the GUIDE dataset, demonstrating its potential for practical applications.
Critical Analysis
The researchers have made a commendable effort in creating the GUIDE dataset, which appears to be a valuable resource for advancing research in the field of Multimodal Large Language Models (MLLMs) and Robotic Process Automation (RPA). The dataset's multi-platform nature and coverage of diverse websites are particularly noteworthy, as they enable the exploration of cross-interface capabilities in automation tasks.
One potential limitation of the dataset is the uneven distribution of data across different websites, with Apollo accounting for the majority (62.67%) and other platforms like Gmail and Calendar representing smaller portions. While this may reflect the researchers' focus on certain use cases, it could potentially limit the generalizability of models trained on the dataset.
Additionally, the paper does not provide detailed information on the annotation process, the quality control measures, or the potential biases in the dataset. It would be beneficial for future research if the authors could offer more transparency and insights into these aspects of the data collection and curation.
Furthermore, the paper does not discuss the performance or limitations of the V-Zen model, which was developed using the GUIDE dataset. It would be valuable to see a more thorough evaluation of the model's capabilities and its potential challenges, as this could provide valuable insights for other researchers working in this domain.
Despite these minor limitations, the GUIDE dataset and the V-Zen model represent a significant contribution to the field of Multimodal Large Language Models and Robotic Process Automation. The researchers' work has the potential to inspire further advancements in the development of user-friendly and cross-platform automation solutions, which could have widespread practical applications.
Conclusion
The GUIDE dataset introduced in this paper represents a valuable resource for advancing research and development in the field of Multimodal Large Language Models (MLLMs), particularly in the context of Robotic Process Automation (RPA) use cases. The dataset's diverse data from various websites, along with the detailed annotations, provide a comprehensive platform for exploring the capabilities of large language models in understanding and automating graphical user interfaces.
By making this dataset available to the research community, the authors have laid the groundwork for further advancements in the areas of cross-platform automation, natural language understanding, and the integration of visual and textual information in AI systems. The potential impact of this work extends beyond the immediate domain of RPA, as the insights gained from this research could also contribute to the broader field of human-computer interaction and user-centric design.
Overall, the GUIDE dataset and the associated V-Zen model demonstrate the researchers' commitment to driving innovation in the field of Multimodal Large Language Models and their practical applications. This work represents an important step forward in the quest to develop more intelligent and user-friendly automation tools, with the ultimate goal of empowering individuals and organizations to streamline their digital workflows and unlock new levels of productivity and efficiency.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📊
0
GUIDE: Graphical User Interface Data for Execution
Rajat Chawla, Adarsh Jha, Muskaan Kumar, Mukunda NS, Ishaan Bhola
In this paper, we introduce GUIDE, a novel dataset tailored for the advancement of Multimodal Large Language Model (MLLM) applications, particularly focusing on Robotic Process Automation (RPA) use cases. Our dataset encompasses diverse data from various websites including Apollo(62.67%), Gmail(3.43%), Calendar(10.98%) and Canva(22.92%). Each data entry includes an image, a task description, the last action taken, CoT and the next action to be performed along with grounding information of where the action needs to be executed. The data is collected using our in-house advanced annotation tool NEXTAG (Next Action Grounding and Annotation Tool). The data is adapted for multiple OS, browsers and display types. It is collected by multiple annotators to capture the variation of design and the way person uses a website. Through this dataset, we aim to facilitate research and development in the realm of LLMs for graphical user interfaces, particularly in tasks related to RPA. The dataset's multi-platform nature and coverage of diverse websites enable the exploration of cross-interface capabilities in automation tasks. We believe that our dataset will serve as a valuable resource for advancing the capabilities of multi-platform LLMs in practical applications, fostering innovation in the field of automation and natural language understanding. Using GUIDE, we build V-Zen, the first RPA model to automate multiple websites using our in-House Automation tool AUTONODE
Read more4/26/2024

0
GUI-WORLD: A Dataset for GUI-oriented Multimodal LLM-based Agents
Dongping Chen, Yue Huang, Siyuan Wu, Jingyu Tang, Liuyi Chen, Yilin Bai, Zhigang He, Chenlong Wang, Huichi Zhou, Yiqiang Li, Tianshuo Zhou, Yue Yu, Chujie Gao, Qihui Zhang, Yi Gui, Zhen Li, Yao Wan, Pan Zhou, Jianfeng Gao, Lichao Sun
Recently, Multimodal Large Language Models (MLLMs) have been used as agents to control keyboard and mouse inputs by directly perceiving the Graphical User Interface (GUI) and generating corresponding code. However, current agents primarily exhibit excellent understanding capabilities in static environments and are predominantly applied in relatively simple domains, such as Web or mobile interfaces. We argue that a robust GUI agent should be capable of perceiving temporal information on the GUI, including dynamic Web content and multi-step tasks. Additionally, it should possess a comprehensive understanding of various GUI scenarios, including desktop software and multi-window interactions. To this end, this paper introduces a new dataset, termed GUI-World, which features meticulously crafted Human-MLLM annotations, extensively covering six GUI scenarios and eight types of GUI-oriented questions in three formats. We evaluate the capabilities of current state-of-the-art MLLMs, including ImageLLMs and VideoLLMs, in understanding various types of GUI content, especially dynamic and sequential content. Our findings reveal that ImageLLMs struggle with dynamic GUI content without manually annotated keyframes or operation history. On the other hand, VideoLLMs fall short in all GUI-oriented tasks given the sparse GUI video dataset. Based on GUI-World, we take the initial step of leveraging a fine-tuned VideoLLM as a GUI agent, demonstrating an improved understanding of various GUI tasks. However, due to the limitations in the performance of base LLMs, we conclude that using VideoLLMs as GUI agents remains a significant challenge. We believe our work provides valuable insights for future research in dynamic GUI content understanding. The code and dataset are publicly available at our project homepage: https://gui-world.github.io/.
Read more6/18/2024
0
V-Zen: Efficient GUI Understanding and Precise Grounding With A Novel Multimodal LLM
Abdur Rahman, Rajat Chawla, Muskaan Kumar, Arkajit Datta, Adarsh Jha, Mukunda NS, Ishaan Bhola
In the rapidly evolving landscape of AI research and application, Multimodal Large Language Models (MLLMs) have emerged as a transformative force, adept at interpreting and integrating information from diverse modalities such as text, images, and Graphical User Interfaces (GUIs). Despite these advancements, the nuanced interaction and understanding of GUIs pose a significant challenge, limiting the potential of existing models to enhance automation levels. To bridge this gap, this paper presents V-Zen, an innovative Multimodal Large Language Model (MLLM) meticulously crafted to revolutionise the domain of GUI understanding and grounding. Equipped with dual-resolution image encoders, V-Zen establishes new benchmarks in efficient grounding and next-action prediction, thereby laying the groundwork for self-operating computer systems. Complementing V-Zen is the GUIDE dataset, an extensive collection of real-world GUI elements and task-based sequences, serving as a catalyst for specialised fine-tuning. The successful integration of V-Zen and GUIDE marks the dawn of a new era in multimodal AI research, opening the door to intelligent, autonomous computing experiences. This paper extends an invitation to the research community to join this exciting journey, shaping the future of GUI automation. In the spirit of open science, our code, data, and model will be made publicly available, paving the way for multimodal dialogue scenarios with intricate and precise interactions.
Read more7/23/2024

0
GUICourse: From General Vision Language Models to Versatile GUI Agents
Wentong Chen, Junbo Cui, Jinyi Hu, Yujia Qin, Junjie Fang, Yue Zhao, Chongyi Wang, Jun Liu, Guirong Chen, Yupeng Huo, Yuan Yao, Yankai Lin, Zhiyuan Liu, Maosong Sun
Utilizing Graphic User Interface (GUI) for human-computer interaction is essential for accessing a wide range of digital tools. Recent advancements in Vision Language Models (VLMs) highlight the compelling potential to develop versatile agents to help humans finish GUI navigation tasks. However, current VLMs are challenged in terms of fundamental abilities (OCR and grounding) and GUI knowledge (the functions and control methods of GUI elements), preventing them from becoming practical GUI agents. To solve these challenges, we contribute GUICourse, a suite of datasets to train visual-based GUI agents from general VLMs. First, we introduce the GUIEnv dataset to strengthen the OCR and grounding capabilities of VLMs. Then, we introduce the GUIAct and GUIChat datasets to enrich their knowledge of GUI components and interactions. Experiments demonstrate that our GUI agents have better performance on common GUI tasks than their baseline VLMs. Even the small-size GUI agent (with 3.1B parameters) can still work well on single-step and multi-step GUI tasks. Finally, we analyze the different varieties in the training stage of this agent by ablation study. Our source codes and datasets are released at https://github.com/yiye3/GUICourse.
Read more6/18/2024