GUIDE: Guidance-based Incremental Learning with Diffusion Models

0

Sign in to get full access
Overview
- This paper introduces GUIDE, a novel method for guidance-based incremental learning with diffusion models.
- GUIDE addresses the challenge of continual learning, where an AI system needs to learn new tasks without forgetting previous ones.
- The key idea is to use a diffusion model as the backbone and guide it with task-specific information to enable efficient incremental learning.
Plain English Explanation
Imagine you're trying to learn new skills, like learning to play the guitar after already knowing how to play the piano. It can be really hard to learn the new skill without forgetting the old one. This is a problem that AI systems also face, called "continual learning."
The researchers in this paper developed a new technique called GUIDE to help AI systems learn new tasks without forgetting the old ones. The core of their approach is using a special type of AI model called a "diffusion model" as the base. Diffusion models are good at generating new images or other data. The researchers found a way to "guide" the diffusion model with information about the specific task the AI is learning, allowing it to efficiently pick up new skills while retaining old ones.
This is an important advancement because it can help AI systems become more flexible and adaptive, allowing them to continuously learn and expand their capabilities over time, just like humans do.
Technical Explanation
The key technical contributions of this paper are:
-
Diffusion Model Backbone: The authors use a pre-trained diffusion model as the backbone of their GUIDE framework. Diffusion models are a type of generative AI model that can be used to generate new images, text, or other data by gradually adding noise to an input and then reversing the process to generate a new sample.
-
Guidance Mechanism: To enable continual learning, the authors introduce a "guidance" mechanism that conditions the diffusion model on task-specific information. This allows the model to efficiently learn new tasks without forgetting previous ones.
-
Generative Distillation: The authors propose a "generative distillation" technique to transfer knowledge from previous tasks to the new task being learned. This helps the model retain important information from past experiences.
-
Experiments: The authors evaluate GUIDE on several continual learning benchmarks and show that it outperforms existing methods in terms of performance on new tasks while maintaining high accuracy on previous tasks.
Critical Analysis
The GUIDE method presents a promising approach to addressing the challenging problem of continual learning. By leveraging the flexibility and generative capabilities of diffusion models, the authors have developed a framework that can efficiently acquire new skills while preserving past knowledge.
However, the paper does not fully address the potential limitations of this approach. For example, the authors do not discuss how GUIDE would scale to learning a large number of tasks over an extended period, or how it might handle tasks that are significantly different from the initial set of tasks. Additionally, the paper does not provide a deep analysis of the computational and memory requirements of the GUIDE framework, which could be an important consideration for real-world applications.
Further research is needed to better understand the strengths and weaknesses of the GUIDE approach, as well as to explore alternative techniques for continual learning with diffusion models. Continual learning with diffusion models, continual offline reinforcement learning, and transfer learning with diffusion models are all active areas of research that could inform and complement the GUIDE approach.
Conclusion
The GUIDE framework presented in this paper represents an important step forward in addressing the challenge of continual learning. By leveraging the capabilities of diffusion models and introducing a novel guidance mechanism, the authors have developed a technique that can enable AI systems to learn new tasks efficiently while maintaining their knowledge of previous tasks.
This work has significant implications for the development of more flexible and adaptive AI systems that can continuously expand their capabilities over time, much like humans do. As the field of continual learning continues to evolve, approaches like GUIDE will play an important role in pushing the boundaries of what is possible in artificial intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GUIDE: Guidance-based Incremental Learning with Diffusion Models
Bartosz Cywi'nski, Kamil Deja, Tomasz Trzci'nski, Bart{l}omiej Twardowski, {L}ukasz Kuci'nski
We introduce GUIDE, a novel continual learning approach that directs diffusion models to rehearse samples at risk of being forgotten. Existing generative strategies combat catastrophic forgetting by randomly sampling rehearsal examples from a generative model. Such an approach contradicts buffer-based approaches where sampling strategy plays an important role. We propose to bridge this gap by incorporating classifier guidance into the diffusion process to produce rehearsal examples specifically targeting information forgotten by a continuously trained model. This approach enables the generation of samples from preceding task distributions, which are more likely to be misclassified in the context of recently encountered classes. Our experimental results show that GUIDE significantly reduces catastrophic forgetting, outperforming conventional random sampling approaches and surpassing recent state-of-the-art methods in continual learning with generative replay.
Read more6/3/2024

0
Continual Learning of Diffusion Models with Generative Distillation
Sergi Masip, Pau Rodriguez, Tinne Tuytelaars, Gido M. van de Ven
Diffusion models are powerful generative models that achieve state-of-the-art performance in image synthesis. However, training them demands substantial amounts of data and computational resources. Continual learning would allow for incrementally learning new tasks and accumulating knowledge, thus enabling the reuse of trained models for further learning. One potentially suitable continual learning approach is generative replay, where a copy of a generative model trained on previous tasks produces synthetic data that are interleaved with data from the current task. However, standard generative replay applied to diffusion models results in a catastrophic loss in denoising capabilities. In this paper, we propose generative distillation, an approach that distils the entire reverse process of a diffusion model. We demonstrate that our approach substantially improves the continual learning performance of generative replay with only a modest increase in the computational costs.
Read more5/21/2024

0
Continual Offline Reinforcement Learning via Diffusion-based Dual Generative Replay
Jinmei Liu, Wenbin Li, Xiangyu Yue, Shilin Zhang, Chunlin Chen, Zhi Wang
We study continual offline reinforcement learning, a practical paradigm that facilitates forward transfer and mitigates catastrophic forgetting to tackle sequential offline tasks. We propose a dual generative replay framework that retains previous knowledge by concurrent replay of generated pseudo-data. First, we decouple the continual learning policy into a diffusion-based generative behavior model and a multi-head action evaluation model, allowing the policy to inherit distributional expressivity for encompassing a progressive range of diverse behaviors. Second, we train a task-conditioned diffusion model to mimic state distributions of past tasks. Generated states are paired with corresponding responses from the behavior generator to represent old tasks with high-fidelity replayed samples. Finally, by interleaving pseudo samples with real ones of the new task, we continually update the state and behavior generators to model progressively diverse behaviors, and regularize the multi-head critic via behavior cloning to mitigate forgetting. Experiments demonstrate that our method achieves better forward transfer with less forgetting, and closely approximates the results of using previous ground-truth data due to its high-fidelity replay of the sample space. Our code is available at href{https://github.com/NJU-RL/CuGRO}{https://github.com/NJU-RL/CuGRO}.
Read more4/19/2024
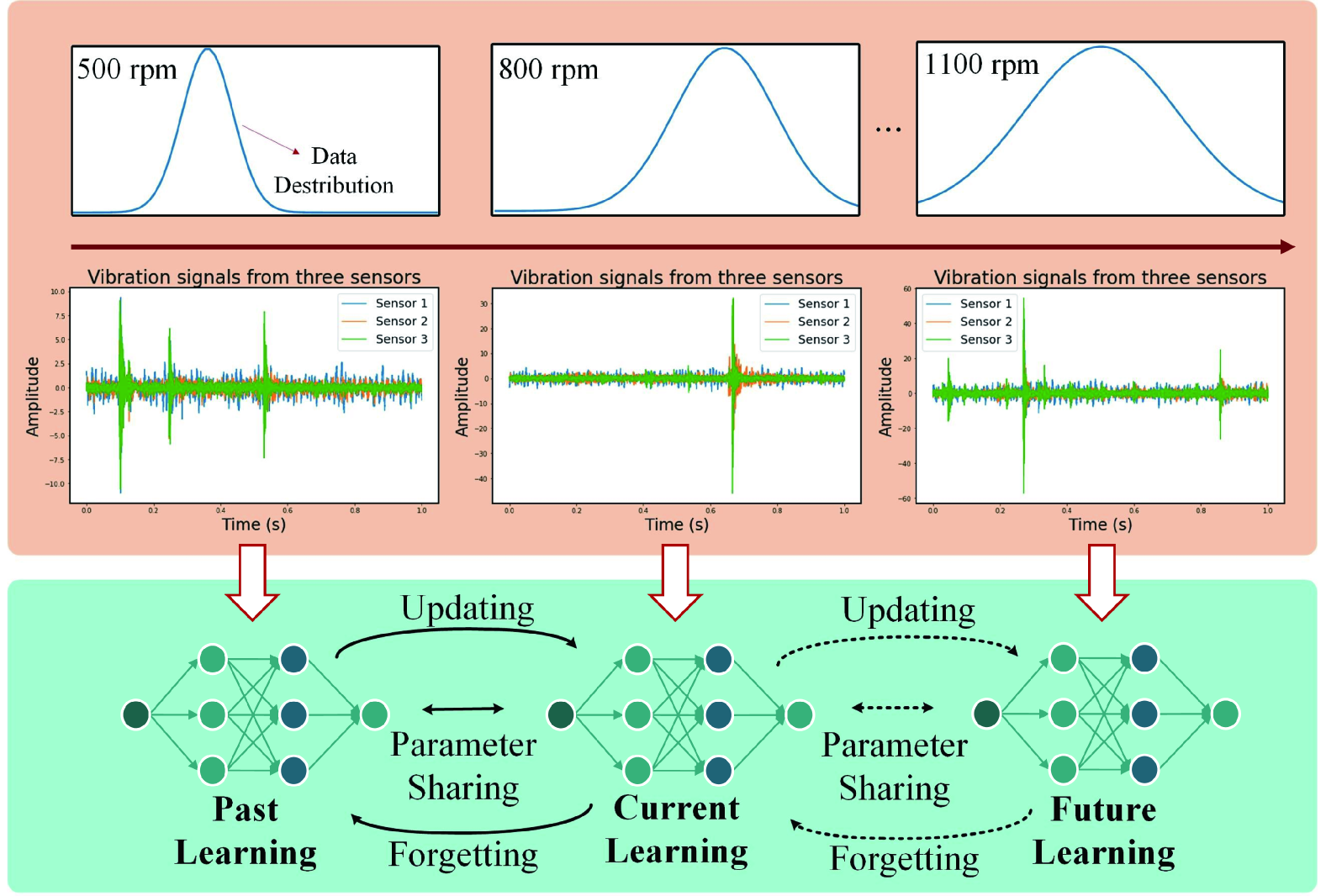
0
Continual Learning with Diffusion-based Generative Replay for Industrial Streaming Data
Jiayi He, Jiao Chen, Qianmiao Liu, Suyan Dai, Jianhua Tang, Dongpo Liu
The Industrial Internet of Things (IIoT) integrates interconnected sensors and devices to support industrial applications, but its dynamic environments pose challenges related to data drift. Considering the limited resources and the need to effectively adapt models to new data distributions, this paper introduces a Continual Learning (CL) approach, i.e., Distillation-based Self-Guidance (DSG), to address challenges presented by industrial streaming data via a novel generative replay mechanism. DSG utilizes knowledge distillation to transfer knowledge from the previous diffusion-based generator to the updated one, improving both the stability of the generator and the quality of reproduced data, thereby enhancing the mitigation of catastrophic forgetting. Experimental results on CWRU, DSA, and WISDM datasets demonstrate the effectiveness of DSG. DSG outperforms the state-of-the-art baseline in accuracy, demonstrating improvements ranging from 2.9% to 5.0% on key datasets, showcasing its potential for practical industrial applications.
Read more6/26/2024