Guided Exploration in Reinforcement Learning via Monte Carlo Critic Optimization
2206.12674
0
0
🏅
Abstract
The class of deep deterministic off-policy algorithms is effectively applied to solve challenging continuous control problems. Current approaches commonly utilize random noise as an exploration method, which has several drawbacks, including the need for manual adjustment for a given task and the absence of exploratory calibration during the training process. We address these challenges by proposing a novel guided exploration method that uses an ensemble of Monte Carlo Critics for calculating exploratory action correction. The proposed method enhances the traditional exploration scheme by dynamically adjusting exploration. Subsequently, we present a novel algorithm that leverages the proposed exploratory module for both policy and critic modification. The presented algorithm demonstrates superior performance compared to modern reinforcement learning algorithms across a variety of problems in the DMControl suite.
Create account to get full access
Overview
- The paper proposes a novel guided exploration method for deep deterministic off-policy reinforcement learning algorithms to improve their performance on continuous control problems.
- Current approaches often use random noise for exploration, which has drawbacks like the need for manual adjustment and lack of exploratory calibration during training.
- The authors address these challenges by introducing an ensemble of Monte Carlo Critics to dynamically adjust exploration.
- The authors present a new algorithm that leverages this exploratory module for both policy and critic modification, demonstrating superior performance compared to modern RL algorithms.
Plain English Explanation
Deep reinforcement learning algorithms are commonly used to solve complex continuous control problems, like robotics or self-driving car navigation. These algorithms learn how to make decisions by trial and error, exploring different actions and learning from the results.
Many current approaches use random noise as a way to explore new actions. While simple, this has some downsides. It requires manual adjustments to the level of exploration for each specific task, and the exploration process isn't optimized during training.
To address these issues, the authors propose a new "guided exploration" method. This uses an ensemble of Monte Carlo Critics to dynamically adjust the exploration, based on the algorithms' understanding of the task. This allows the exploration to be tailored to the problem, without needing manual tuning.
The authors then introduce a novel reinforcement learning algorithm that incorporates this guided exploration approach. This algorithm demonstrates better performance than other modern reinforcement learning methods across a variety of challenging continuous control tasks.
Technical Explanation
The paper focuses on deep deterministic off-policy reinforcement learning algorithms, which are effective at solving continuous control problems. The authors identify that current approaches often use random noise for exploration, which has drawbacks:
- The level of exploration needs to be manually adjusted for each task.
- The exploration process is not optimized or calibrated during the training process.
To address these challenges, the authors propose a "guided exploration" method that uses an ensemble of Monte Carlo Critics to dynamically adjust the exploration based on the algorithm's understanding of the task. This allows the exploration to be tailored to the problem at hand without requiring manual tuning.
The authors then present a novel reinforcement learning algorithm that leverages this guided exploration approach. The algorithm modifies both the policy and critic components, using the exploratory module to guide the decision-making process.
The authors evaluate their algorithm on a variety of continuous control problems from the DMControl suite, demonstrating superior performance compared to other modern reinforcement learning algorithms.
Critical Analysis
The paper presents a promising approach to improving the exploration capabilities of deep deterministic off-policy reinforcement learning algorithms. The authors' use of an ensemble of Monte Carlo Critics to dynamically adjust the exploration is an innovative solution to the drawbacks of using random noise.
However, the paper does not discuss the potential computational overhead or training time implications of the guided exploration method. Incorporating an ensemble of critics could increase the complexity and resource requirements of the algorithm, which may be a concern for real-world applications with limited computational resources.
Additionally, the paper does not provide a detailed analysis of the exploration-exploitation trade-off or the convergence properties of the proposed algorithm. Further research may be needed to understand the theoretical guarantees and limitations of the method, especially in the context of constrained optimization problems.
Overall, the paper presents an interesting and promising approach to improving exploration in deep deterministic off-policy reinforcement learning. The guided exploration method and the novel algorithm developed by the authors warrant further investigation and testing on a wider range of continuous control problems.
Conclusion
The paper addresses a key challenge in deep deterministic off-policy reinforcement learning algorithms: the need for effective exploration strategies to solve complex continuous control problems. The authors propose a novel guided exploration method that uses an ensemble of Monte Carlo Critics to dynamically adjust the exploration, overcoming the limitations of current approaches that rely on random noise.
The authors' novel algorithm, which incorporates the guided exploration module, demonstrates superior performance compared to other modern reinforcement learning algorithms across a variety of challenging continuous control tasks. This research represents an important step forward in improving the exploration capabilities of deep reinforcement learning algorithms, with potential applications in robotics, autonomous vehicles, and other real-world control systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
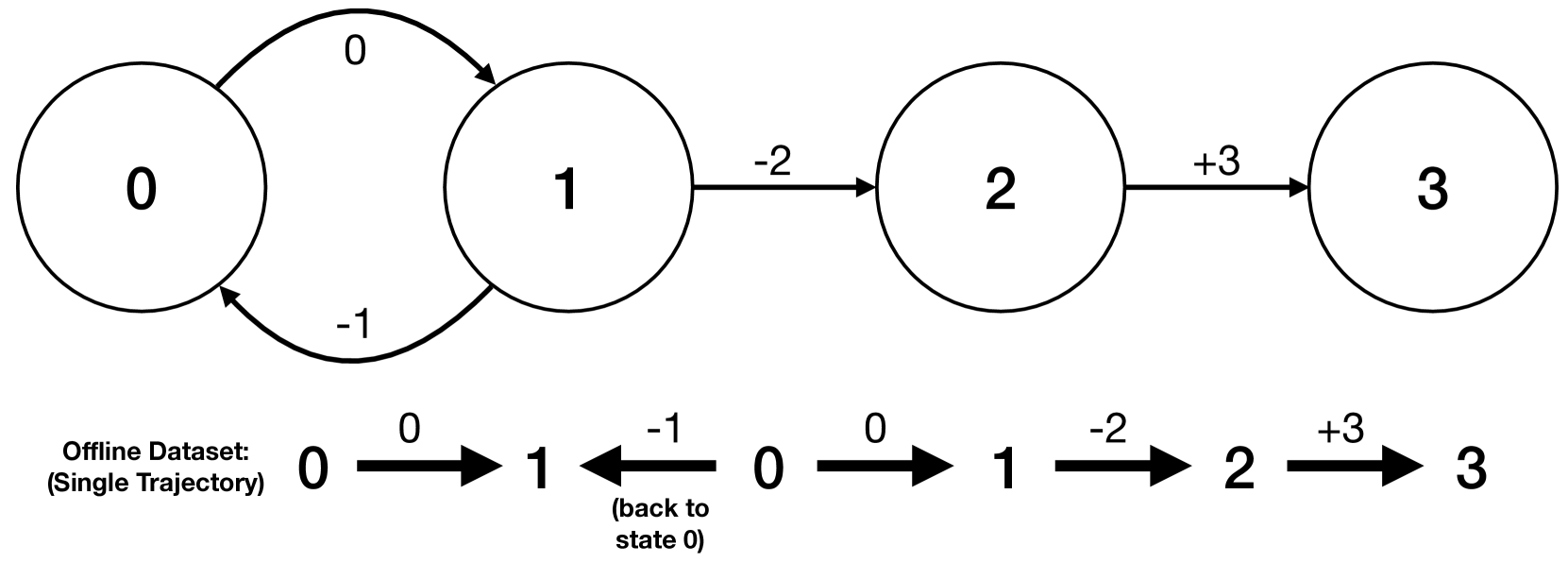
Efficient Offline Reinforcement Learning: The Critic is Critical
Adam Jelley, Trevor McInroe, Sam Devlin, Amos Storkey
0
0
Recent work has demonstrated both benefits and limitations from using supervised approaches (without temporal-difference learning) for offline reinforcement learning. While off-policy reinforcement learning provides a promising approach for improving performance beyond supervised approaches, we observe that training is often inefficient and unstable due to temporal difference bootstrapping. In this paper we propose a best-of-both approach by first learning the behavior policy and critic with supervised learning, before improving with off-policy reinforcement learning. Specifically, we demonstrate improved efficiency by pre-training with a supervised Monte-Carlo value-error, making use of commonly neglected downstream information from the provided offline trajectories. We find that we are able to more than halve the training time of the considered offline algorithms on standard benchmarks, and surprisingly also achieve greater stability. We further build on the importance of having consistent policy and value functions to propose novel hybrid algorithms, TD3+BC+CQL and EDAC+BC, that regularize both the actor and the critic towards the behavior policy. This helps to more reliably improve on the behavior policy when learning from limited human demonstrations. Code is available at https://github.com/AdamJelley/EfficientOfflineRL
6/21/2024
🤷
PAC-Bayesian Soft Actor-Critic Learning
Bahareh Tasdighi, Abdullah Akgul, Manuel Haussmann, Kenny Kazimirzak Brink, Melih Kandemir
0
0
Actor-critic algorithms address the dual goals of reinforcement learning (RL), policy evaluation and improvement via two separate function approximators. The practicality of this approach comes at the expense of training instability, caused mainly by the destructive effect of the approximation errors of the critic on the actor. We tackle this bottleneck by employing an existing Probably Approximately Correct (PAC) Bayesian bound for the first time as the critic training objective of the Soft Actor-Critic (SAC) algorithm. We further demonstrate that online learning performance improves significantly when a stochastic actor explores multiple futures by critic-guided random search. We observe our resulting algorithm to compare favorably against the state-of-the-art SAC implementation on multiple classical control and locomotion tasks in terms of both sample efficiency and regret.
6/11/2024

Diffusion Actor-Critic with Entropy Regulator
Yinuo Wang, Likun Wang, Yuxuan Jiang, Wenjun Zou, Tong Liu, Xujie Song, Wenxuan Wang, Liming Xiao, Jiang Wu, Jingliang Duan, Shengbo Eben Li
0
0
Reinforcement learning (RL) has proven highly effective in addressing complex decision-making and control tasks. However, in most traditional RL algorithms, the policy is typically parameterized as a diagonal Gaussian distribution with learned mean and variance, which constrains their capability to acquire complex policies. In response to this problem, we propose an online RL algorithm termed diffusion actor-critic with entropy regulator (DACER). This algorithm conceptualizes the reverse process of the diffusion model as a novel policy function and leverages the capability of the diffusion model to fit multimodal distributions, thereby enhancing the representational capacity of the policy. Since the distribution of the diffusion policy lacks an analytical expression, its entropy cannot be determined analytically. To mitigate this, we propose a method to estimate the entropy of the diffusion policy utilizing Gaussian mixture model. Building on the estimated entropy, we can learn a parameter $alpha$ that modulates the degree of exploration and exploitation. Parameter $alpha$ will be employed to adaptively regulate the variance of the added noise, which is applied to the action output by the diffusion model. Experimental trials on MuJoCo benchmarks and a multimodal task demonstrate that the DACER algorithm achieves state-of-the-art (SOTA) performance in most MuJoCo control tasks while exhibiting a stronger representational capacity of the diffusion policy.
6/18/2024
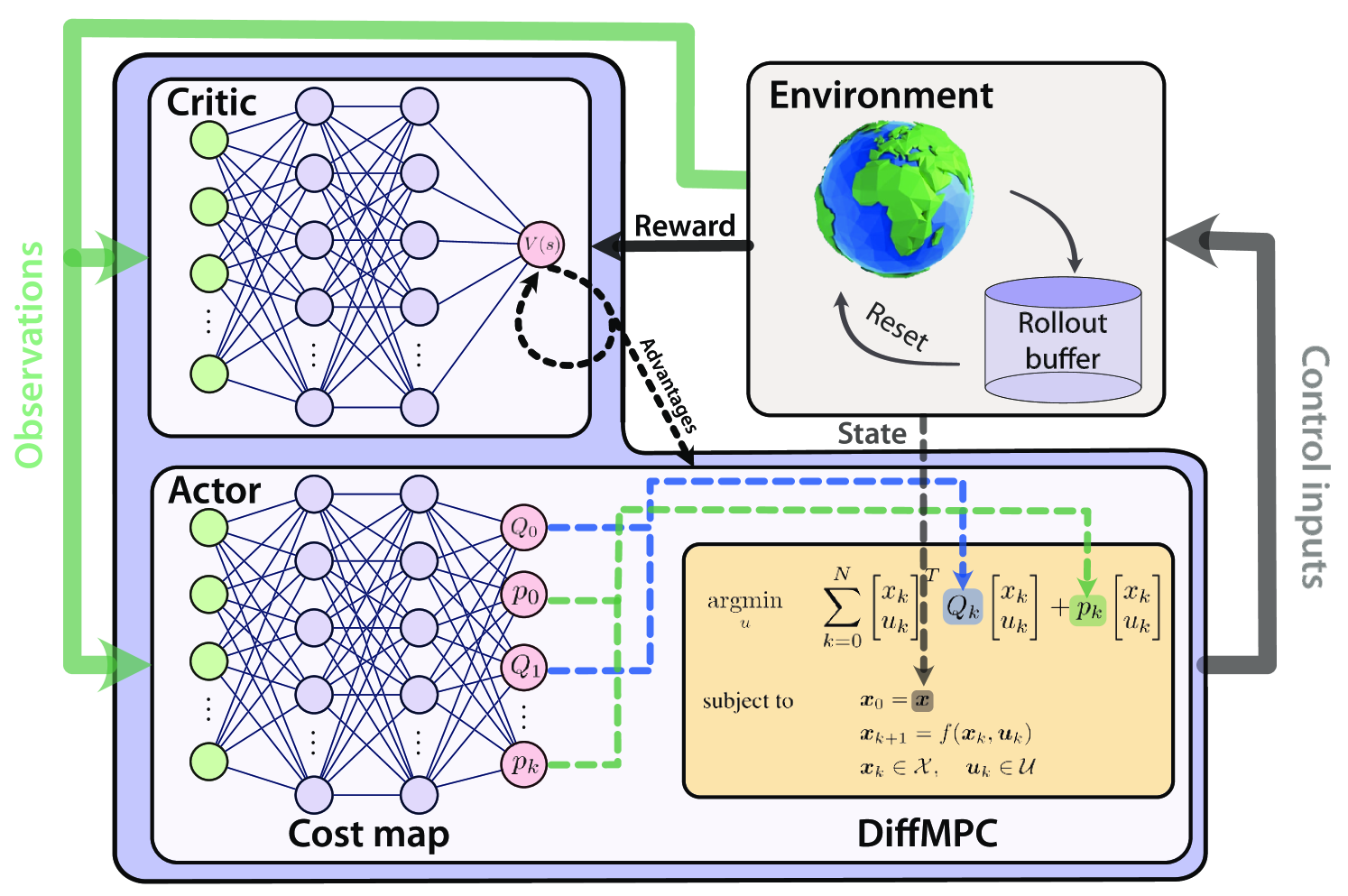
Actor-Critic Model Predictive Control
Angel Romero, Yunlong Song, Davide Scaramuzza
0
0
An open research question in robotics is how to combine the benefits of model-free reinforcement learning (RL) - known for its strong task performance and flexibility in optimizing general reward formulations - with the robustness and online replanning capabilities of model predictive control (MPC). This paper provides an answer by introducing a new framework called Actor-Critic Model Predictive Control. The key idea is to embed a differentiable MPC within an actor-critic RL framework. The proposed approach leverages the short-term predictive optimization capabilities of MPC with the exploratory and end-to-end training properties of RL. The resulting policy effectively manages both short-term decisions through the MPC-based actor and long-term prediction via the critic network, unifying the benefits of both model-based control and end-to-end learning. We validate our method in both simulation and the real world with a quadcopter platform across various high-level tasks. We show that the proposed architecture can achieve real-time control performance, learn complex behaviors via trial and error, and retain the predictive properties of the MPC to better handle out of distribution behaviour.
4/15/2024