GVDIFF: Grounded Text-to-Video Generation with Diffusion Models

0
Sign in to get full access
Overview
- The paper introduces GVdiff, a new grounded text-to-video generation model based on diffusion models.
- GVdiff learns to generate videos from textual descriptions by leveraging both grounded visual and language representations.
- The model achieves state-of-the-art performance on several text-to-video generation benchmarks.
Plain English Explanation
The researchers have developed a new system called GVdiff that can create videos from textual descriptions. For example, if you give it a description like "a dog playing fetch in a park," GVdiff will generate a video showing that scene.
The key innovation of GVdiff is that it uses diffusion models, a type of machine learning technique, to learn how to generate the videos. Diffusion models work by gradually adding noise to an image or video, then learning how to reverse that process to create new content.
GVdiff also grounds the text-to-video generation in visual and language representations that the model has learned from other data. This helps the system better understand the relationship between the textual descriptions and the visual content it needs to generate.
By combining the power of diffusion models with these grounded representations, GVdiff is able to produce high-quality videos that match the given text descriptions. This represents an important advance in the field of text-to-video generation.
Technical Explanation
The core of GVdiff is a diffusion model that learns to generate videos from text descriptions. The model first encodes the text input into a latent representation using a pretrained language model. It then uses this text encoding, along with visual features extracted from a pretrained vision model, to condition the diffusion process that generates the output video.
The key innovation of GVdiff is this grounding of the text-to-video generation in both visual and language representations. This allows the model to better understand the relationship between the textual descriptions and the visual content it needs to generate, leading to higher-quality results.
The researchers evaluate GVdiff on several text-to-video benchmarks, including CLEVR-Video and DiDeMo, and show that it outperforms previous state-of-the-art approaches.
Critical Analysis
The paper provides a thorough evaluation of GVdiff's performance and presents compelling results. However, the authors acknowledge some limitations of the current approach, such as the model's tendency to generate videos that are "safe" and lack diversity.
Additionally, the researchers note that GVdiff can struggle with generating videos that require complex interactions or dynamics. This suggests that further work may be needed to improve the model's ability to handle more challenging text-to-video generation tasks.
It would also be interesting to see how GVdiff compares to other emerging text-to-video generation approaches, such as those based on large language models or reinforcement learning. Exploring these comparisons could help situate GVdiff's strengths and weaknesses within the broader landscape of text-to-video generation research.
Conclusion
The GVdiff model represents an important advance in the field of text-to-video generation. By leveraging diffusion models and grounding the generation process in both visual and language representations, the researchers have developed a system that can generate high-quality videos from textual descriptions.
The success of GVdiff highlights the potential of diffusion models for video synthesis tasks and suggests that further research in this direction could lead to even more powerful and versatile text-to-video generation systems. As the field continues to evolve, it will be exciting to see how these technologies are applied to real-world applications and their potential impact on fields like entertainment, education, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
GVDIFF: Grounded Text-to-Video Generation with Diffusion Models
Huanzhang Dou, Ruixiang Li, Wei Su, Xi Li
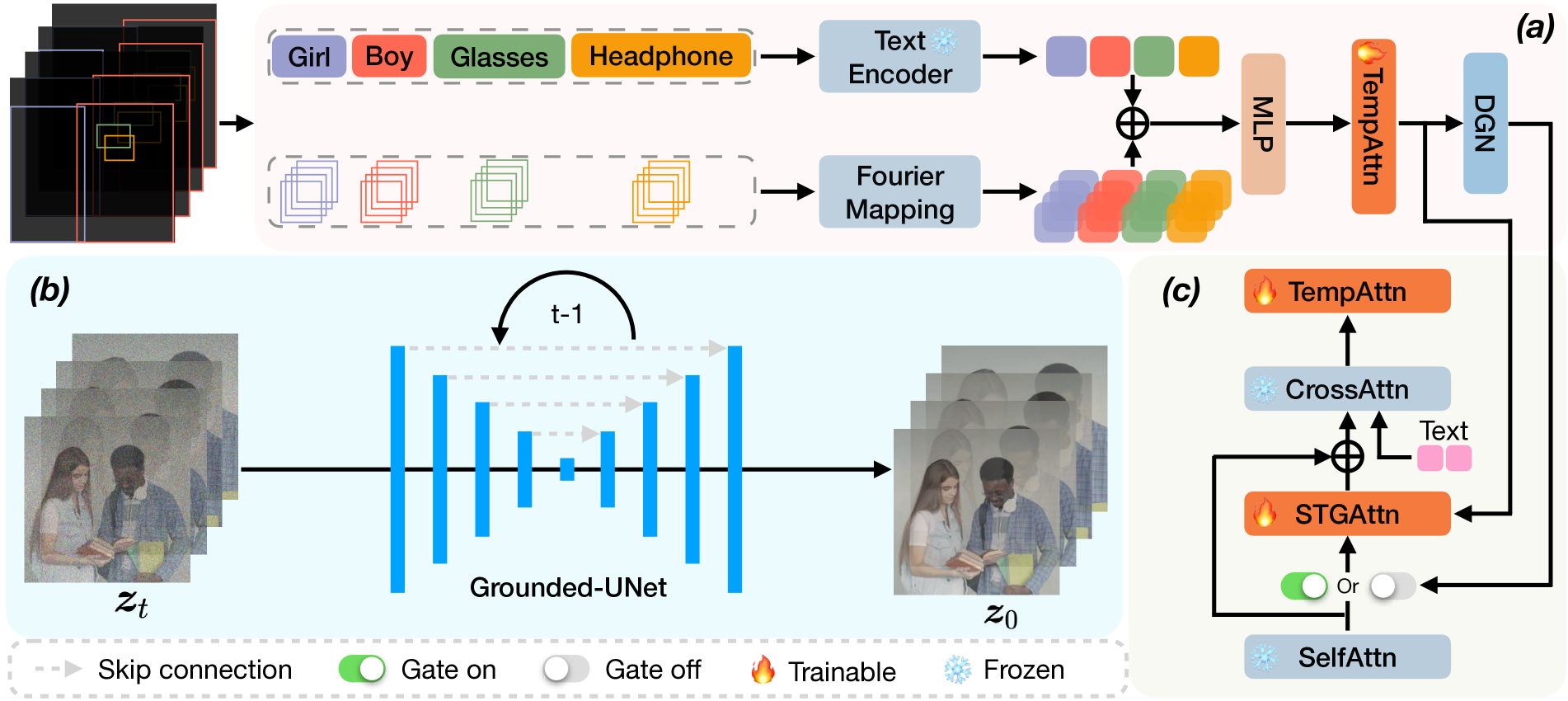
In text-to-video (T2V) generation, significant attention has been directed toward its development, yet unifying discrete and continuous grounding conditions in T2V generation remains under-explored. This paper proposes a Grounded text-to-Video generation framework, termed GVDIFF. First, we inject the grounding condition into the self-attention through an uncertainty-based representation to explicitly guide the focus of the network. Second, we introduce a spatial-temporal grounding layer that connects the grounding condition with target objects and enables the model with the grounded generation capacity in the spatial-temporal domain. Third, our dynamic gate network adaptively skips the redundant grounding process to selectively extract grounding information and semantics while improving efficiency. We extensively evaluate the grounded generation capacity of GVDIFF and demonstrate its versatility in applications, including long-range video generation, sequential prompts, and object-specific editing.
Read more7/8/2024
🤖
0
LLM-grounded Video Diffusion Models
Long Lian, Baifeng Shi, Adam Yala, Trevor Darrell, Boyi Li
Text-conditioned diffusion models have emerged as a promising tool for neural video generation. However, current models still struggle with intricate spatiotemporal prompts and often generate restricted or incorrect motion. To address these limitations, we introduce LLM-grounded Video Diffusion (LVD). Instead of directly generating videos from the text inputs, LVD first leverages a large language model (LLM) to generate dynamic scene layouts based on the text inputs and subsequently uses the generated layouts to guide a diffusion model for video generation. We show that LLMs are able to understand complex spatiotemporal dynamics from text alone and generate layouts that align closely with both the prompts and the object motion patterns typically observed in the real world. We then propose to guide video diffusion models with these layouts by adjusting the attention maps. Our approach is training-free and can be integrated into any video diffusion model that admits classifier guidance. Our results demonstrate that LVD significantly outperforms its base video diffusion model and several strong baseline methods in faithfully generating videos with the desired attributes and motion patterns.
Read more5/7/2024

0
Vivid-ZOO: Multi-View Video Generation with Diffusion Model
Bing Li, Cheng Zheng, Wenxuan Zhu, Jinjie Mai, Biao Zhang, Peter Wonka, Bernard Ghanem
While diffusion models have shown impressive performance in 2D image/video generation, diffusion-based Text-to-Multi-view-Video (T2MVid) generation remains underexplored. The new challenges posed by T2MVid generation lie in the lack of massive captioned multi-view videos and the complexity of modeling such multi-dimensional distribution. To this end, we propose a novel diffusion-based pipeline that generates high-quality multi-view videos centered around a dynamic 3D object from text. Specifically, we factor the T2MVid problem into viewpoint-space and time components. Such factorization allows us to combine and reuse layers of advanced pre-trained multi-view image and 2D video diffusion models to ensure multi-view consistency as well as temporal coherence for the generated multi-view videos, largely reducing the training cost. We further introduce alignment modules to align the latent spaces of layers from the pre-trained multi-view and the 2D video diffusion models, addressing the reused layers' incompatibility that arises from the domain gap between 2D and multi-view data. In support of this and future research, we further contribute a captioned multi-view video dataset. Experimental results demonstrate that our method generates high-quality multi-view videos, exhibiting vivid motions, temporal coherence, and multi-view consistency, given a variety of text prompts.
Read more6/14/2024

0
Exploring Pre-trained Text-to-Video Diffusion Models for Referring Video Object Segmentation
Zixin Zhu, Xuelu Feng, Dongdong Chen, Junsong Yuan, Chunming Qiao, Gang Hua
In this paper, we explore the visual representations produced from a pre-trained text-to-video (T2V) diffusion model for video understanding tasks. We hypothesize that the latent representation learned from a pretrained generative T2V model encapsulates rich semantics and coherent temporal correspondences, thereby naturally facilitating video understanding. Our hypothesis is validated through the classic referring video object segmentation (R-VOS) task. We introduce a novel framework, termed VD-IT, tailored with dedicatedly designed components built upon a fixed pretrained T2V model. Specifically, VD-IT uses textual information as a conditional input, ensuring semantic consistency across time for precise temporal instance matching. It further incorporates image tokens as supplementary textual inputs, enriching the feature set to generate detailed and nuanced masks. Besides, instead of using the standard Gaussian noise, we propose to predict the video-specific noise with an extra noise prediction module, which can help preserve the feature fidelity and elevates segmentation quality. Through extensive experiments, we surprisingly observe that fixed generative T2V diffusion models, unlike commonly used video backbones (e.g., Video Swin Transformer) pretrained with discriminative image/video pre-tasks, exhibit better potential to maintain semantic alignment and temporal consistency. On existing standard benchmarks, our VD-IT achieves highly competitive results, surpassing many existing state-of-the-art methods. The code is available at https://github.com/buxiangzhiren/VD-IT.
Read more7/9/2024