Hadamard Adapter: An Extreme Parameter-Efficient Adapter Tuning Method for Pre-trained Language Models

0

Sign in to get full access
Overview
- The paper introduces a novel parameter-efficient adapter tuning method called Hadamard Adapter for pre-trained language models.
- Hadamard Adapter aims to achieve high performance with a significantly smaller number of parameters compared to traditional fine-tuning approaches.
- The method leverages the Hadamard product to efficiently combine the representations from the pre-trained model and the adapter module.
Plain English Explanation
Adapters are a way to fine-tune pre-trained language models like BERT or GPT-3 for specific tasks, without having to update all the model parameters. This can be more efficient and effective than fully retraining the entire model. Parameter-Efficient Fine-Tuning Adapters and Adapters: Mixing Parameter-Efficient Adapters are examples of prior work on this idea.
In this paper, the researchers introduce a new adapter tuning method called Hadamard Adapter. The key idea is to use the Hadamard product (element-wise multiplication) to combine the representations from the pre-trained model and the adapter module. This allows the adapter to learn task-specific transformations while preserving the base knowledge from the pre-trained model.
Compared to previous adapter methods, Hadamard Adapter is able to achieve high performance using
Technical Explanation
The Hadamard Adapter architecture consists of two main components:
- Pre-trained Language Model: This is the base model, such as BERT or GPT-3, that has been pre-trained on a large corpus of text data.
- Hadamard Adapter: This is a lightweight module that is added on top of the pre-trained model. It learns task-specific transformations using the Hadamard product to combine its own representations with the representations from the pre-trained model.
The key innovation in Hadamard Adapter is this use of the Hadamard product, which allows the adapter to learn task-specific adaptations without having to update all the parameters in the pre-trained model. This makes it much more parameter-efficient compared to full fine-tuning.
The authors conduct extensive experiments on a variety of natural language processing tasks, including text classification, text generation, and question answering. They show that Hadamard Adapter consistently outperforms other parameter-efficient adaptation methods, such as Adapters: Mixing Parameter-Efficient Adapters and Adapter-X: A Novel General Parameter-Efficient Fine-Tuning Method, while using only a fraction of the parameters.
Critical Analysis
The paper provides a thorough and well-designed study of the Hadamard Adapter method. The authors carefully compare it to a range of baselines and state-of-the-art adaptation techniques, demonstrating its superior performance and parameter efficiency.
One potential limitation is that the experiments are focused on a relatively narrow set of natural language tasks. It would be interesting to see how Hadamard Adapter performs on other domains, such as vision or multimodal tasks, to better understand its broader applicability. Cross-Modal Adapter: Parameter-Efficient Transfer Learning is an example of recent work exploring parameter-efficient adaptation across different modalities.
Additionally, the paper does not provide much insight into the specific mechanisms or inductive biases that allow Hadamard Adapter to be so parameter-efficient. Further analysis of the learned adapter representations and their relationship to the pre-trained model could shed light on this.
Conclusion
The Hadamard Adapter introduced in this paper represents a significant advance in parameter-efficient fine-tuning of pre-trained language models. By leveraging the Hadamard product to combine representations, the method is able to achieve high performance on a range of NLP tasks while using a tiny fraction of the parameters required for full fine-tuning.
This work contributes to the growing body of research on adapter-based methods, which aim to make large pre-trained models more accessible and usable for a wider range of applications and users. The extreme parameter efficiency of Hadamard Adapter could enable more widespread deployment of powerful language models, particularly in resource-constrained settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hadamard Adapter: An Extreme Parameter-Efficient Adapter Tuning Method for Pre-trained Language Models
Yuyan Chen, Qiang Fu, Ge Fan, Lun Du, Jian-Guang Lou, Shi Han, Dongmei Zhang, Zhixu Li, Yanghua Xiao
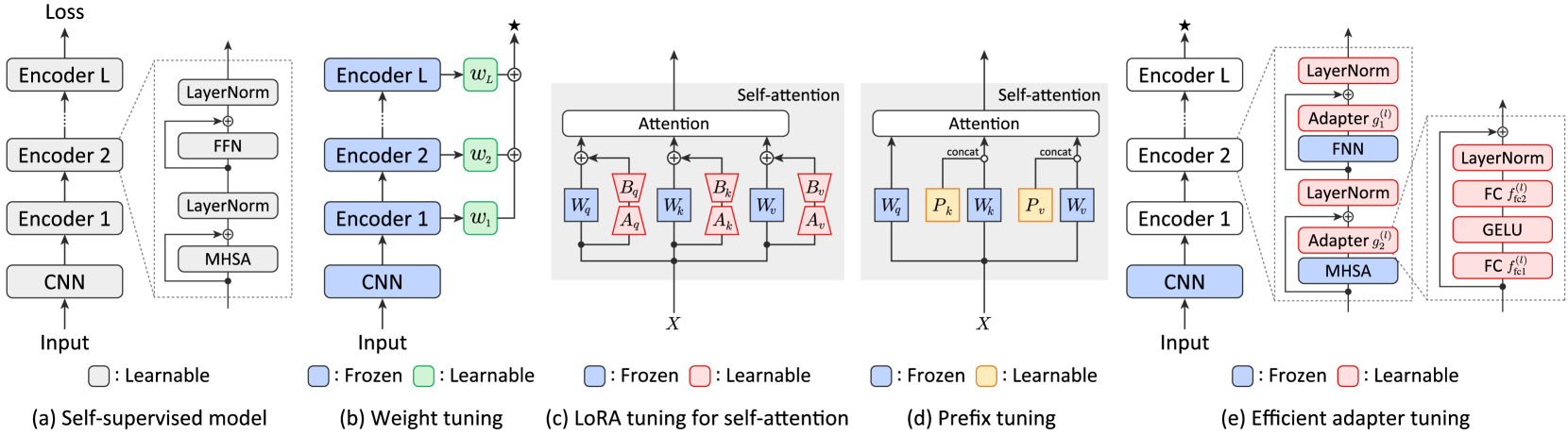
Recent years, Pre-trained Language models (PLMs) have swept into various fields of artificial intelligence and achieved great success. However, most PLMs, such as T5 and GPT3, have a huge amount of parameters, fine-tuning them is often expensive and time consuming, and storing them takes up a lot of space. Therefore, it is necessary to adopt a parameter-efficient approach to reduce parameters of PLMs in fine-tuning without compromising their performance in downstream tasks. In this paper, we design a novel adapter which only acts on self-attention outputs in PLMs. This adapter adopts element-wise linear transformation using Hadamard product, hence named as Hadamard adapter, requires the fewest parameters compared to previous parameter-efficient adapters. In addition, we also summarize some tuning patterns for Hadamard adapter shared by various downstream tasks, expecting to provide some guidance for further parameter reduction with shared adapters in future studies. The experiments conducted on the widely-used GLUE benchmark with several SOTA PLMs prove that the Hadamard adapter achieves competitive performance with only 0.033% parameters compared with full fine-tuning, and it has the fewest parameters compared with other adapters. Moreover, we further find that there is also some redundant layers in the Hadamard adapter which can be removed to achieve more parameter efficiency with only 0.022% parameters.
Read more7/17/2024
🌿
0
Parameter-Efficient Fine-Tuning With Adapters
Keyu Chen, Yuan Pang, Zi Yang
In the arena of language model fine-tuning, the traditional approaches, such as Domain-Adaptive Pretraining (DAPT) and Task-Adaptive Pretraining (TAPT), although effective, but computational intensive. This research introduces a novel adaptation method utilizing the UniPELT framework as a base and added a PromptTuning Layer, which significantly reduces the number of trainable parameters while maintaining competitive performance across various benchmarks. Our method employs adapters, which enable efficient transfer of pretrained models to new tasks with minimal retraining of the base model parameters. We evaluate our approach using three diverse datasets: the GLUE benchmark, a domain-specific dataset comprising four distinct areas, and the Stanford Question Answering Dataset 1.1 (SQuAD). Our results demonstrate that our customized adapter-based method achieves performance comparable to full model fine-tuning, DAPT+TAPT and UniPELT strategies while requiring fewer or equivalent amount of parameters. This parameter efficiency not only alleviates the computational burden but also expedites the adaptation process. The study underlines the potential of adapters in achieving high performance with significantly reduced resource consumption, suggesting a promising direction for future research in parameter-efficient fine-tuning.
Read more5/10/2024
0
ELP-Adapters: Parameter Efficient Adapter Tuning for Various Speech Processing Tasks
Nakamasa Inoue, Shinta Otake, Takumi Hirose, Masanari Ohi, Rei Kawakami
Self-supervised learning has emerged as a key approach for learning generic representations from speech data. Despite promising results in downstream tasks such as speech recognition, speaker verification, and emotion recognition, a significant number of parameters is required, which makes fine-tuning for each task memory-inefficient. To address this limitation, we introduce ELP-adapter tuning, a novel method for parameter-efficient fine-tuning using three types of adapter, namely encoder adapters (E-adapters), layer adapters (L-adapters), and a prompt adapter (P-adapter). The E-adapters are integrated into transformer-based encoder layers and help to learn fine-grained speech representations that are effective for speech recognition. The L-adapters create paths from each encoder layer to the downstream head and help to extract non-linguistic features from lower encoder layers that are effective for speaker verification and emotion recognition. The P-adapter appends pseudo features to CNN features to further improve effectiveness and efficiency. With these adapters, models can be quickly adapted to various speech processing tasks. Our evaluation across four downstream tasks using five backbone models demonstrated the effectiveness of the proposed method. With the WavLM backbone, its performance was comparable to or better than that of full fine-tuning on all tasks while requiring 90% fewer learnable parameters.
Read more8/1/2024
0
Adapters Mixup: Mixing Parameter-Efficient Adapters to Enhance the Adversarial Robustness of Fine-tuned Pre-trained Text Classifiers
Tuc Nguyen, Thai Le
Existing works show that augmenting the training data of pre-trained language models (PLMs) for classification tasks fine-tuned via parameter-efficient fine-tuning methods (PEFT) using both clean and adversarial examples can enhance their robustness under adversarial attacks. However, this adversarial training paradigm often leads to performance degradation on clean inputs and requires frequent re-training on the entire data to account for new, unknown attacks. To overcome these challenges while still harnessing the benefits of adversarial training and the efficiency of PEFT, this work proposes a novel approach, called AdpMixup, that combines two paradigms: (1) fine-tuning through adapters and (2) adversarial augmentation via mixup to dynamically leverage existing knowledge from a set of pre-known attacks for robust inference. Intuitively, AdpMixup fine-tunes PLMs with multiple adapters with both clean and pre-known adversarial examples and intelligently mixes them up in different ratios during prediction. Our experiments show AdpMixup achieves the best trade-off between training efficiency and robustness under both pre-known and unknown attacks, compared to existing baselines on five downstream tasks across six varied black-box attacks and 2 PLMs. All source code will be available.
Read more6/18/2024