Hallucination Benchmark in Medical Visual Question Answering
2401.05827
0
0
🔮
Abstract
The recent success of large language and vision models (LLVMs) on vision question answering (VQA), particularly their applications in medicine (Med-VQA), has shown a great potential of realizing effective visual assistants for healthcare. However, these models are not extensively tested on the hallucination phenomenon in clinical settings. Here, we created a hallucination benchmark of medical images paired with question-answer sets and conducted a comprehensive evaluation of the state-of-the-art models. The study provides an in-depth analysis of current models' limitations and reveals the effectiveness of various prompting strategies.
Create account to get full access
Overview
- This paper proposes a new benchmark for evaluating the capability of medical visual question answering (VQA) models to avoid hallucination, which is the generation of answers not grounded in the given visual information.
- The authors create a dataset of medical images with associated questions that require models to reason about the contents of the images to answer correctly, rather than relying on biases or prior knowledge.
- Evaluating models on this benchmark can provide insights into their ability to avoid hallucination and focus on the visual evidence when answering questions.
Plain English Explanation
Medical VQA models are designed to answer questions about medical images, such as X-rays or CT scans. However, these models can sometimes "hallucinate" answers that are not actually supported by the visual information in the image.
The authors of this paper wanted to create a new benchmark to test how well these models can avoid hallucination and instead focus on the contents of the image to answer questions correctly. They built a dataset of medical images paired with questions that require the model to reason about what it sees in the image, rather than just relying on general medical knowledge.
By evaluating VQA models on this new benchmark, researchers can better understand the models' strengths and weaknesses in terms of grounding their answers in the visual evidence. This could lead to improvements in the models' ability to provide reliable and informative answers for medical professionals and patients.
Technical Explanation
The paper proposes a new benchmark for evaluating medical visual question answering (VQA) models, with a focus on their ability to avoid hallucination. Hallucination refers to the generation of answers that are not grounded in the given visual information, but rather rely on biases or prior knowledge.
To create the benchmark, the authors curated a dataset of medical images paired with questions that require the model to reason about the visual contents to answer correctly. This is in contrast to questions that could be answered using general medical knowledge alone.
The dataset covers a range of medical imaging modalities, including x-rays, CT scans, and pathology slides. The questions span various clinical tasks, such as identifying anatomical structures, diagnosing conditions, and interpreting test results.
By evaluating VQA models on this hallucination benchmark, researchers can assess the models' ability to focus on the visual evidence rather than relying on hallucination. This provides insights into the models' robustness and reliability for real-world medical applications.
Critical Analysis
The authors acknowledge several limitations and areas for future work. First, the dataset is relatively small, and expanding it with more diverse medical images and question types could further strengthen the benchmark.
Additionally, the benchmark does not currently include open-ended questions, which would be a valuable extension to test the models' broader language understanding capabilities.
The authors also note that evaluating hallucination is inherently challenging, as it can be subjective to determine whether an answer is truly grounded in the visual information. Developing more precise and automated methods for identifying hallucination could improve the reliability of the benchmark.
Despite these limitations, the hallucination benchmark represents an important step towards building more trustworthy and clinically-relevant medical VQA systems. Continued research in this direction could have significant implications for the use of AI in healthcare.
Conclusion
This paper introduces a new benchmark for evaluating medical visual question answering models' ability to avoid hallucination. By creating a dataset of medical images paired with questions that require reasoning about visual contents, the authors have developed a tool to assess the models' reliability and robustness.
Assessing models on this hallucination benchmark can provide valuable insights into their strengths and weaknesses, ultimately leading to the development of more trustworthy AI systems for medical applications. While the benchmark has some limitations, it represents an important contribution to the field of medical AI and could have significant implications for improving patient care and outcomes.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
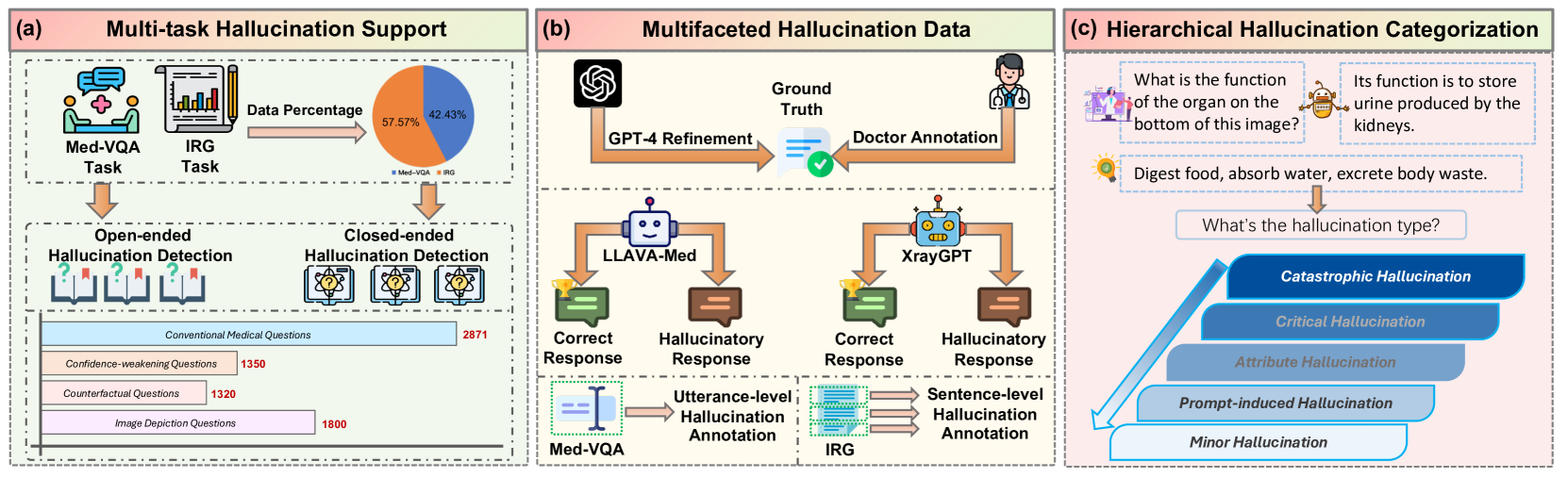
Detecting and Evaluating Medical Hallucinations in Large Vision Language Models
Jiawei Chen, Dingkang Yang, Tong Wu, Yue Jiang, Xiaolu Hou, Mingcheng Li, Shunli Wang, Dongling Xiao, Ke Li, Lihua Zhang
0
0
Large Vision Language Models (LVLMs) are increasingly integral to healthcare applications, including medical visual question answering and imaging report generation. While these models inherit the robust capabilities of foundational Large Language Models (LLMs), they also inherit susceptibility to hallucinations-a significant concern in high-stakes medical contexts where the margin for error is minimal. However, currently, there are no dedicated methods or benchmarks for hallucination detection and evaluation in the medical field. To bridge this gap, we introduce Med-HallMark, the first benchmark specifically designed for hallucination detection and evaluation within the medical multimodal domain. This benchmark provides multi-tasking hallucination support, multifaceted hallucination data, and hierarchical hallucination categorization. Furthermore, we propose the MediHall Score, a new medical evaluative metric designed to assess LVLMs' hallucinations through a hierarchical scoring system that considers the severity and type of hallucination, thereby enabling a granular assessment of potential clinical impacts. We also present MediHallDetector, a novel Medical LVLM engineered for precise hallucination detection, which employs multitask training for hallucination detection. Through extensive experimental evaluations, we establish baselines for popular LVLMs using our benchmark. The findings indicate that MediHall Score provides a more nuanced understanding of hallucination impacts compared to traditional metrics and demonstrate the enhanced performance of MediHallDetector. We hope this work can significantly improve the reliability of LVLMs in medical applications. All resources of this work will be released soon.
6/17/2024

A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
0
0
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
5/7/2024

MedThink: Inducing Medical Large-scale Visual Language Models to Hallucinate Less by Thinking More
Yue Jiang, Jiawei Chen, Dingkang Yang, Mingcheng Li, Shunli Wang, Tong Wu, Ke Li, Lihua Zhang
0
0
When Large Vision Language Models (LVLMs) are applied to multimodal medical generative tasks, they suffer from significant model hallucination issues. This severely impairs the model's generative accuracy, making it challenging for LVLMs to be implemented in real-world medical scenarios to assist doctors in diagnosis. Enhancing the training data for downstream medical generative tasks is an effective way to address model hallucination. Moreover, the limited availability of training data in the medical field and privacy concerns greatly hinder the model's accuracy and generalization capabilities. In this paper, we introduce a method that mimics human cognitive processes to construct fine-grained instruction pairs and apply the concept of chain-of-thought (CoT) from inference scenarios to training scenarios, thereby proposing a method called MedThink. Our experiments on various LVLMs demonstrate that our novel data construction method tailored for the medical domain significantly improves the model's performance in medical image report generation tasks and substantially mitigates the hallucinations. All resources of this work will be released soon.
6/19/2024
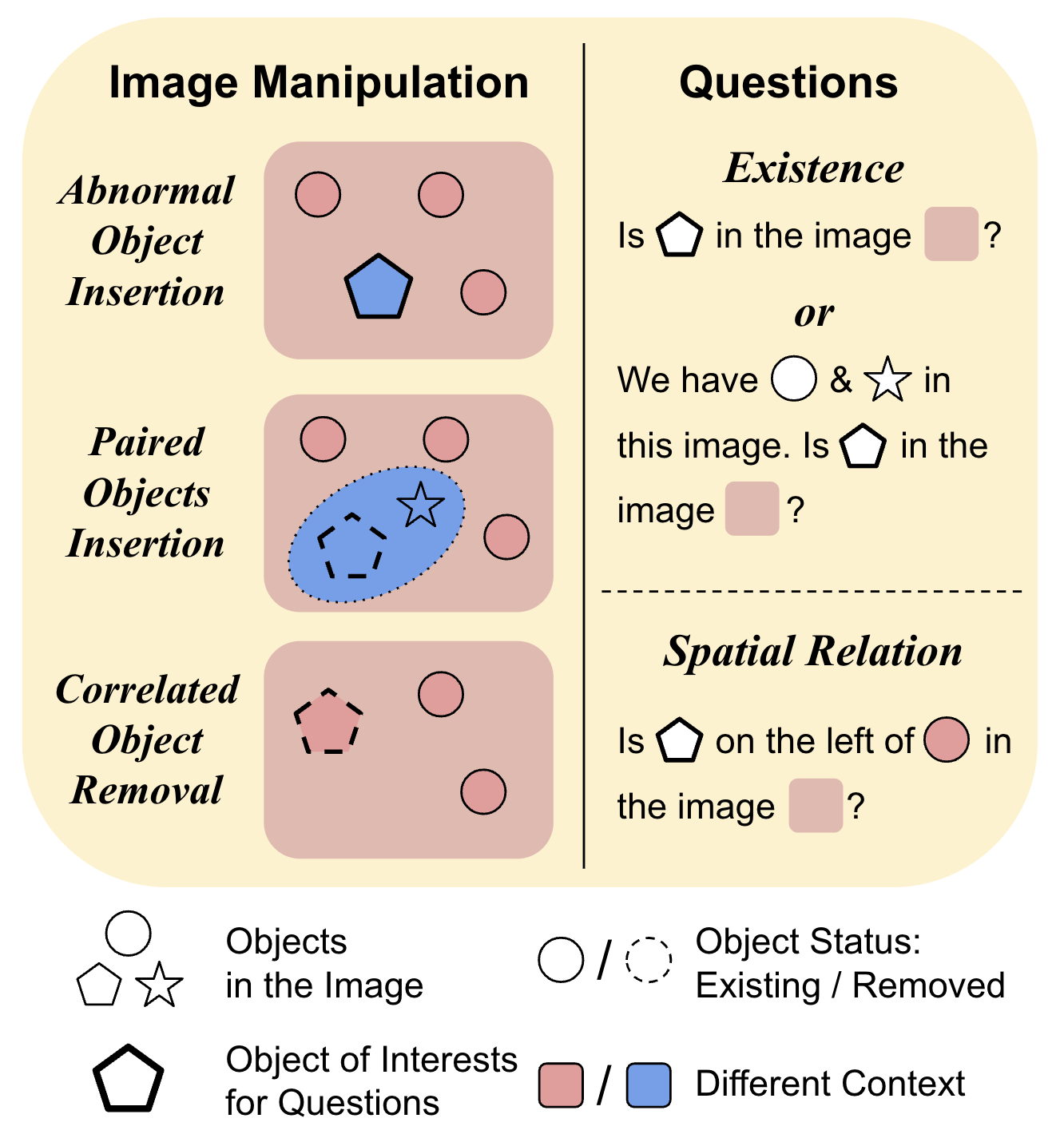
AUTOHALLUSION: Automatic Generation of Hallucination Benchmarks for Vision-Language Models
Xiyang Wu, Tianrui Guan, Dianqi Li, Shuaiyi Huang, Xiaoyu Liu, Xijun Wang, Ruiqi Xian, Abhinav Shrivastava, Furong Huang, Jordan Lee Boyd-Graber, Tianyi Zhou, Dinesh Manocha
0
0
Large vision-language models (LVLMs) hallucinate: certain context cues in an image may trigger the language module's overconfident and incorrect reasoning on abnormal or hypothetical objects. Though a few benchmarks have been developed to investigate LVLM hallucinations, they mainly rely on hand-crafted corner cases whose fail patterns may hardly generalize, and finetuning on them could undermine their validity. These motivate us to develop the first automatic benchmark generation approach, AUTOHALLUSION, that harnesses a few principal strategies to create diverse hallucination examples. It probes the language modules in LVLMs for context cues and uses them to synthesize images by: (1) adding objects abnormal to the context cues; (2) for two co-occurring objects, keeping one and excluding the other; or (3) removing objects closely tied to the context cues. It then generates image-based questions whose ground-truth answers contradict the language module's prior. A model has to overcome contextual biases and distractions to reach correct answers, while incorrect or inconsistent answers indicate hallucinations. AUTOHALLUSION enables us to create new benchmarks at the minimum cost and thus overcomes the fragility of hand-crafted benchmarks. It also reveals common failure patterns and reasons, providing key insights to detect, avoid, or control hallucinations. Comprehensive evaluations of top-tier LVLMs, e.g., GPT-4V(ision), Gemini Pro Vision, Claude 3, and LLaVA-1.5, show a 97.7% and 98.7% success rate of hallucination induction on synthetic and real-world datasets of AUTOHALLUSION, paving the way for a long battle against hallucinations.
6/18/2024