MedThink: Inducing Medical Large-scale Visual Language Models to Hallucinate Less by Thinking More
2406.11451
0
0

Abstract
When Large Vision Language Models (LVLMs) are applied to multimodal medical generative tasks, they suffer from significant model hallucination issues. This severely impairs the model's generative accuracy, making it challenging for LVLMs to be implemented in real-world medical scenarios to assist doctors in diagnosis. Enhancing the training data for downstream medical generative tasks is an effective way to address model hallucination. Moreover, the limited availability of training data in the medical field and privacy concerns greatly hinder the model's accuracy and generalization capabilities. In this paper, we introduce a method that mimics human cognitive processes to construct fine-grained instruction pairs and apply the concept of chain-of-thought (CoT) from inference scenarios to training scenarios, thereby proposing a method called MedThink. Our experiments on various LVLMs demonstrate that our novel data construction method tailored for the medical domain significantly improves the model's performance in medical image report generation tasks and substantially mitigates the hallucinations. All resources of this work will be released soon.
Create account to get full access
Overview
- This paper proposes a novel approach, called MedThink, to reduce hallucinations in medical large-scale visual language models (LLMs).
- Hallucinations occur when LLMs generate false or nonsensical content, which is a significant problem in critical domains like healthcare.
- The MedThink method aims to induce LLMs to "think more" before generating outputs, leading to fewer hallucinations.
Plain English Explanation
The paper discusses a new technique called MedThink that is designed to reduce hallucinations in large artificial intelligence (AI) models used in healthcare. Hallucinations are when these AI models generate false or nonsensical information, which can be a major problem in sensitive fields like medicine.
The key idea behind MedThink is to get the AI models to "think more" before producing their outputs. This is achieved through a specialized training process that encourages the models to be more careful and deliberate, rather than rushing to produce responses. The goal is to have the models generate fewer hallucinations and provide more reliable and accurate information to healthcare providers and patients.
By mitigating hallucinations in medical LLMs, the MedThink approach aims to make these powerful AI tools safer and more trustworthy for real-world healthcare applications, where mistakes could have serious consequences.
Technical Explanation
The paper presents the MedThink method, which builds upon previous work on detecting and alleviating hallucinations in large vision-language models.
The key innovation of MedThink is a training procedure that encourages the model to engage in more "deliberative thinking" before generating outputs. This is achieved through a multi-stage process:
- The model is first trained on a large medical dataset using standard techniques.
- A "thinking module" is then added to the model, which prompts it to engage in additional reasoning steps before producing a final output.
- The model is further fine-tuned using a specialized loss function that rewards the thinking module's ability to identify and filter out potential hallucinations.
The experiments demonstrate that the MedThink-trained models exhibit significantly fewer hallucinations compared to standard LLMs, while maintaining high performance on downstream medical tasks. The authors attribute this to the model's increased ability to carefully consider its outputs before generating them.
Critical Analysis
The authors provide a thorough analysis of the MedThink approach and its limitations. They acknowledge that while the method is effective at reducing hallucinations, it does not eliminate them entirely. There may still be cases where the model's thinking process fails to detect or correct erroneous outputs.
Additionally, the increased computational complexity introduced by the thinking module may limit the scalability and real-time performance of MedThink-based models, especially for applications that require rapid responses.
The paper also notes that the evaluation of medical hallucinations is inherently challenging, as it requires expert human judgment to determine the accuracy and clinical relevance of the model's outputs. Further research is needed to develop more robust and standardized evaluation methodologies in this domain.
Conclusion
The MedThink paper presents a promising approach to mitigating hallucinations in medical large-scale visual language models. By encouraging these models to engage in more deliberative thinking, the method can significantly reduce the generation of false or nonsensical content, which is a critical concern in healthcare applications.
While the approach has limitations and areas for further research, the authors have demonstrated the potential of MedThink to improve the reliability and trustworthiness of AI systems in the medical domain. As large language models continue to advance, techniques like MedThink will become increasingly important for ensuring the safe and responsible deployment of these powerful technologies in mission-critical settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏋️
Prescribing the Right Remedy: Mitigating Hallucinations in Large Vision-Language Models via Targeted Instruction Tuning
Rui Hu, Yahan Tu, Jitao Sang
0
0
Despite achieving outstanding performance on various cross-modal tasks, current large vision-language models (LVLMs) still suffer from hallucination issues, manifesting as inconsistencies between their generated responses and the corresponding images. Prior research has implicated that the low quality of instruction data, particularly the skewed balance between positive and negative samples, is a significant contributor to model hallucinations. Recently, researchers have proposed high-quality instruction datasets, such as LRV-Instruction, to mitigate model hallucination. Nonetheless, our investigation reveals that hallucinatory concepts from different LVLMs exhibit specificity, i.e. the distribution of hallucinatory concepts varies significantly across models. Existing datasets did not consider the hallucination specificity of different models in the design processes, thereby diminishing their efficacy in mitigating model hallucination. In this paper, we propose a targeted instruction data generation framework named DFTG that tailored to the hallucination specificity of different models. Concretely, DFTG consists of two stages: hallucination diagnosis, which extracts the necessary information from the model's responses and images for hallucination diagnosis; and targeted data generation, which generates targeted instruction data based on diagnostic results. The experimental results on hallucination benchmarks demonstrate that the targeted instruction data generated by our method are more effective in mitigating hallucinations compared to previous datasets.
4/17/2024

A Survey on Hallucination in Large Vision-Language Models
Hanchao Liu, Wenyuan Xue, Yifei Chen, Dapeng Chen, Xiutian Zhao, Ke Wang, Liping Hou, Rongjun Li, Wei Peng
0
0
Recent development of Large Vision-Language Models (LVLMs) has attracted growing attention within the AI landscape for its practical implementation potential. However, ``hallucination'', or more specifically, the misalignment between factual visual content and corresponding textual generation, poses a significant challenge of utilizing LVLMs. In this comprehensive survey, we dissect LVLM-related hallucinations in an attempt to establish an overview and facilitate future mitigation. Our scrutiny starts with a clarification of the concept of hallucinations in LVLMs, presenting a variety of hallucination symptoms and highlighting the unique challenges inherent in LVLM hallucinations. Subsequently, we outline the benchmarks and methodologies tailored specifically for evaluating hallucinations unique to LVLMs. Additionally, we delve into an investigation of the root causes of these hallucinations, encompassing insights from the training data and model components. We also critically review existing methods for mitigating hallucinations. The open questions and future directions pertaining to hallucinations within LVLMs are discussed to conclude this survey.
5/7/2024

Alleviating Hallucinations in Large Vision-Language Models through Hallucination-Induced Optimization
Beitao Chen, Xinyu Lyu, Lianli Gao, Jingkuan Song, Heng Tao Shen
0
0
Although Large Visual Language Models (LVLMs) have demonstrated exceptional abilities in understanding multimodal data, they invariably suffer from hallucinations, leading to a disconnect between the generated text and the corresponding images. Almost all current visual contrastive decoding methods attempt to mitigate these hallucinations by introducing visual uncertainty information that appropriately widens the contrastive logits gap between hallucinatory and targeted ones. However, due to uncontrollable nature of the global visual uncertainty, they struggle to precisely induce the hallucinatory tokens, which severely limits their effectiveness in mitigating hallucinations and may even lead to the generation of undesired hallucinations. To tackle this issue, we conducted the theoretical analysis to promote the effectiveness of contrast decoding. Building on this insight, we introduce a novel optimization strategy named Hallucination-Induced Optimization (HIO). This strategy seeks to amplify the contrast between hallucinatory and targeted tokens relying on a fine-tuned theoretical preference model (i.e., Contrary Bradley-Terry Model), thereby facilitating efficient contrast decoding to alleviate hallucinations in LVLMs. Extensive experimental research demonstrates that our HIO strategy can effectively reduce hallucinations in LVLMs, outperforming state-of-the-art methods across various benchmarks.
5/27/2024
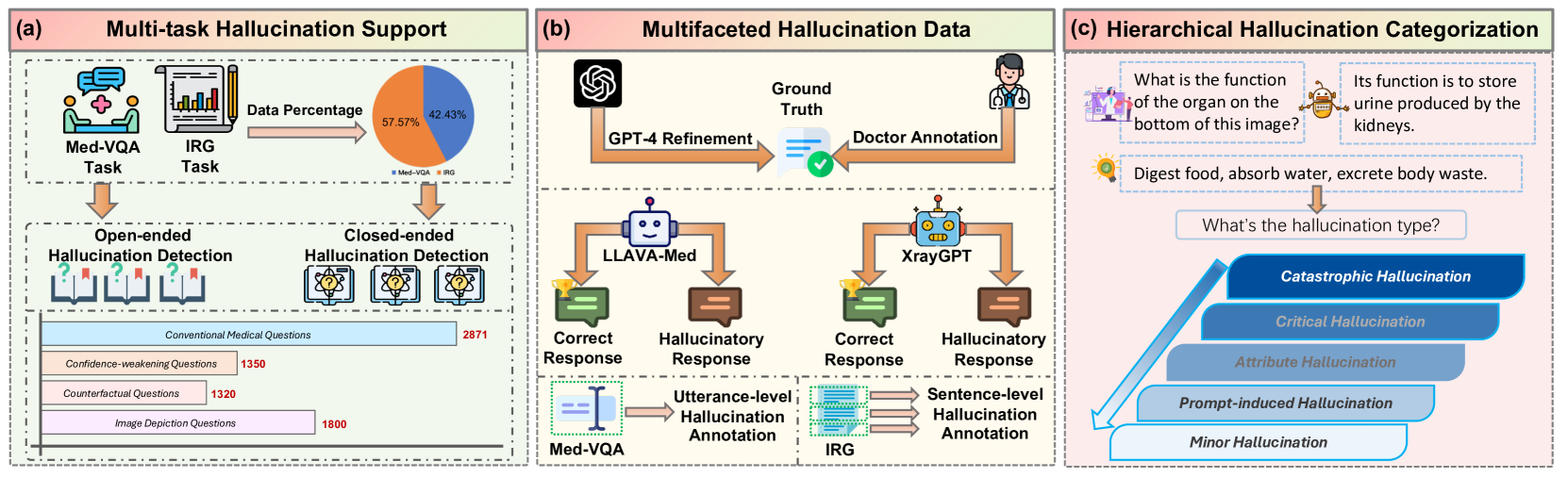
Detecting and Evaluating Medical Hallucinations in Large Vision Language Models
Jiawei Chen, Dingkang Yang, Tong Wu, Yue Jiang, Xiaolu Hou, Mingcheng Li, Shunli Wang, Dongling Xiao, Ke Li, Lihua Zhang
0
0
Large Vision Language Models (LVLMs) are increasingly integral to healthcare applications, including medical visual question answering and imaging report generation. While these models inherit the robust capabilities of foundational Large Language Models (LLMs), they also inherit susceptibility to hallucinations-a significant concern in high-stakes medical contexts where the margin for error is minimal. However, currently, there are no dedicated methods or benchmarks for hallucination detection and evaluation in the medical field. To bridge this gap, we introduce Med-HallMark, the first benchmark specifically designed for hallucination detection and evaluation within the medical multimodal domain. This benchmark provides multi-tasking hallucination support, multifaceted hallucination data, and hierarchical hallucination categorization. Furthermore, we propose the MediHall Score, a new medical evaluative metric designed to assess LVLMs' hallucinations through a hierarchical scoring system that considers the severity and type of hallucination, thereby enabling a granular assessment of potential clinical impacts. We also present MediHallDetector, a novel Medical LVLM engineered for precise hallucination detection, which employs multitask training for hallucination detection. Through extensive experimental evaluations, we establish baselines for popular LVLMs using our benchmark. The findings indicate that MediHall Score provides a more nuanced understanding of hallucination impacts compared to traditional metrics and demonstrate the enhanced performance of MediHallDetector. We hope this work can significantly improve the reliability of LVLMs in medical applications. All resources of this work will be released soon.
6/17/2024