Hallucination Index: An Image Quality Metric for Generative Reconstruction Models

0

Sign in to get full access
Overview
- Presents a new metric called the "Hallucination Index" to evaluate the quality of generative reconstruction models
- Focuses on addressing the issue of model hallucinations, where the model generates content that is not present in the original data
- Introduces a method to quantify hallucination and uncertainty in generative models, particularly for medical image reconstruction tasks
Plain English Explanation
The paper introduces a new way to measure the quality of generative models, particularly those used for medical image reconstruction. The key issue the authors address is "hallucination" - where the model generates content that is not actually present in the original data.
This is a common problem with generative models, as they can sometimes create convincing-looking outputs that deviate from reality. The Hallucination Index proposed in this paper provides a way to quantify how much a model is hallucinating, as well as the overall uncertainty in its outputs.
The authors argue that being able to measure hallucination is crucial for deploying these models in high-stakes domains like medical imaging, where generating incorrect information could have serious consequences. Their method allows developers to better understand model behavior and mitigate hallucination issues.
Technical Explanation
The paper introduces the "Hallucination Index" (HI), a new metric for evaluating the quality of generative reconstruction models. The HI quantifies the amount of hallucination and uncertainty in the model's outputs.
The authors propose a two-stage process to compute the HI. First, they use a pre-trained segmentation model to obtain a "ground truth" segmentation mask for the input image. Then, they feed the input image into the reconstruction model and compare the model's output to the ground truth segmentation.
The difference between the model's output and the ground truth is used to compute the HI. Areas where the model's output differs significantly from the ground truth are considered hallucinations, and the overall extent of these hallucinations is captured by the HI metric.
The authors evaluate their approach on a medical image reconstruction task, using diffusion models as the generative reconstruction models. They show that the HI metric can effectively identify and quantify hallucinations in the model outputs, providing valuable insights into model behavior. The paper also discusses ways to mitigate hallucination issues in these models.
Critical Analysis
The Hallucination Index proposed in this paper is a valuable contribution to the field of generative reconstruction models, particularly in high-stakes domains like medical imaging. By quantifying hallucination and uncertainty, the metric provides a clear way to evaluate model performance and identify potential issues.
However, the approach does rely on having a pre-trained segmentation model to act as the "ground truth" reference. The quality and accuracy of this segmentation model could potentially impact the reliability of the HI metric. Additionally, the paper focuses on a specific medical imaging task, and it's unclear how well the HI would generalize to other types of generative reconstruction problems.
Further research could explore the robustness of the HI metric, as well as its applicability to a wider range of generative models and domains. Investigating the relationship between HI and other model quality metrics could also provide additional insights.
Conclusion
The "Hallucination Index" introduced in this paper represents an important step forward in evaluating the quality of generative reconstruction models. By quantifying hallucination and uncertainty, the metric provides a valuable tool for developers and researchers working on these models, particularly in high-stakes applications like medical imaging.
The paper's focus on addressing the critical issue of hallucinations is timely and relevant, as the use of generative models continues to grow in various domains. The authors' work highlights the importance of developing robust evaluation methods to ensure the reliability and safety of these powerful AI systems.
Overall, this research contributes to the ongoing efforts to understand and mitigate hallucinations in generative models, which is a crucial step towards realizing the full potential of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hallucination Index: An Image Quality Metric for Generative Reconstruction Models
Matthew Tivnan, Siyeop Yoon, Zhennong Chen, Xiang Li, Dufan Wu, Quanzheng Li
Generative image reconstruction algorithms such as measurement conditioned diffusion models are increasingly popular in the field of medical imaging. These powerful models can transform low signal-to-noise ratio (SNR) inputs into outputs with the appearance of high SNR. However, the outputs can have a new type of error called hallucinations. In medical imaging, these hallucinations may not be obvious to a Radiologist but could cause diagnostic errors. Generally, hallucination refers to error in estimation of object structure caused by a machine learning model, but there is no widely accepted method to evaluate hallucination magnitude. In this work, we propose a new image quality metric called the hallucination index. Our approach is to compute the Hellinger distance from the distribution of reconstructed images to a zero hallucination reference distribution. To evaluate our approach, we conducted a numerical experiment with electron microscopy images, simulated noisy measurements, and applied diffusion based reconstructions. We sampled the measurements and the generative reconstructions repeatedly to compute the sample mean and covariance. For the zero hallucination reference, we used the forward diffusion process applied to ground truth. Our results show that higher measurement SNR leads to lower hallucination index for the same apparent image quality. We also evaluated the impact of early stopping in the reverse diffusion process and found that more modest denoising strengths can reduce hallucination. We believe this metric could be useful for evaluation of generative image reconstructions or as a warning label to inform radiologists about the degree of hallucinations in medical images.
Read more7/18/2024

0
Looks Too Good To Be True: An Information-Theoretic Analysis of Hallucinations in Generative Restoration Models
Regev Cohen, Idan Kligvasser, Ehud Rivlin, Daniel Freedman
The pursuit of high perceptual quality in image restoration has driven the development of revolutionary generative models, capable of producing results often visually indistinguishable from real data. However, as their perceptual quality continues to improve, these models also exhibit a growing tendency to generate hallucinations - realistic-looking details that do not exist in the ground truth images. The presence of hallucinations introduces uncertainty regarding the reliability of the models' predictions, raising major concerns about their practical application. In this paper, we employ information-theory tools to investigate this phenomenon, revealing a fundamental tradeoff between uncertainty and perception. We rigorously analyze the relationship between these two factors, proving that the global minimal uncertainty in generative models grows in tandem with perception. In particular, we define the inherent uncertainty of the restoration problem and show that attaining perfect perceptual quality entails at least twice this uncertainty. Additionally, we establish a relation between mean squared-error distortion, uncertainty and perception, through which we prove the aforementioned uncertainly-perception tradeoff induces the well-known perception-distortion tradeoff. This work uncovers fundamental limitations of generative models in achieving both high perceptual quality and reliable predictions for image restoration. We demonstrate our theoretical findings through an analysis of single image super-resolution algorithms. Our work aims to raise awareness among practitioners about this inherent tradeoff, empowering them to make informed decisions and potentially prioritize safety over perceptual performance.
Read more6/5/2024
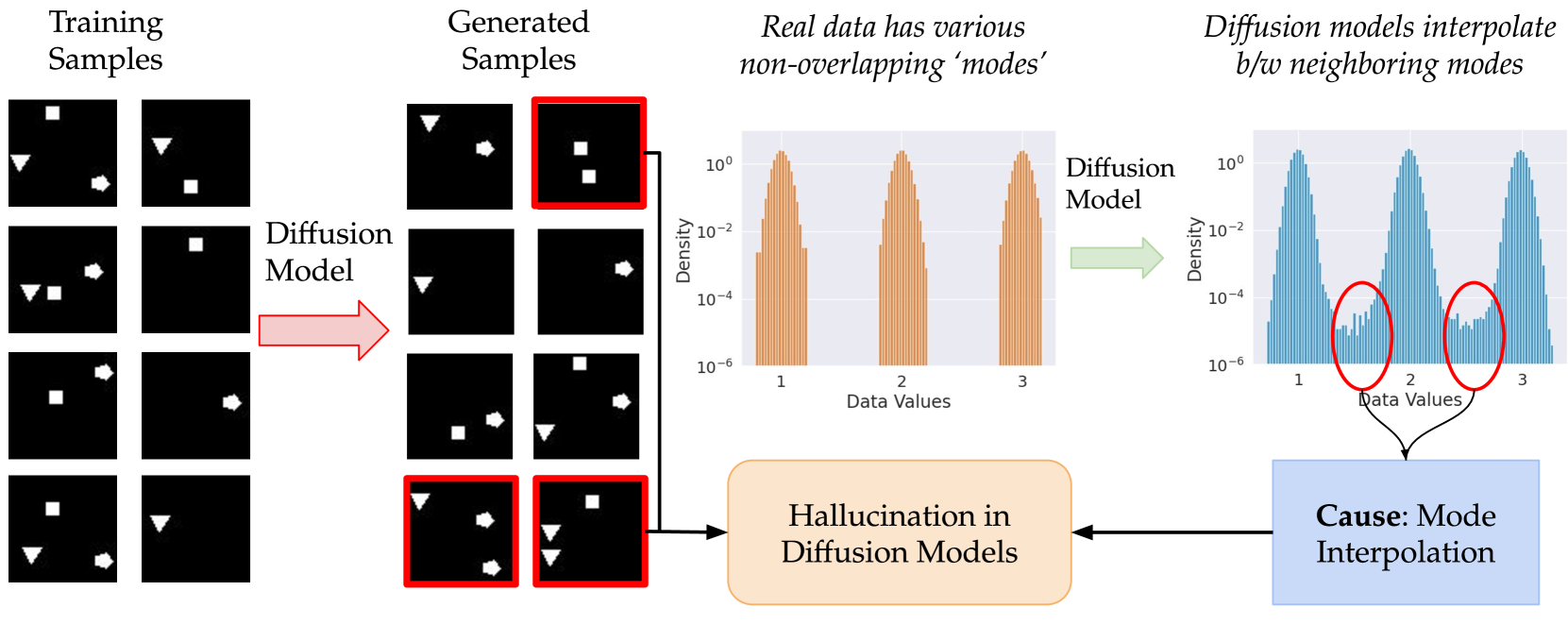
2
Understanding Hallucinations in Diffusion Models through Mode Interpolation
Sumukh K Aithal, Pratyush Maini, Zachary C. Lipton, J. Zico Kolter
Colloquially speaking, image generation models based upon diffusion processes are frequently said to exhibit hallucinations, samples that could never occur in the training data. But where do such hallucinations come from? In this paper, we study a particular failure mode in diffusion models, which we term mode interpolation. Specifically, we find that diffusion models smoothly interpolate between nearby data modes in the training set, to generate samples that are completely outside the support of the original training distribution; this phenomenon leads diffusion models to generate artifacts that never existed in real data (i.e., hallucinations). We systematically study the reasons for, and the manifestation of this phenomenon. Through experiments on 1D and 2D Gaussians, we show how a discontinuous loss landscape in the diffusion model's decoder leads to a region where any smooth approximation will cause such hallucinations. Through experiments on artificial datasets with various shapes, we show how hallucination leads to the generation of combinations of shapes that never existed. Finally, we show that diffusion models in fact know when they go out of support and hallucinate. This is captured by the high variance in the trajectory of the generated sample towards the final few backward sampling process. Using a simple metric to capture this variance, we can remove over 95% of hallucinations at generation time while retaining 96% of in-support samples. We conclude our exploration by showing the implications of such hallucination (and its removal) on the collapse (and stabilization) of recursive training on synthetic data with experiments on MNIST and 2D Gaussians dataset. We release our code at https://github.com/locuslab/diffusion-model-hallucination.
Read more8/27/2024

0
Evaluating Image Hallucination in Text-to-Image Generation with Question-Answering
Youngsun Lim, Hojun Choi, Hyunjung Shim
Despite the impressive success of text-to-image (TTI) generation models, existing studies overlook the issue of whether these models accurately convey factual information. In this paper, we focus on the problem of image hallucination, where images created by generation models fail to faithfully depict factual content. To address this, we introduce I-HallA (Image Hallucination evaluation with Question Answering), a novel automated evaluation metric that measures the factuality of generated images through visual question answering (VQA). We also introduce I-HallA v1.0, a curated benchmark dataset for this purpose. As part of this process, we develop a pipeline that generates high-quality question-answer pairs using multiple GPT-4 Omni-based agents, with human judgments to ensure accuracy. Our evaluation protocols measure image hallucination by testing if images from existing text-to-image models can correctly respond to these questions. The I-HallA v1.0 dataset comprises 1.2K diverse image-text pairs across nine categories with 1,000 rigorously curated questions covering various compositional challenges. We evaluate five text-to-image models using I-HallA and reveal that these state-of-the-art models often fail to accurately convey factual information. Moreover, we validate the reliability of our metric by demonstrating a strong Spearman correlation (rho=0.95) with human judgments. We believe our benchmark dataset and metric can serve as a foundation for developing factually accurate text-to-image generation models.
Read more9/20/2024