Exploiting Semantic Reconstruction to Mitigate Hallucinations in Vision-Language Models

0

Sign in to get full access
Overview
- This paper explores techniques to mitigate hallucinations in vision-language models, which are AI systems that generate textual descriptions of images.
- Hallucinations refer to the issue where these models generate plausible-sounding but factually incorrect captions for images.
- The key idea is to leverage semantic reconstruction - teaching the model to generate a meaningful intermediate representation of the image's content - to improve the accuracy and reliability of the final captions.
Plain English Explanation
Vision-language models are AI systems that can look at an image and describe what they see in words. However, these models sometimes generate captions that sound reasonable but don't accurately reflect the actual contents of the image. This is known as "hallucination," and it's a major problem that limits the usefulness of these AI systems.
The researchers in this paper tried a new approach to address hallucination. Instead of just training the model to directly generate captions, they first taught it to create an intermediate, semantic representation of the image's key contents. This semantic representation captures the important concepts and relationships in the image in a more structured way.
By forcing the model to go through this semantic reconstruction step, the researchers found they could significantly reduce the incidence of hallucinated captions. The model was better able to ground its language outputs in the actual visual information, rather than just generating fluent but inaccurate text.
This is an important advance because it brings vision-language models one step closer to being reliable and trustworthy for real-world applications like image captioning, visual question answering, and multimodal understanding. Mitigating hallucinations is crucial for these AI systems to be safely deployed in high-stakes domains.
Technical Explanation
The paper proposes a new approach called Semantic Reconstruction to Mitigate Hallucinations (SLPL-SHROOM) to address the problem of hallucination in vision-language models.
At a high level, the key innovation is to introduce an intermediate semantic representation that the model must learn to predict from the input image, before generating the final textual caption. This semantic representation captures the key objects, attributes, and relationships present in the visual scene in a structured way.
Specifically, the model is trained on two parallel tasks: 1) predicting the semantic representation from the image, and 2) generating the final caption conditioned on both the image and the predicted semantic representation. By requiring the model to go through this semantic bottleneck, the researchers found they could significantly reduce the incidence of hallucinated captions.
The approach builds on prior work on detecting and mitigating hallucination in large vision-language models and leveraging semantic representations to improve text summarization. The key novelty is applying these ideas specifically to the problem of vision-language generation, with the goal of enhancing the reliability and safety of these AI systems.
Critical Analysis
The researchers acknowledge several limitations and areas for future work. First, the proposed approach relies on having access to high-quality semantic annotations for the training data, which may not always be available. They suggest exploring ways to learn the semantic representations in a more self-supervised manner.
Additionally, the paper focuses on evaluating the approach on standard image captioning benchmarks, but does not examine its performance on more open-ended, real-world vision-language tasks that may be more prone to hallucination, such as open-vocabulary image captioning. Further research is needed to understand the broader applicability of the technique.
Finally, the paper does not provide a deep analysis of the types of hallucinations the approach is most effective at mitigating. A more nuanced understanding of the failure modes the semantic reconstruction helps address would be valuable for continuing to refine and improve the technique.
Overall, this work represents an important step forward in enhancing the reliability and safety of vision-language models, but there remains significant room for further research and development in this critical area.
Conclusion
This paper presents a novel approach called Semantic Reconstruction to Mitigate Hallucinations (SLPL-SHROOM) for addressing the problem of hallucination in vision-language models. By introducing an intermediate semantic representation that the model must learn to predict from images, the researchers were able to significantly reduce the incidence of factually incorrect captions.
This work represents an important advance towards building more trustworthy and reliable AI systems for applications like image captioning, visual question answering, and multimodal understanding. Mitigating hallucinations is a crucial step for enabling the safe and responsible deployment of these technologies in high-stakes domains.
While the results are promising, the paper also highlights several areas for future research, such as exploring more self-supervised approaches to learning the semantic representations and evaluating the technique on a broader range of vision-language tasks. Continued progress in this direction holds the potential to greatly enhance the practical usefulness and real-world impact of AI-powered vision-language systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Exploiting Semantic Reconstruction to Mitigate Hallucinations in Vision-Language Models
Minchan Kim, Minyeong Kim, Junik Bae, Suhwan Choi, Sungkyung Kim, Buru Chang
Hallucinations in vision-language models pose a significant challenge to their reliability, particularly in the generation of long captions. Current methods fall short of accurately identifying and mitigating these hallucinations. To address this issue, we introduce ESREAL, a novel unsupervised learning framework designed to suppress the generation of hallucinations through accurate localization and penalization of hallucinated tokens. Initially, ESREAL creates a reconstructed image based on the generated caption and aligns its corresponding regions with those of the original image. This semantic reconstruction aids in identifying both the presence and type of token-level hallucinations within the generated caption. Subsequently, ESREAL computes token-level hallucination scores by assessing the semantic similarity of aligned regions based on the type of hallucination. Finally, ESREAL employs a proximal policy optimization algorithm, where it selectively penalizes hallucinated tokens according to their token-level hallucination scores. Our framework notably reduces hallucinations in LLaVA, InstructBLIP, and mPLUG-Owl2 by 32.81%, 27.08%, and 7.46% on the CHAIR metric. This improvement is achieved solely through signals derived from the image itself, without the need for any image-text pairs.
Read more5/7/2024

0
A Unified Hallucination Mitigation Framework for Large Vision-Language Models
Yue Chang, Liqiang Jing, Xiaopeng Zhang, Yue Zhang
Hallucination is a common problem for Large Vision-Language Models (LVLMs) with long generations which is difficult to eradicate. The generation with hallucinations is partially inconsistent with the image content. To mitigate hallucination, current studies either focus on the process of model inference or the results of model generation, but the solutions they design sometimes do not deal appropriately with various types of queries and the hallucinations of the generations about these queries. To accurately deal with various hallucinations, we present a unified framework, Dentist, for hallucination mitigation. The core step is to first classify the queries, then perform different processes of hallucination mitigation based on the classification result, just like a dentist first observes the teeth and then makes a plan. In a simple deployment, Dentist can classify queries as perception or reasoning and easily mitigate potential hallucinations in answers which has been demonstrated in our experiments. On MMbench, we achieve a 13.44%/10.2%/15.8% improvement in accuracy on Image Quality, a Coarse Perception visual question answering (VQA) task, over the baseline InstructBLIP/LLaVA/VisualGLM.
Read more9/26/2024
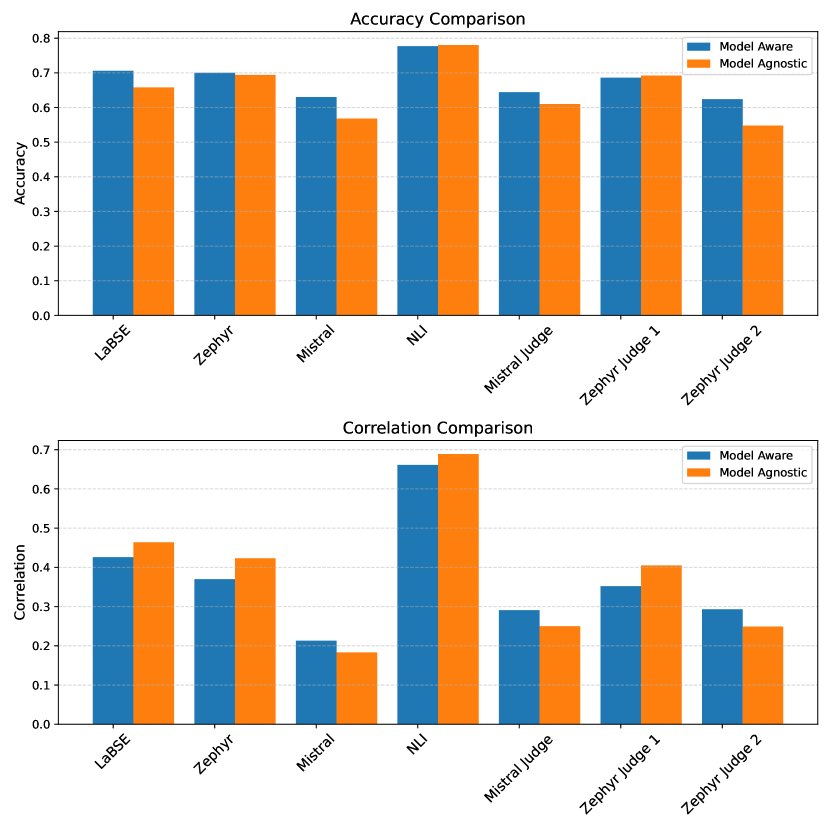
0
SLPL SHROOM at SemEval-2024 Task 06: A comprehensive study on models ability to detect hallucination
Pouya Fallah, Soroush Gooran, Mohammad Jafarinasab, Pouya Sadeghi, Reza Farnia, Amirreza Tarabkhah, Zainab Sadat Taghavi, Hossein Sameti
Language models, particularly generative models, are susceptible to hallucinations, generating outputs that contradict factual knowledge or the source text. This study explores methods for detecting hallucinations in three SemEval-2024 Task 6 tasks: Machine Translation, Definition Modeling, and Paraphrase Generation. We evaluate two methods: semantic similarity between the generated text and factual references, and an ensemble of language models that judge each other's outputs. Our results show that semantic similarity achieves moderate accuracy and correlation scores in trial data, while the ensemble method offers insights into the complexities of hallucination detection but falls short of expectations. This work highlights the challenges of hallucination detection and underscores the need for further research in this critical area.
Read more4/10/2024

0
Semantic Entropy Probes: Robust and Cheap Hallucination Detection in LLMs
Jannik Kossen, Jiatong Han, Muhammed Razzak, Lisa Schut, Shreshth Malik, Yarin Gal
We propose semantic entropy probes (SEPs), a cheap and reliable method for uncertainty quantification in Large Language Models (LLMs). Hallucinations, which are plausible-sounding but factually incorrect and arbitrary model generations, present a major challenge to the practical adoption of LLMs. Recent work by Farquhar et al. (2024) proposes semantic entropy (SE), which can detect hallucinations by estimating uncertainty in the space semantic meaning for a set of model generations. However, the 5-to-10-fold increase in computation cost associated with SE computation hinders practical adoption. To address this, we propose SEPs, which directly approximate SE from the hidden states of a single generation. SEPs are simple to train and do not require sampling multiple model generations at test time, reducing the overhead of semantic uncertainty quantification to almost zero. We show that SEPs retain high performance for hallucination detection and generalize better to out-of-distribution data than previous probing methods that directly predict model accuracy. Our results across models and tasks suggest that model hidden states capture SE, and our ablation studies give further insights into the token positions and model layers for which this is the case.
Read more6/26/2024