HALO: Hallucination Analysis and Learning Optimization to Empower LLMs with Retrieval-Augmented Context for Guided Clinical Decision Making

0

Sign in to get full access
Overview
- HALO is a system that aims to empower large language models (LLMs) with retrieval-augmented context for guided clinical decision making.
- It focuses on addressing the challenge of hallucination in LLMs, which is when the model generates factually incorrect information.
- The paper presents a novel approach for hallucination analysis and learning optimization to improve the reliability of LLMs in medical applications.
Plain English Explanation
HALO is a new system that is designed to help large language models (LLMs) make more accurate and reliable decisions in the medical field. LLMs are a type of AI that can generate human-like text, but they sometimes produce information that is not accurate or factual, which is called "hallucination."
The HALO system tries to solve this problem by using additional information, called "retrieval-augmented context," to guide the LLM in making better decisions. This extra information helps the LLM understand the context of the medical task better and avoid generating incorrect or made-up information.
The researchers who created HALO developed a novel approach for analyzing the hallucinations in LLMs and then optimizing the model's learning process to reduce these mistakes. This allows the LLM to become more reliable and trustworthy when making decisions that could impact people's health and well-being.
Technical Explanation
The HALO system aims to empower LLMs with retrieval-augmented context to improve their reliability in guided clinical decision making. The key components of the HALO approach include:
-
Hallucination Analysis: The researchers developed techniques to analyze and identify the types of hallucinations that occur in LLMs, such as factual errors, logical inconsistencies, and irrelevant or contradictory information.
-
Learning Optimization: Based on the hallucination analysis, HALO optimizes the LLM's learning process to minimize the generation of hallucinated content. This involves techniques like data augmentation, retrieval-based prompting, and adversarial training.
-
Retrieval-Augmented Context: HALO incorporates relevant background information and contextual data from external sources to provide the LLM with a more comprehensive understanding of the medical domain. This helps the model make more informed and reliable decisions.
The researchers conducted experiments to evaluate the effectiveness of HALO in improving the performance and reliability of LLMs on various medical tasks, such as clinical question answering and treatment recommendation. The results demonstrate that HALO can significantly reduce hallucination rates and enhance the overall quality of the LLM's outputs.
Critical Analysis
The HALO paper presents a promising approach to addressing the hallucination problem in LLMs, which is a critical issue for their adoption in sensitive domains like healthcare. The researchers' focus on hallucination analysis and learning optimization is a thoughtful and systematic approach to improving model reliability.
One potential limitation of the HALO system is the reliance on external retrieval-augmented context. While this can enhance the LLM's understanding, it also introduces additional complexity and potential sources of error. The researchers should further investigate the robustness of the retrieval process and the quality of the retrieved information.
Additionally, the paper does not discuss the computational cost or latency implications of the HALO system, which could be an important consideration for real-world clinical applications. The researchers may want to explore ways to optimize the system's efficiency and scalability.
Overall, the HALO approach represents a valuable contribution to the field of reliable and trustworthy AI systems for medical decision-making. Further research and development in this area could lead to significant advancements in the responsible use of LLMs in healthcare and other critical domains.
Conclusion
The HALO system proposes a novel approach to empower LLMs with retrieval-augmented context for guided clinical decision making. By addressing the hallucination problem through hallucination analysis and learning optimization, the researchers have demonstrated the potential to improve the reliability and trustworthiness of LLMs in the medical domain.
The HALO framework's focus on reducing factual errors, logical inconsistencies, and irrelevant information generation is a crucial step towards developing AI systems that can be safely and responsibly deployed in high-stakes applications. As the use of LLMs continues to expand, approaches like HALO will play an increasingly important role in ensuring the integrity and reliability of these powerful models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!HALO: Hallucination Analysis and Learning Optimization to Empower LLMs with Retrieval-Augmented Context for Guided Clinical Decision Making
Sumera Anjum, Hanzhi Zhang, Wenjun Zhou, Eun Jin Paek, Xiaopeng Zhao, Yunhe Feng
Large language models (LLMs) have significantly advanced natural language processing tasks, yet they are susceptible to generating inaccurate or unreliable responses, a phenomenon known as hallucination. In critical domains such as health and medicine, these hallucinations can pose serious risks. This paper introduces HALO, a novel framework designed to enhance the accuracy and reliability of medical question-answering (QA) systems by focusing on the detection and mitigation of hallucinations. Our approach generates multiple variations of a given query using LLMs and retrieves relevant information from external open knowledge bases to enrich the context. We utilize maximum marginal relevance scoring to prioritize the retrieved context, which is then provided to LLMs for answer generation, thereby reducing the risk of hallucinations. The integration of LangChain further streamlines this process, resulting in a notable and robust increase in the accuracy of both open-source and commercial LLMs, such as Llama-3.1 (from 44% to 65%) and ChatGPT (from 56% to 70%). This framework underscores the critical importance of addressing hallucinations in medical QA systems, ultimately improving clinical decision-making and patient care. The open-source HALO is available at: https://github.com/ResponsibleAILab/HALO.
Read more9/17/2024
💬
0
Towards Reliable Medical Question Answering: Techniques and Challenges in Mitigating Hallucinations in Language Models
Duy Khoa Pham, Bao Quoc Vo
The rapid advancement of large language models (LLMs) has significantly impacted various domains, including healthcare and biomedicine. However, the phenomenon of hallucination, where LLMs generate outputs that deviate from factual accuracy or context, poses a critical challenge, especially in high-stakes domains. This paper conducts a scoping study of existing techniques for mitigating hallucinations in knowledge-based task in general and especially for medical domains. Key methods covered in the paper include Retrieval-Augmented Generation (RAG)-based techniques, iterative feedback loops, supervised fine-tuning, and prompt engineering. These techniques, while promising in general contexts, require further adaptation and optimization for the medical domain due to its unique demands for up-to-date, specialized knowledge and strict adherence to medical guidelines. Addressing these challenges is crucial for developing trustworthy AI systems that enhance clinical decision-making and patient safety as well as accuracy of biomedical scientific research.
Read more8/27/2024

0
InterrogateLLM: Zero-Resource Hallucination Detection in LLM-Generated Answers
Yakir Yehuda, Itzik Malkiel, Oren Barkan, Jonathan Weill, Royi Ronen, Noam Koenigstein
Despite the many advances of Large Language Models (LLMs) and their unprecedented rapid evolution, their impact and integration into every facet of our daily lives is limited due to various reasons. One critical factor hindering their widespread adoption is the occurrence of hallucinations, where LLMs invent answers that sound realistic, yet drift away from factual truth. In this paper, we present a novel method for detecting hallucinations in large language models, which tackles a critical issue in the adoption of these models in various real-world scenarios. Through extensive evaluations across multiple datasets and LLMs, including Llama-2, we study the hallucination levels of various recent LLMs and demonstrate the effectiveness of our method to automatically detect them. Notably, we observe up to 87% hallucinations for Llama-2 in a specific experiment, where our method achieves a Balanced Accuracy of 81%, all without relying on external knowledge.
Read more8/20/2024
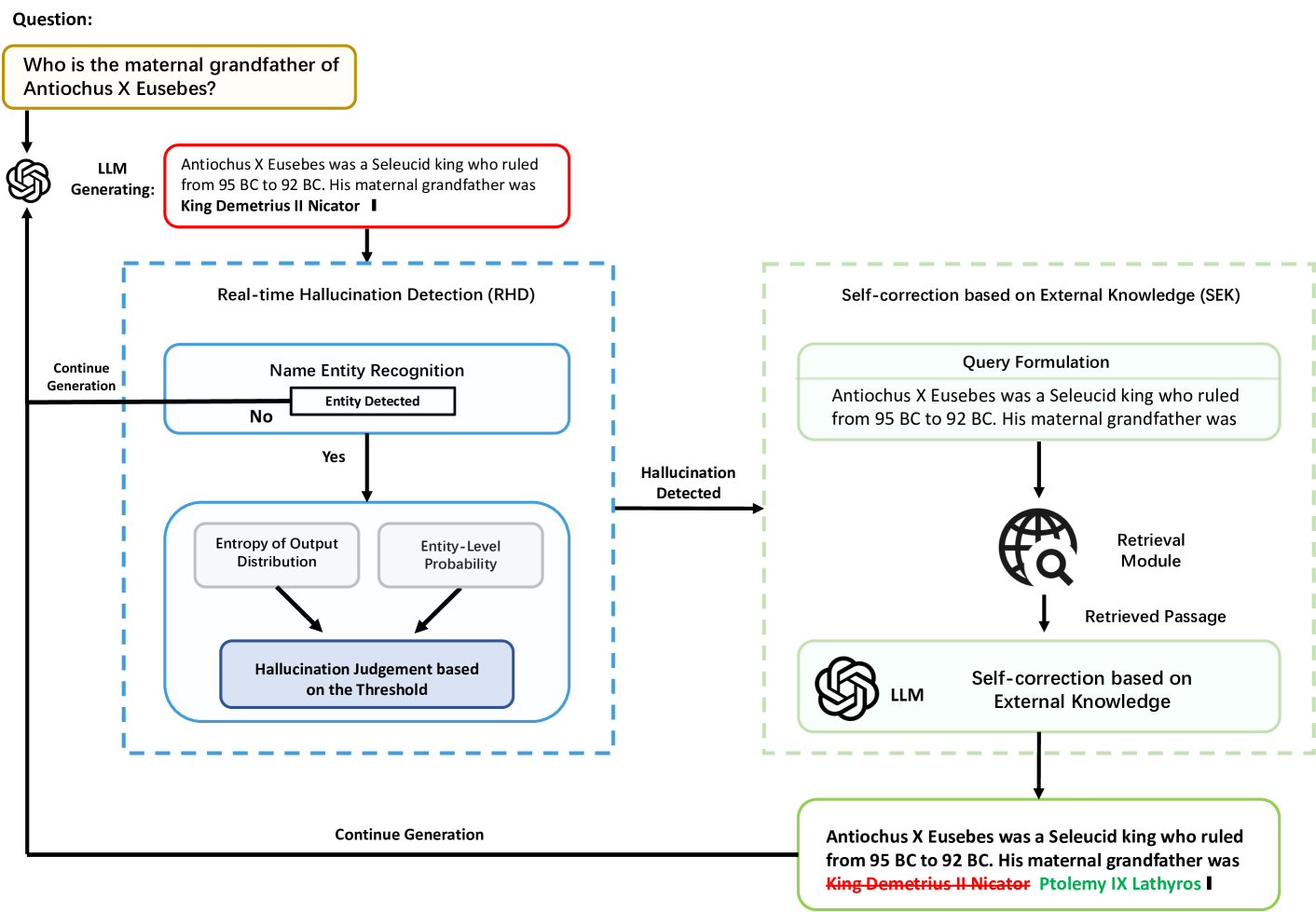
0
Mitigating Entity-Level Hallucination in Large Language Models
Weihang Su, Yichen Tang, Qingyao Ai, Changyue Wang, Zhijing Wu, Yiqun Liu
The emergence of Large Language Models (LLMs) has revolutionized how users access information, shifting from traditional search engines to direct question-and-answer interactions with LLMs. However, the widespread adoption of LLMs has revealed a significant challenge known as hallucination, wherein LLMs generate coherent yet factually inaccurate responses. This hallucination phenomenon has led to users' distrust in information retrieval systems based on LLMs. To tackle this challenge, this paper proposes Dynamic Retrieval Augmentation based on hallucination Detection (DRAD) as a novel method to detect and mitigate hallucinations in LLMs. DRAD improves upon traditional retrieval augmentation by dynamically adapting the retrieval process based on real-time hallucination detection. It features two main components: Real-time Hallucination Detection (RHD) for identifying potential hallucinations without external models, and Self-correction based on External Knowledge (SEK) for correcting these errors using external knowledge. Experiment results show that DRAD demonstrates superior performance in both detecting and mitigating hallucinations in LLMs. All of our code and data are open-sourced at https://github.com/oneal2000/EntityHallucination.
Read more7/23/2024