Towards Reliable Medical Question Answering: Techniques and Challenges in Mitigating Hallucinations in Language Models

0
💬
Sign in to get full access
Overview
- Large Language Models (LLMs) can be prone to "hallucinations" - generating outputs that appear plausible but are factually incorrect or nonsensical.
- This is a significant challenge for knowledge-based tasks, especially in sensitive domains like medical question answering.
- The paper explores techniques and challenges in mitigating hallucinations in LLMs to improve the reliability of medical question answering.
Plain English Explanation
Large language models (LLMs) are powerful AI systems that can generate human-like text on a wide range of topics. However, they can sometimes produce "hallucinations" - outputs that seem believable but are actually factually incorrect or nonsensical. This is a major problem when using LLMs for knowledge-based tasks, especially in sensitive domains like medical question answering, where reliable and accurate information is critical.
The research paper explores ways to address this challenge and make LLMs more reliable for medical question answering. It investigates different techniques that could help "mitigate" or reduce the likelihood of hallucinations from these models. The goal is to improve the trustworthiness and safety of using LLMs to provide medical information to users.
Technical Explanation
The paper first provides an overview of the challenge of hallucinations in LLMs, especially for knowledge-based tasks in sensitive domains like healthcare. It notes that while LLMs have made impressive advances, their tendency to produce plausible-sounding but factually incorrect outputs can undermine their reliability and safety for critical applications.
The authors then discuss several potential mitigation techniques that could help address this issue:
-
Knowledge-Grounding: Equipping the LLM with more comprehensive and accurate knowledge, either by fine-tuning on relevant datasets or integrating it with external knowledge bases.
-
Factual Consistency Checking: Developing methods to validate the factual consistency of the LLM's outputs, either through internal consistency checks or by cross-referencing external sources.
-
Hallucination Detection: Training models specifically to identify when the LLM is likely producing a hallucination, so that the output can be flagged or corrected.
-
Prompted Instruction-Following: Guiding the LLM's behavior through carefully crafted prompts that steer it towards more reliable and fact-based responses.
The paper also discusses the inherent challenges in mitigating hallucinations, such as the difficulty of defining and detecting them, the trade-offs between accuracy and safety, and the need for robust evaluation frameworks.
Critical Analysis
The paper provides a thoughtful and nuanced exploration of the challenges in mitigating hallucinations in LLMs, particularly for sensitive domains like medical question answering. The authors acknowledge the significant progress made in LLM capabilities, while also highlighting the critical importance of ensuring their reliability and safety.
One potential limitation of the research is that it primarily discusses potential mitigation techniques at a conceptual level, without providing detailed empirical evaluations of their effectiveness. While the authors touch on some existing work, more comprehensive testing and validation of these approaches would be valuable to assess their practical feasibility and real-world impact.
Additionally, the paper does not delve deeply into the underlying causes of hallucinations in LLMs, such as biases in the training data or flaws in the model architectures. A better understanding of the root causes could inform the development of more robust and lasting solutions.
Nevertheless, the paper serves as an important call to action for the AI research community to prioritize the challenge of hallucination mitigation, particularly in sensitive domains where the consequences of unreliable outputs can be severe. Continued progress in this area could significantly enhance the trustworthiness and real-world deployment of large language models.
Conclusion
This research paper highlights the critical challenge of hallucinations in large language models, especially for knowledge-based tasks in sensitive domains like medical question answering. It explores various mitigation techniques, such as knowledge-grounding, factual consistency checking, hallucination detection, and prompted instruction-following, as potential ways to improve the reliability and safety of LLMs in these contexts.
While the paper acknowledges the inherent difficulties in addressing hallucinations, it underscores the importance of continued research and innovation in this area. Reliable and trustworthy language models are essential for the safe and responsible deployment of AI technologies, particularly in high-stakes domains like healthcare. By addressing the hallucination problem, the research community can help unlock the full potential of LLMs and ensure their effective and ethical use in service of society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Towards Reliable Medical Question Answering: Techniques and Challenges in Mitigating Hallucinations in Language Models
Duy Khoa Pham, Bao Quoc Vo
The rapid advancement of large language models (LLMs) has significantly impacted various domains, including healthcare and biomedicine. However, the phenomenon of hallucination, where LLMs generate outputs that deviate from factual accuracy or context, poses a critical challenge, especially in high-stakes domains. This paper conducts a scoping study of existing techniques for mitigating hallucinations in knowledge-based task in general and especially for medical domains. Key methods covered in the paper include Retrieval-Augmented Generation (RAG)-based techniques, iterative feedback loops, supervised fine-tuning, and prompt engineering. These techniques, while promising in general contexts, require further adaptation and optimization for the medical domain due to its unique demands for up-to-date, specialized knowledge and strict adherence to medical guidelines. Addressing these challenges is crucial for developing trustworthy AI systems that enhance clinical decision-making and patient safety as well as accuracy of biomedical scientific research.
Read more8/27/2024

0
New!HALO: Hallucination Analysis and Learning Optimization to Empower LLMs with Retrieval-Augmented Context for Guided Clinical Decision Making
Sumera Anjum, Hanzhi Zhang, Wenjun Zhou, Eun Jin Paek, Xiaopeng Zhao, Yunhe Feng
Large language models (LLMs) have significantly advanced natural language processing tasks, yet they are susceptible to generating inaccurate or unreliable responses, a phenomenon known as hallucination. In critical domains such as health and medicine, these hallucinations can pose serious risks. This paper introduces HALO, a novel framework designed to enhance the accuracy and reliability of medical question-answering (QA) systems by focusing on the detection and mitigation of hallucinations. Our approach generates multiple variations of a given query using LLMs and retrieves relevant information from external open knowledge bases to enrich the context. We utilize maximum marginal relevance scoring to prioritize the retrieved context, which is then provided to LLMs for answer generation, thereby reducing the risk of hallucinations. The integration of LangChain further streamlines this process, resulting in a notable and robust increase in the accuracy of both open-source and commercial LLMs, such as Llama-3.1 (from 44% to 65%) and ChatGPT (from 56% to 70%). This framework underscores the critical importance of addressing hallucinations in medical QA systems, ultimately improving clinical decision-making and patient care. The open-source HALO is available at: https://github.com/ResponsibleAILab/HALO.
Read more9/17/2024
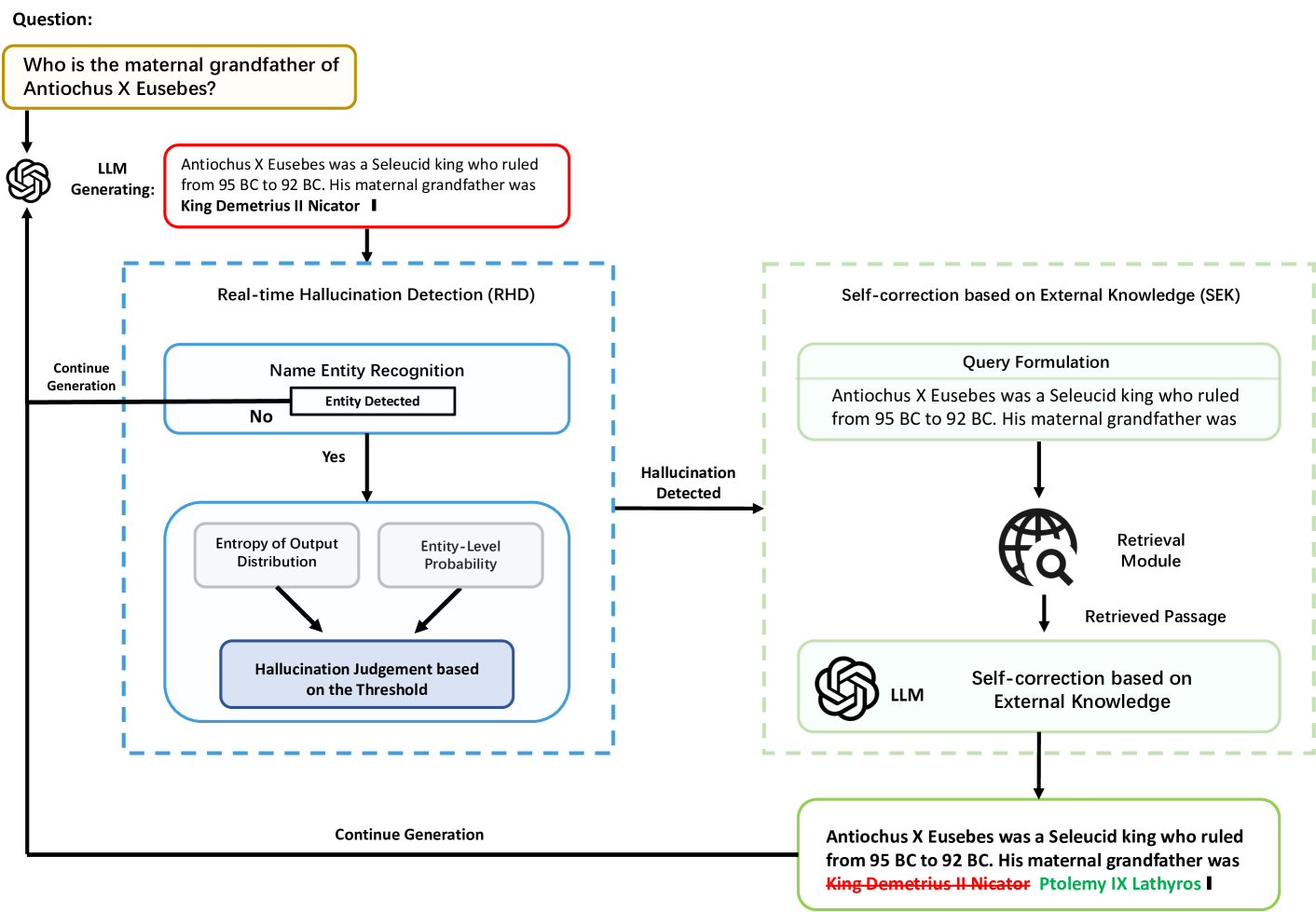
0
Mitigating Entity-Level Hallucination in Large Language Models
Weihang Su, Yichen Tang, Qingyao Ai, Changyue Wang, Zhijing Wu, Yiqun Liu
The emergence of Large Language Models (LLMs) has revolutionized how users access information, shifting from traditional search engines to direct question-and-answer interactions with LLMs. However, the widespread adoption of LLMs has revealed a significant challenge known as hallucination, wherein LLMs generate coherent yet factually inaccurate responses. This hallucination phenomenon has led to users' distrust in information retrieval systems based on LLMs. To tackle this challenge, this paper proposes Dynamic Retrieval Augmentation based on hallucination Detection (DRAD) as a novel method to detect and mitigate hallucinations in LLMs. DRAD improves upon traditional retrieval augmentation by dynamically adapting the retrieval process based on real-time hallucination detection. It features two main components: Real-time Hallucination Detection (RHD) for identifying potential hallucinations without external models, and Self-correction based on External Knowledge (SEK) for correcting these errors using external knowledge. Experiment results show that DRAD demonstrates superior performance in both detecting and mitigating hallucinations in LLMs. All of our code and data are open-sourced at https://github.com/oneal2000/EntityHallucination.
Read more7/23/2024

0
Developing a Reliable, General-Purpose Hallucination Detection and Mitigation Service: Insights and Lessons Learned
Song Wang, Xun Wang, Jie Mei, Yujia Xie, Sean Muarray, Zhang Li, Lingfeng Wu, Si-Qing Chen, Wayne Xiong
Hallucination, a phenomenon where large language models (LLMs) produce output that is factually incorrect or unrelated to the input, is a major challenge for LLM applications that require accuracy and dependability. In this paper, we introduce a reliable and high-speed production system aimed at detecting and rectifying the hallucination issue within LLMs. Our system encompasses named entity recognition (NER), natural language inference (NLI), span-based detection (SBD), and an intricate decision tree-based process to reliably detect a wide range of hallucinations in LLM responses. Furthermore, our team has crafted a rewriting mechanism that maintains an optimal mix of precision, response time, and cost-effectiveness. We detail the core elements of our framework and underscore the paramount challenges tied to response time, availability, and performance metrics, which are crucial for real-world deployment of these technologies. Our extensive evaluation, utilizing offline data and live production traffic, confirms the efficacy of our proposed framework and service.
Read more7/23/2024