Mitigating Entity-Level Hallucination in Large Language Models

0
Sign in to get full access
Overview
- The paper explores ways to mitigate "entity-level hallucination" in large language models, which is the tendency of these models to generate incorrect or nonsensical information about specific entities (e.g., people, places, organizations).
- The authors propose a novel approach called "Retrieval Augmented Generation" (RAG) that combines large language models with a retrieval component to improve the accuracy and reliability of the generated outputs.
- The paper presents experimental results demonstrating the effectiveness of the RAG approach in reducing entity-level hallucination compared to standard language models.
Plain English Explanation
Large language models, such as GPT-3 and BERT, have become incredibly powerful at generating human-like text on a wide range of topics. However, these models can sometimes "hallucinate" - generating information that is factually incorrect or nonsensical, especially when it comes to specific entities like people, places, or organizations.
The researchers in this paper wanted to find a way to fix this problem. They developed a new approach called "Retrieval Augmented Generation" (RAG) that combines a large language model with a separate retrieval component. The idea is that the retrieval component can provide the language model with more accurate information about entities, which can help the model generate more reliable and truthful outputs.
In their experiments, the researchers showed that the RAG approach was better at reducing entity-level hallucination compared to using a standard language model on its own. This is an important step in making these powerful language models more trustworthy and useful for real-world applications.
Technical Explanation
The key innovation in this paper is the "Retrieval Augmented Generation" (RAG) approach, which integrates a large language model with a retrieval component. The language model is responsible for generating the text, while the retrieval component searches a knowledge base to find relevant information about entities mentioned in the input.
The authors evaluated the RAG approach on several benchmark datasets for detecting and mitigating entity-level hallucination. Their results showed that the RAG model outperformed standard language models in terms of reducing hallucinated content, while maintaining similar performance on other language tasks.
Importantly, the authors found that the RAG model was particularly effective at correcting hallucinations related to proper nouns (e.g., people, places, organizations), which are a common source of errors in language models. They attribute this to the retrieval component's ability to surface accurate factual information about these entities.
The authors also explored different ways of training and configuring the RAG model, such as using different knowledge bases and retrieval strategies. Their analysis provides insights into the tradeoffs and design choices involved in building effective retrieval-augmented language models.
Critical Analysis
One limitation of the RAG approach discussed in the paper is that it relies on having access to a high-quality knowledge base that covers a broad range of entities and topics. In real-world applications, building and maintaining such a knowledge base can be challenging and expensive.
The authors also acknowledge that their evaluation focused primarily on entity-level hallucination, and there may be other types of hallucination or reliability issues that the RAG model does not address as effectively. Further research is needed to understand the broader robustness and safety properties of retrieval-augmented language models.
Additionally, the paper does not explore the potential privacy and ethical concerns around using large language models that have access to personal or sensitive information from knowledge bases. This is an important consideration for real-world deployments of these technologies.
Overall, this paper makes a valuable contribution to the growing body of research on mitigating hallucination and improving the reliability of large language models. The RAG approach represents a promising direction, but there are still many open challenges and areas for further investigation.
Conclusion
In this paper, the authors present a novel approach called "Retrieval Augmented Generation" (RAG) that combines a large language model with a retrieval component to mitigate entity-level hallucination. Their experimental results demonstrate the effectiveness of the RAG approach in reducing factual errors and generating more accurate and reliable outputs, particularly for text involving specific entities.
The RAG model represents an important step towards building more trustworthy and reliable large language models, which have become increasingly prevalent in a wide range of applications. By integrating retrieval capabilities, the authors have shown that it is possible to leverage external knowledge to improve the factual accuracy of language model outputs.
While the paper focuses on entity-level hallucination, the broader challenge of ensuring the safety and robustness of large language models remains an active area of research. As these models continue to evolve and be deployed in high-stakes applications, it will be crucial to develop further techniques for detecting and mitigating a wide range of reliability and safety issues.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Mitigating Entity-Level Hallucination in Large Language Models
Weihang Su, Yichen Tang, Qingyao Ai, Changyue Wang, Zhijing Wu, Yiqun Liu
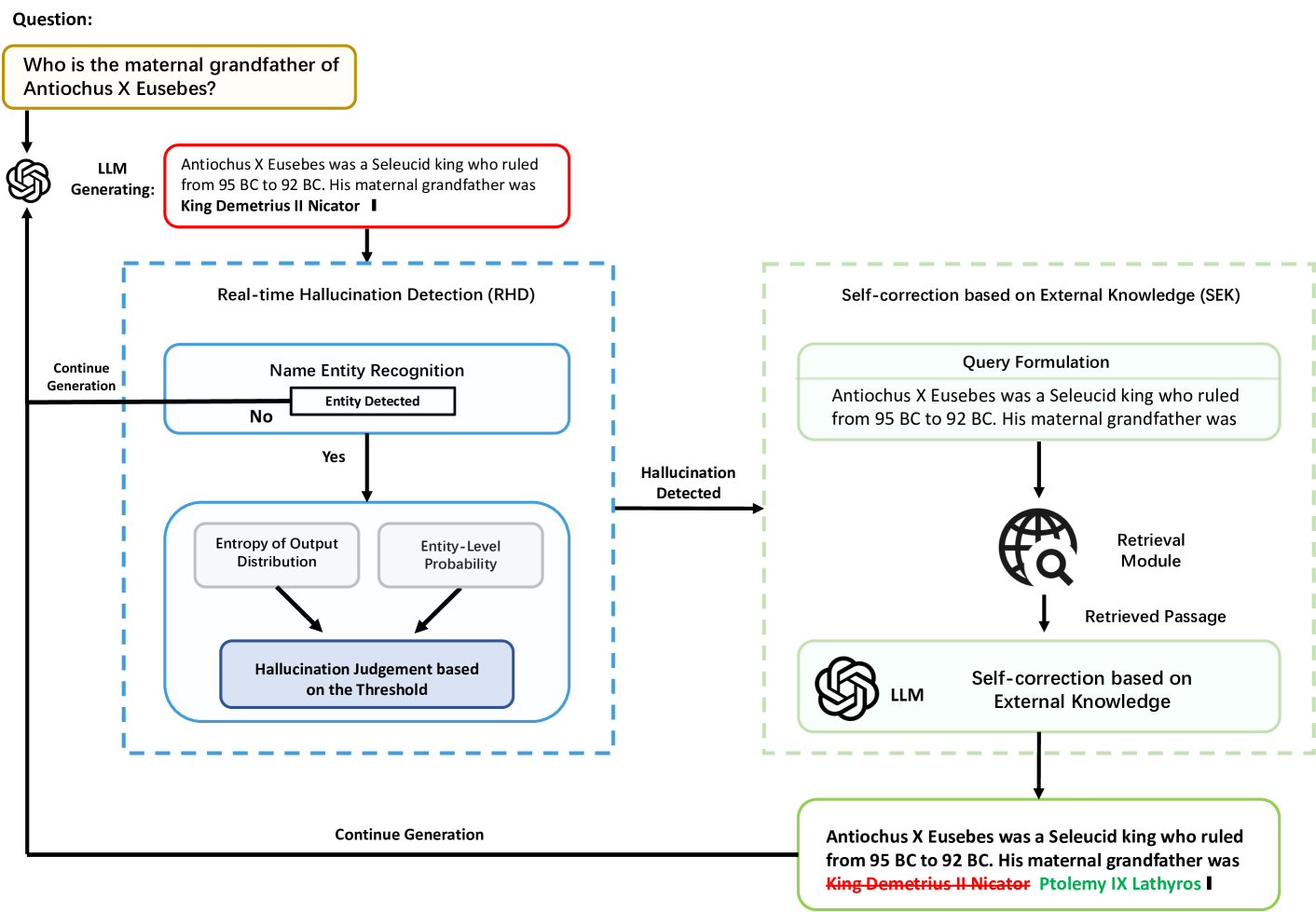
The emergence of Large Language Models (LLMs) has revolutionized how users access information, shifting from traditional search engines to direct question-and-answer interactions with LLMs. However, the widespread adoption of LLMs has revealed a significant challenge known as hallucination, wherein LLMs generate coherent yet factually inaccurate responses. This hallucination phenomenon has led to users' distrust in information retrieval systems based on LLMs. To tackle this challenge, this paper proposes Dynamic Retrieval Augmentation based on hallucination Detection (DRAD) as a novel method to detect and mitigate hallucinations in LLMs. DRAD improves upon traditional retrieval augmentation by dynamically adapting the retrieval process based on real-time hallucination detection. It features two main components: Real-time Hallucination Detection (RHD) for identifying potential hallucinations without external models, and Self-correction based on External Knowledge (SEK) for correcting these errors using external knowledge. Experiment results show that DRAD demonstrates superior performance in both detecting and mitigating hallucinations in LLMs. All of our code and data are open-sourced at https://github.com/oneal2000/EntityHallucination.
Read more7/23/2024

0
Hallucination Detection: Robustly Discerning Reliable Answers in Large Language Models
Yuyan Chen, Qiang Fu, Yichen Yuan, Zhihao Wen, Ge Fan, Dayiheng Liu, Dongmei Zhang, Zhixu Li, Yanghua Xiao
Large Language Models (LLMs) have gained widespread adoption in various natural language processing tasks, including question answering and dialogue systems. However, a major drawback of LLMs is the issue of hallucination, where they generate unfaithful or inconsistent content that deviates from the input source, leading to severe consequences. In this paper, we propose a robust discriminator named RelD to effectively detect hallucination in LLMs' generated answers. RelD is trained on the constructed RelQA, a bilingual question-answering dialogue dataset along with answers generated by LLMs and a comprehensive set of metrics. Our experimental results demonstrate that the proposed RelD successfully detects hallucination in the answers generated by diverse LLMs. Moreover, it performs well in distinguishing hallucination in LLMs' generated answers from both in-distribution and out-of-distribution datasets. Additionally, we also conduct a thorough analysis of the types of hallucinations that occur and present valuable insights. This research significantly contributes to the detection of reliable answers generated by LLMs and holds noteworthy implications for mitigating hallucination in the future work.
Read more7/8/2024
0
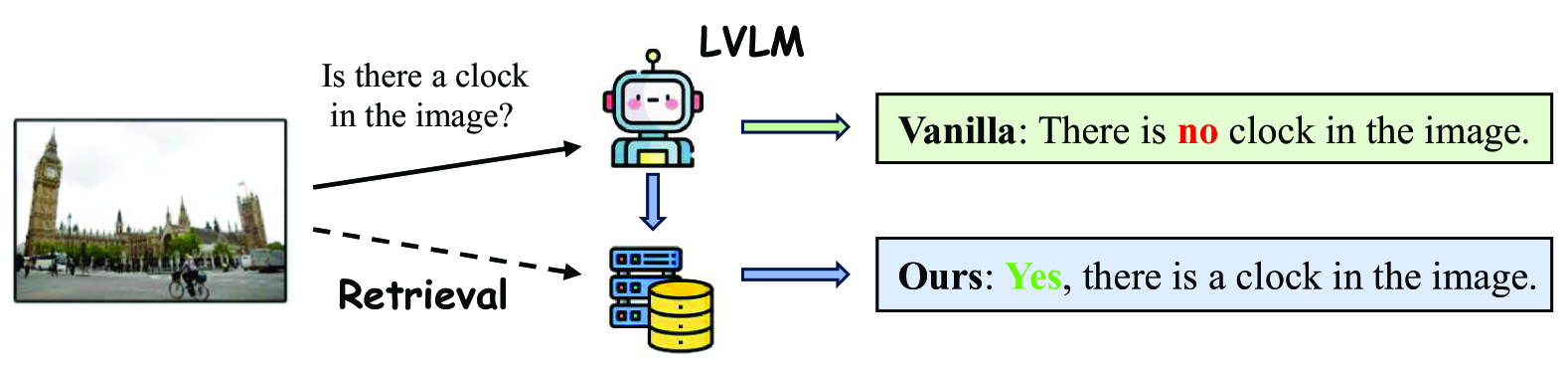
Alleviating Hallucination in Large Vision-Language Models with Active Retrieval Augmentation
Xiaoye Qu, Qiyuan Chen, Wei Wei, Jishuo Sun, Jianfeng Dong
Despite the remarkable ability of large vision-language models (LVLMs) in image comprehension, these models frequently generate plausible yet factually incorrect responses, a phenomenon known as hallucination.Recently, in large language models (LLMs), augmenting LLMs by retrieving information from external knowledge resources has been proven as a promising solution to mitigate hallucinations.However, the retrieval augmentation in LVLM significantly lags behind the widespread applications of LVLM. Moreover, when transferred to augmenting LVLMs, sometimes the hallucination degree of the model is even exacerbated.Motivated by the research gap and counter-intuitive phenomenon, we introduce a novel framework, the Active Retrieval-Augmented large vision-language model (ARA), specifically designed to address hallucinations by incorporating three critical dimensions: (i) dissecting the retrieval targets based on the inherent hierarchical structures of images. (ii) pinpointing the most effective retrieval methods and filtering out the reliable retrieval results. (iii) timing the retrieval process to coincide with episodes of low certainty, while circumventing unnecessary retrieval during periods of high certainty. To assess the capability of our proposed ARA model in reducing hallucination, we employ three widely used LVLM models (LLaVA-1.5, Qwen-VL, and mPLUG-Owl2) across four benchmarks. Our empirical observations suggest that by utilizing fitting retrieval mechanisms and timing the retrieval judiciously, we can effectively mitigate the hallucination problem. We hope that this study can provide deeper insights into how to adapt the retrieval augmentation to LVLMs for reducing hallucinations with more effective retrieval and minimal retrieval occurrences.
Read more8/2/2024

0
Developing a Reliable, General-Purpose Hallucination Detection and Mitigation Service: Insights and Lessons Learned
Song Wang, Xun Wang, Jie Mei, Yujia Xie, Sean Muarray, Zhang Li, Lingfeng Wu, Si-Qing Chen, Wayne Xiong
Hallucination, a phenomenon where large language models (LLMs) produce output that is factually incorrect or unrelated to the input, is a major challenge for LLM applications that require accuracy and dependability. In this paper, we introduce a reliable and high-speed production system aimed at detecting and rectifying the hallucination issue within LLMs. Our system encompasses named entity recognition (NER), natural language inference (NLI), span-based detection (SBD), and an intricate decision tree-based process to reliably detect a wide range of hallucinations in LLM responses. Furthermore, our team has crafted a rewriting mechanism that maintains an optimal mix of precision, response time, and cost-effectiveness. We detail the core elements of our framework and underscore the paramount challenges tied to response time, availability, and performance metrics, which are crucial for real-world deployment of these technologies. Our extensive evaluation, utilizing offline data and live production traffic, confirms the efficacy of our proposed framework and service.
Read more7/23/2024