Handling Long-Term Safety and Uncertainty in Safe Reinforcement Learning

0
🏅
Sign in to get full access
Overview
- Reinforcement learning is a powerful technique for training robots, but deploying it in the real world is challenging due to safety concerns.
- Most existing approaches in "Safe Reinforcement Learning" do not require prior knowledge of constraints or robot kinematics, but struggle in complex real-world settings.
- Model-based approaches that incorporate prior knowledge of constraints and dynamics can deploy learning algorithms directly on real robots, but the safety constraints are often task-specific and difficult to obtain.
Plain English Explanation
The paper presents a new method called "ATACOM" that extends the safe exploration technique to handle long-term safety and uncertainty. ATACOM is able to learn the safety constraints directly from data, rather than requiring them to be specified upfront. This allows the algorithm to be deployed on real robots without the need for detailed modeling of the robot's constraints and dynamics.
The key innovation is the ability to learn the safety constraints during the training process, rather than relying on pre-defined constraints. This makes the approach more flexible and able to handle complex, real-world scenarios where the safety requirements may not be known in advance.
The paper shows that ATACOM can achieve performance that is competitive or superior to other state-of-the-art methods, while also maintaining safer behavior during the training process. This is an important step towards the deployment of reinforcement learning techniques in real-world robotic applications.
Technical Explanation
The paper proposes an extension to the ATACOM (Adaptive Trajectory-Aware Conservative Exploration) safe exploration method. ATACOM typically requires prior knowledge of the robot's constraints and dynamics, which can be difficult to obtain in complex real-world settings.
The authors introduce learnable constraints into the ATACOM framework, allowing the safety constraints to be learned directly from data during training, rather than being specified upfront. This is achieved by using a neural network to parameterize the safety constraints, which are then optimized alongside the reinforcement learning policy.
The key technical contributions are:
- Handling Long-Term Safety: The authors introduce a modified objective function that encourages the learned constraints to ensure long-term safety, rather than just focusing on immediate safety.
- Uncertainty Handling: The authors incorporate uncertainty estimates from the learned constraints into the decision-making process, allowing the agent to navigate the safety constraints more robustly.
The paper evaluates the proposed method on several simulated robotic tasks and demonstrates that it can achieve competitive or superior performance compared to other state-of-the-art safe reinforcement learning approaches, while also maintaining safer behavior during training.
Critical Analysis
The paper presents a promising approach to addressing the challenge of deploying reinforcement learning in real-world robotic applications, where safety is a critical concern. The ability to learn the safety constraints directly from data, rather than requiring them to be specified upfront, is a significant advantage.
However, the paper does not discuss the potential limitations or challenges of this approach. For example, it's unclear how well the method would scale to more complex real-world environments, where the safety constraints may be even more difficult to capture. Additionally, the paper does not explore the robustness of the learned constraints to changes in the environment or task, which would be an important consideration for real-world deployment.
Further research could investigate the generalization capabilities of the ATACOM method with learnable constraints, as well as explore ways to make the learning process more efficient and sample-efficient. Additionally, it would be valuable to see the method evaluated on physical robotic platforms, rather than just simulated environments, to better understand its practical limitations and challenges.
Conclusion
The paper presents a novel approach to safe reinforcement learning that addresses a key challenge in deploying these techniques in the real world. By introducing learnable constraints into the ATACOM framework, the method can adapt to complex, real-world scenarios where the safety requirements may not be known in advance.
The results demonstrate that this approach can achieve competitive performance while maintaining safer behavior during training, which is a significant step forward for the field of safe reinforcement learning. As robotic systems become more prevalent in our everyday lives, ensuring their safety will be crucial, and this research contributes to that important goal.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
New!Handling Long-Term Safety and Uncertainty in Safe Reinforcement Learning
Jonas Gunster, Puze Liu, Jan Peters, Davide Tateo
Safety is one of the key issues preventing the deployment of reinforcement learning techniques in real-world robots. While most approaches in the Safe Reinforcement Learning area do not require prior knowledge of constraints and robot kinematics and rely solely on data, it is often difficult to deploy them in complex real-world settings. Instead, model-based approaches that incorporate prior knowledge of the constraints and dynamics into the learning framework have proven capable of deploying the learning algorithm directly on the real robot. Unfortunately, while an approximated model of the robot dynamics is often available, the safety constraints are task-specific and hard to obtain: they may be too complicated to encode analytically, too expensive to compute, or it may be difficult to envision a priori the long-term safety requirements. In this paper, we bridge this gap by extending the safe exploration method, ATACOM, with learnable constraints, with a particular focus on ensuring long-term safety and handling of uncertainty. Our approach is competitive or superior to state-of-the-art methods in final performance while maintaining safer behavior during training.
Read more9/19/2024
0
Long and Short-Term Constraints Driven Safe Reinforcement Learning for Autonomous Driving
Xuemin Hu, Pan Chen, Yijun Wen, Bo Tang, Long Chen
Reinforcement learning (RL) has been widely used in decision-making and control tasks, but the risk is very high for the agent in the training process due to the requirements of interaction with the environment, which seriously limits its industrial applications such as autonomous driving systems. Safe RL methods are developed to handle this issue by constraining the expected safety violation costs as a training objective, but the occurring probability of an unsafe state is still high, which is unacceptable in autonomous driving tasks. Moreover, these methods are difficult to achieve a balance between the cost and return expectations, which leads to learning performance degradation for the algorithms. In this paper, we propose a novel algorithm based on the long and short-term constraints (LSTC) for safe RL. The short-term constraint aims to enhance the short-term state safety that the vehicle explores, while the long-term constraint enhances the overall safety of the vehicle throughout the decision-making process, both of which are jointly used to enhance the vehicle safety in the training process. In addition, we develop a safe RL method with dual-constraint optimization based on the Lagrange multiplier to optimize the training process for end-to-end autonomous driving. Comprehensive experiments were conducted on the MetaDrive simulator. Experimental results demonstrate that the proposed method achieves higher safety in continuous state and action tasks, and exhibits higher exploration performance in long-distance decision-making tasks compared with state-of-the-art methods.
Read more9/14/2024

0
Safe Reinforcement Learning on the Constraint Manifold: Theory and Applications
Puze Liu, Haitham Bou-Ammar, Jan Peters, Davide Tateo
Integrating learning-based techniques, especially reinforcement learning, into robotics is promising for solving complex problems in unstructured environments. However, most existing approaches are trained in well-tuned simulators and subsequently deployed on real robots without online fine-tuning. In this setting, the simulation's realism seriously impacts the deployment's success rate. Instead, learning with real-world interaction data offers a promising alternative: not only eliminates the need for a fine-tuned simulator but also applies to a broader range of tasks where accurate modeling is unfeasible. One major problem for on-robot reinforcement learning is ensuring safety, as uncontrolled exploration can cause catastrophic damage to the robot or the environment. Indeed, safety specifications, often represented as constraints, can be complex and non-linear, making safety challenging to guarantee in learning systems. In this paper, we show how we can impose complex safety constraints on learning-based robotics systems in a principled manner, both from theoretical and practical points of view. Our approach is based on the concept of the Constraint Manifold, representing the set of safe robot configurations. Exploiting differential geometry techniques, i.e., the tangent space, we can construct a safe action space, allowing learning agents to sample arbitrary actions while ensuring safety. We demonstrate the method's effectiveness in a real-world Robot Air Hockey task, showing that our method can handle high-dimensional tasks with complex constraints. Videos of the real robot experiments are available on the project website (https://puzeliu.github.io/TRO-ATACOM).
Read more4/16/2024
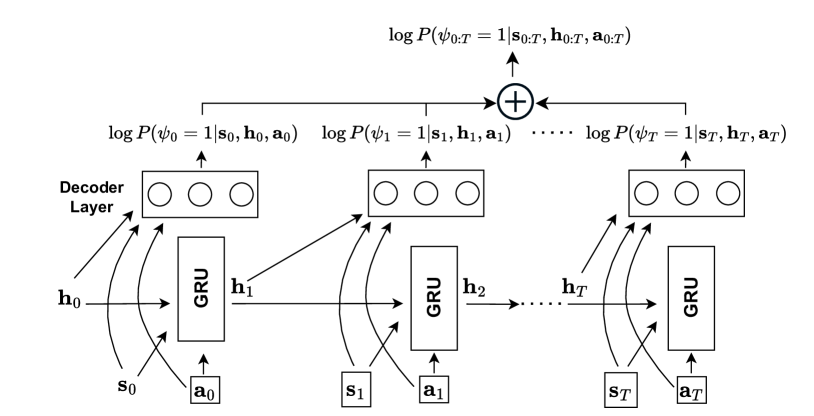
0
Safe Reinforcement Learning with Learned Non-Markovian Safety Constraints
Siow Meng Low, Akshat Kumar
In safe Reinforcement Learning (RL), safety cost is typically defined as a function dependent on the immediate state and actions. In practice, safety constraints can often be non-Markovian due to the insufficient fidelity of state representation, and safety cost may not be known. We therefore address a general setting where safety labels (e.g., safe or unsafe) are associated with state-action trajectories. Our key contributions are: first, we design a safety model that specifically performs credit assignment to assess contributions of partial state-action trajectories on safety. This safety model is trained using a labeled safety dataset. Second, using RL-as-inference strategy we derive an effective algorithm for optimizing a safe policy using the learned safety model. Finally, we devise a method to dynamically adapt the tradeoff coefficient between reward maximization and safety compliance. We rewrite the constrained optimization problem into its dual problem and derive a gradient-based method to dynamically adjust the tradeoff coefficient during training. Our empirical results demonstrate that this approach is highly scalable and able to satisfy sophisticated non-Markovian safety constraints.
Read more5/7/2024