Hard-Attention Gates with Gradient Routing for Endoscopic Image Computing

0

Sign in to get full access
Overview
- This paper proposes a novel deep learning architecture called "Hard-Attention Gates with Gradient Routing" for endoscopic image computing.
- The key ideas are Attention Gates, Hard-Attention Gates, Gradient Routing, and Feature Selection Gates, which are designed to improve feature selection and decision-making in medical image processing tasks.
- The proposed approach is evaluated on endoscopic image classification and segmentation tasks, demonstrating improved performance over existing methods.
Plain English Explanation
The paper introduces a new type of deep learning model that is designed to work well with medical images, particularly those captured during endoscopic procedures. Endoscopy is a medical procedure where a small camera is inserted into the body to examine internal organs.
The core idea behind this model is to selectively focus on the most relevant features in the medical images, rather than trying to process all the information equally. This is achieved through a novel component called "Attention Gates", which helps the model determine which parts of the image are most important for the task at hand, whether it's classifying the type of tissue or segmenting a particular structure.
The authors also introduce "Hard-Attention Gates" and "Gradient Routing", which further refine this feature selection process. The "Hard-Attention Gates" make decisive choices about which features to use, rather than blending them together. The "Gradient Routing" component helps to efficiently propagate the most useful information through the model.
Finally, the "Feature Selection Gates" provide an additional layer of control, allowing the model to dynamically adjust which features it focuses on as it processes the image. This helps the model adapt to the unique characteristics of each medical image.
Overall, this new architecture aims to make deep learning models for medical image analysis more effective and efficient by honing in on the most relevant information, rather than getting bogged down in irrelevant details. The authors demonstrate that this approach leads to improved performance on endoscopic image classification and segmentation tasks compared to existing methods.
Technical Explanation
The paper introduces a deep learning architecture called "Hard-Attention Gates with Gradient Routing" (HAG-GR) for endoscopic image computing. The key components are:
-
Attention Gates: These selectively focus the model's attention on the most relevant features in the input image, rather than processing all information equally.
-
Hard-Attention Gates: These make decisive choices about which features to use, rather than blending them together as in soft attention mechanisms.
-
Gradient Routing: This component efficiently propagates the most useful gradients through the network during training, guiding the model towards the most informative features.
-
Feature Selection Gates: These dynamically adjust which features the model focuses on as it processes the image, helping the model adapt to the unique characteristics of each medical image.
The authors evaluate the HAG-GR architecture on endoscopic image classification and segmentation tasks, and show that it outperforms existing methods. They attribute the improved performance to the model's ability to selectively attend to the most relevant features in the medical images.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed HAG-GR architecture, with experiments on multiple endoscopic image datasets and comparisons to state-of-the-art approaches. The authors acknowledge some limitations, such as the need for further research to understand the interpretability and generalization of the model's feature selection decisions.
One potential concern is the computational complexity of the model, particularly the Gradient Routing component, which may impact its real-world deployment in time-sensitive medical applications. The authors note that future work could explore ways to balance the performance gains with computational efficiency.
Additionally, while the paper demonstrates the effectiveness of the HAG-GR architecture on endoscopic images, it would be valuable to see how the approach generalizes to other types of medical imaging data, such as radiology or pathology images, to better understand its broader applicability.
Overall, the paper presents a promising new direction for medical image analysis, with the potential to improve the effectiveness and robustness of deep learning models in this domain. However, as with any new technology, further research and real-world deployment will be necessary to fully assess its impact and limitations.
Conclusion
The "Hard-Attention Gates with Gradient Routing" (HAG-GR) architecture proposed in this paper represents an innovative approach to improving deep learning for endoscopic image computing. By selectively focusing on the most relevant features in the medical images, the model is able to achieve better performance on tasks like image classification and segmentation.
The key ideas of Attention Gates, Hard-Attention Gates, Gradient Routing, and Feature Selection Gates provide a powerful set of tools for enhancing feature selection and decision-making in medical image processing. While the paper focuses on endoscopic images, the general principles could potentially be applied to other domains of medical imaging as well.
Overall, this research contributes to the ongoing efforts to make deep learning more effective and efficient in the critical field of healthcare. As medical imaging data continues to grow in volume and complexity, innovative architectures like HAG-GR will be increasingly important for extracting meaningful insights and supporting clinical decision-making.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Hard-Attention Gates with Gradient Routing for Endoscopic Image Computing
Giorgio Roffo, Carlo Biffi, Pietro Salvagnini, Andrea Cherubini
To address overfitting and enhance model generalization in gastroenterological polyp size assessment, our study introduces Feature-Selection Gates (FSG) or Hard-Attention Gates (HAG) alongside Gradient Routing (GR) for dynamic feature selection. This technique aims to boost Convolutional Neural Networks (CNNs) and Vision Transformers (ViTs) by promoting sparse connectivity, thereby reducing overfitting and enhancing generalization. HAG achieves this through sparsification with learnable weights, serving as a regularization strategy. GR further refines this process by optimizing HAG parameters via dual forward passes, independently from the main model, to improve feature re-weighting. Our evaluation spanned multiple datasets, including CIFAR-100 for a broad impact assessment and specialized endoscopic datasets (REAL-Colon, Misawa, and SUN) focusing on polyp size estimation, covering over 200 polyps in more than 370,000 frames. The findings indicate that our HAG-enhanced networks substantially enhance performance in both binary and triclass classification tasks related to polyp sizing. Specifically, CNNs experienced an F1 Score improvement to 87.8% in binary classification, while in triclass classification, the ViT-T model reached an F1 Score of 76.5%, outperforming traditional CNNs and ViT-T models. To facilitate further research, we are releasing our codebase, which includes implementations for CNNs, multistream CNNs, ViT, and HAG-augmented variants. This resource aims to standardize the use of endoscopic datasets, providing public training-validation-testing splits for reliable and comparable research in gastroenterological polyp size estimation. The codebase is available at github.com/cosmoimd/feature-selection-gates.
Read more7/8/2024
0
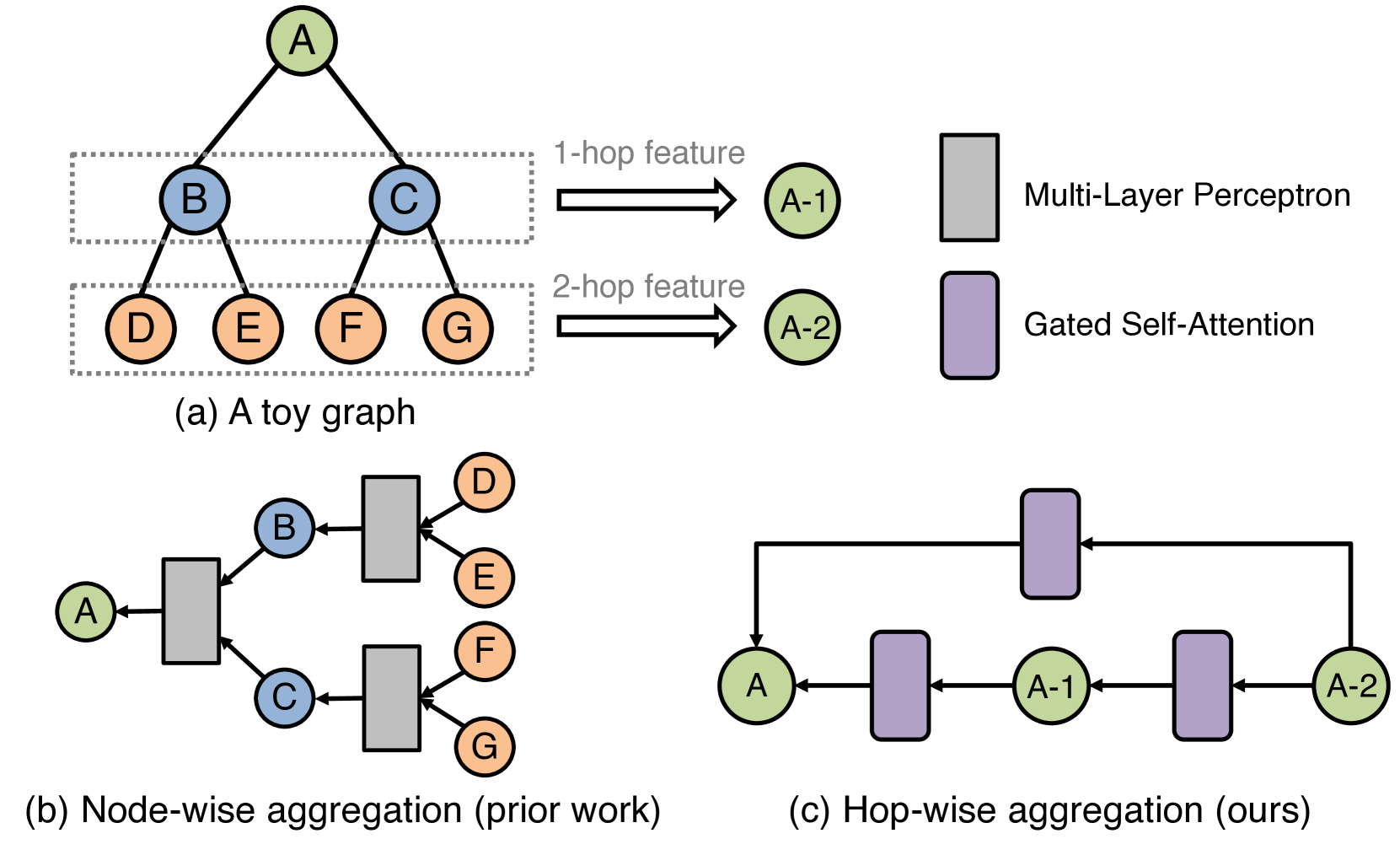
Less is More: Hop-Wise Graph Attention for Scalable and Generalizable Learning on Circuits
Chenhui Deng, Zichao Yue, Cunxi Yu, Gokce Sarar, Ryan Carey, Rajeev Jain, Zhiru Zhang
While graph neural networks (GNNs) have gained popularity for learning circuit representations in various electronic design automation (EDA) tasks, they face challenges in scalability when applied to large graphs and exhibit limited generalizability to new designs. These limitations make them less practical for addressing large-scale, complex circuit problems. In this work we propose HOGA, a novel attention-based model for learning circuit representations in a scalable and generalizable manner. HOGA first computes hop-wise features per node prior to model training. Subsequently, the hop-wise features are solely used to produce node representations through a gated self-attention module, which adaptively learns important features among different hops without involving the graph topology. As a result, HOGA is adaptive to various structures across different circuits and can be efficiently trained in a distributed manner. To demonstrate the efficacy of HOGA, we consider two representative EDA tasks: quality of results (QoR) prediction and functional reasoning. Our experimental results indicate that (1) HOGA reduces estimation error over conventional GNNs by 46.76% for predicting QoR after logic synthesis; (2) HOGA improves 10.0% reasoning accuracy over GNNs for identifying functional blocks on unseen gate-level netlists after complex technology mapping; (3) The training time for HOGA almost linearly decreases with an increase in computing resources.
Read more4/12/2024

0
Classification of Endoscopy and Video Capsule Images using CNN-Transformer Model
Aliza Subedi, Smriti Regmi, Nisha Regmi, Bhumi Bhusal, Ulas Bagci, Debesh Jha
Gastrointestinal cancer is a leading cause of cancer-related incidence and death, making it crucial to develop novel computer-aided diagnosis systems for early detection and enhanced treatment. Traditional approaches rely on the expertise of gastroenterologists to identify diseases; however, this process is subjective, and interpretation can vary even among expert clinicians. Considering recent advancements in classifying gastrointestinal anomalies and landmarks in endoscopic and video capsule endoscopy images, this study proposes a hybrid model that combines the advantages of Transformers and Convolutional Neural Networks (CNNs) to enhance classification performance. Our model utilizes DenseNet201 as a CNN branch to extract local features and integrates a Swin Transformer branch for global feature understanding, combining both to perform the classification task. For the GastroVision dataset, our proposed model demonstrates excellent performance with Precision, Recall, F1 score, Accuracy, and Matthews Correlation Coefficient (MCC) of 0.8320, 0.8386, 0.8324, 0.8386, and 0.8191, respectively, showcasing its robustness against class imbalance and surpassing other CNNs as well as the Swin Transformer model. Similarly, for the Kvasir-Capsule, a large video capsule endoscopy dataset, our model outperforms all others, achieving overall Precision, Recall, F1 score, Accuracy, and MCC of 0.7007, 0.7239, 0.6900, 0.7239, and 0.3871. Moreover, we generated saliency maps to explain our model's focus areas, demonstrating its reliable decision-making process. The results underscore the potential of our hybrid CNN-Transformer model in aiding the early and accurate detection of gastrointestinal (GI) anomalies.
Read more8/21/2024

0
Boosting Hyperspectral Image Classification with Gate-Shift-Fuse Mechanisms in a Novel CNN-Transformer Approach
Mohamed Fadhlallah Guerri, Cosimo Distante, Paolo Spagnolo, Fares Bougourzi, Abdelmalik Taleb-Ahmed
During the process of classifying Hyperspectral Image (HSI), every pixel sample is categorized under a land-cover type. CNN-based techniques for HSI classification have notably advanced the field by their adept feature representation capabilities. However, acquiring deep features remains a challenge for these CNN-based methods. In contrast, transformer models are adept at extracting high-level semantic features, offering a complementary strength. This paper's main contribution is the introduction of an HSI classification model that includes two convolutional blocks, a Gate-Shift-Fuse (GSF) block and a transformer block. This model leverages the strengths of CNNs in local feature extraction and transformers in long-range context modelling. The GSF block is designed to strengthen the extraction of local and global spatial-spectral features. An effective attention mechanism module is also proposed to enhance the extraction of information from HSI cubes. The proposed method is evaluated on four well-known datasets (the Indian Pines, Pavia University, WHU-WHU-Hi-LongKou and WHU-Hi-HanChuan), demonstrating that the proposed framework achieves superior results compared to other models.
Read more6/21/2024