HardVis: Visual Analytics to Handle Instance Hardness Using Undersampling and Oversampling Techniques

0
⛏️
Sign in to get full access
Overview
- Imbalanced data is a common challenge in machine learning (ML) applications.
- Sampling algorithms are often used as an efficient solution, but the problem is more fundamental, with instance hardness being an important factor.
- Instance hardness refers to instances that are more likely to be misclassified, which can negatively impact model performance.
- This paper introduces HardVis, a visual analytics system designed to help users handle instance hardness in imbalanced classification scenarios.
Plain English Explanation
HardVis is a tool that helps address the problem of imbalanced data in machine learning models. When a dataset has an uneven distribution of different types of examples, it can be hard for a model to learn effectively. HardVis allows users to explore the characteristics of their data and identify the "hard" instances that are most difficult for the model to classify correctly. These are often the instances that are on the boundaries between different classes or have unusual features.
With HardVis, users can select which instances they want to focus on and apply sampling techniques to balance the dataset. Rather than simply removing or duplicating examples from the majority or minority classes, HardVis allows users to target the specific instances that are causing the most problems. This can lead to a more effective and balanced dataset that improves the overall performance of the machine learning model.
Technical Explanation
The paper introduces HardVis, a visual analytics system designed to help users handle instance hardness in imbalanced classification scenarios. Instance hardness refers to the significance of managing unsafe or potentially noisy instances that are more likely to be misclassified and serve as the root cause of poor classification performance.
HardVis allows users to visually compare different distributions of data types, select types of instances based on local characteristics that will later be affected by the active sampling method, and validate which suggestions from undersampling or oversampling techniques are beneficial for the ML model. Rather than uniformly undersampling or oversampling a specific class, HardVis enables users to find and sample easy and difficult to classify training instances from all classes.
The paper demonstrates the efficacy and effectiveness of HardVis through a hypothetical usage scenario and a use case. Additionally, the authors provide feedback from ML experts on the usefulness of their system.
Critical Analysis
The paper provides a valuable contribution by addressing the fundamental issue of instance hardness in imbalanced classification scenarios, which is often overlooked in favor of more simplistic sampling techniques. However, the authors acknowledge that their approach may not be suitable for all types of imbalanced datasets, and that further research is needed to explore the generalizability of HardVis.
Additionally, while the paper demonstrates the utility of HardVis through a use case, the evaluation could be further strengthened by conducting a more comprehensive user study with a larger and more diverse group of ML practitioners. This would help validate the system's usability and effectiveness in real-world settings.
Conclusion
The HardVis system presented in this paper offers a novel approach to handling imbalanced data in machine learning. By focusing on instance hardness and providing visual analytics tools to help users understand and address this challenge, HardVis has the potential to significantly improve the performance of ML models in a wide range of applications. As the field of machine learning continues to evolve, tools like HardVis will become increasingly important for practitioners to effectively leverage the power of these technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
⛏️
0
HardVis: Visual Analytics to Handle Instance Hardness Using Undersampling and Oversampling Techniques
Angelos Chatzimparmpas, Fernando V. Paulovich, Andreas Kerren
Despite the tremendous advances in machine learning (ML), training with imbalanced data still poses challenges in many real-world applications. Among a series of diverse techniques to solve this problem, sampling algorithms are regarded as an efficient solution. However, the problem is more fundamental, with many works emphasizing the importance of instance hardness. This issue refers to the significance of managing unsafe or potentially noisy instances that are more likely to be misclassified and serve as the root cause of poor classification performance. This paper introduces HardVis, a visual analytics system designed to handle instance hardness mainly in imbalanced classification scenarios. Our proposed system assists users in visually comparing different distributions of data types, selecting types of instances based on local characteristics that will later be affected by the active sampling method, and validating which suggestions from undersampling or oversampling techniques are beneficial for the ML model. Additionally, rather than uniformly undersampling/oversampling a specific class, we allow users to find and sample easy and difficult to classify training instances from all classes. Users can explore subsets of data from different perspectives to decide all those parameters, while HardVis keeps track of their steps and evaluates the model's predictive performance in a test set separately. The end result is a well-balanced data set that boosts the predictive power of the ML model. The efficacy and effectiveness of HardVis are demonstrated with a hypothetical usage scenario and a use case. Finally, we also look at how useful our system is based on feedback we received from ML experts.
Read more4/19/2024
0
Restoring balance: principled under/oversampling of data for optimal classification
Emanuele Loffredo, Mauro Pastore, Simona Cocco, R'emi Monasson
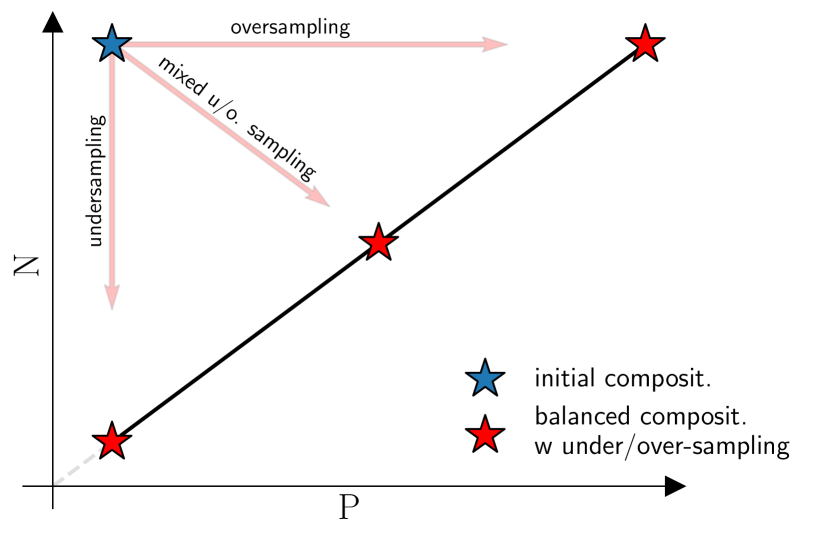
Class imbalance in real-world data poses a common bottleneck for machine learning tasks, since achieving good generalization on under-represented examples is often challenging. Mitigation strategies, such as under or oversampling the data depending on their abundances, are routinely proposed and tested empirically, but how they should adapt to the data statistics remains poorly understood. In this work, we determine exact analytical expressions of the generalization curves in the high-dimensional regime for linear classifiers (Support Vector Machines). We also provide a sharp prediction of the effects of under/oversampling strategies depending on class imbalance, first and second moments of the data, and the metrics of performance considered. We show that mixed strategies involving under and oversampling of data lead to performance improvement. Through numerical experiments, we show the relevance of our theoretical predictions on real datasets, on deeper architectures and with sampling strategies based on unsupervised probabilistic models.
Read more5/16/2024

0
HyperSMOTE: A Hypergraph-based Oversampling Approach for Imbalanced Node Classifications
Ziming Zhao, Tiehua Zhang, Zijian Yi, Zhishu Shen
Hypergraphs are increasingly utilized in both unimodal and multimodal data scenarios due to their superior ability to model and extract higher-order relationships among nodes, compared to traditional graphs. However, current hypergraph models are encountering challenges related to imbalanced data, as this imbalance can lead to biases in the model towards the more prevalent classes. While the existing techniques, such as GraphSMOTE, have improved classification accuracy for minority samples in graph data, they still fall short when addressing the unique structure of hypergraphs. Inspired by SMOTE concept, we propose HyperSMOTE as a solution to alleviate the class imbalance issue in hypergraph learning. This method involves a two-step process: initially synthesizing minority class nodes, followed by the nodes integration into the original hypergraph. We synthesize new nodes based on samples from minority classes and their neighbors. At the same time, in order to solve the problem on integrating the new node into the hypergraph, we train a decoder based on the original hypergraph incidence matrix to adaptively associate the augmented node to hyperedges. We conduct extensive evaluation on multiple single-modality datasets, such as Cora, Cora-CA and Citeseer, as well as multimodal conversation dataset MELD to verify the effectiveness of HyperSMOTE, showing an average performance gain of 3.38% and 2.97% on accuracy, respectively.
Read more9/10/2024

0
Synthetic Tabular Data Generation for Class Imbalance and Fairness: A Comparative Study
Emmanouil Panagiotou, Arjun Roy, Eirini Ntoutsi
Due to their data-driven nature, Machine Learning (ML) models are susceptible to bias inherited from data, especially in classification problems where class and group imbalances are prevalent. Class imbalance (in the classification target) and group imbalance (in protected attributes like sex or race) can undermine both ML utility and fairness. Although class and group imbalances commonly coincide in real-world tabular datasets, limited methods address this scenario. While most methods use oversampling techniques, like interpolation, to mitigate imbalances, recent advancements in synthetic tabular data generation offer promise but have not been adequately explored for this purpose. To this end, this paper conducts a comparative analysis to address class and group imbalances using state-of-the-art models for synthetic tabular data generation and various sampling strategies. Experimental results on four datasets, demonstrate the effectiveness of generative models for bias mitigation, creating opportunities for further exploration in this direction.
Read more9/10/2024