HarmonyDream: Task Harmonization Inside World Models
2310.00344
0
0
🧠
Abstract
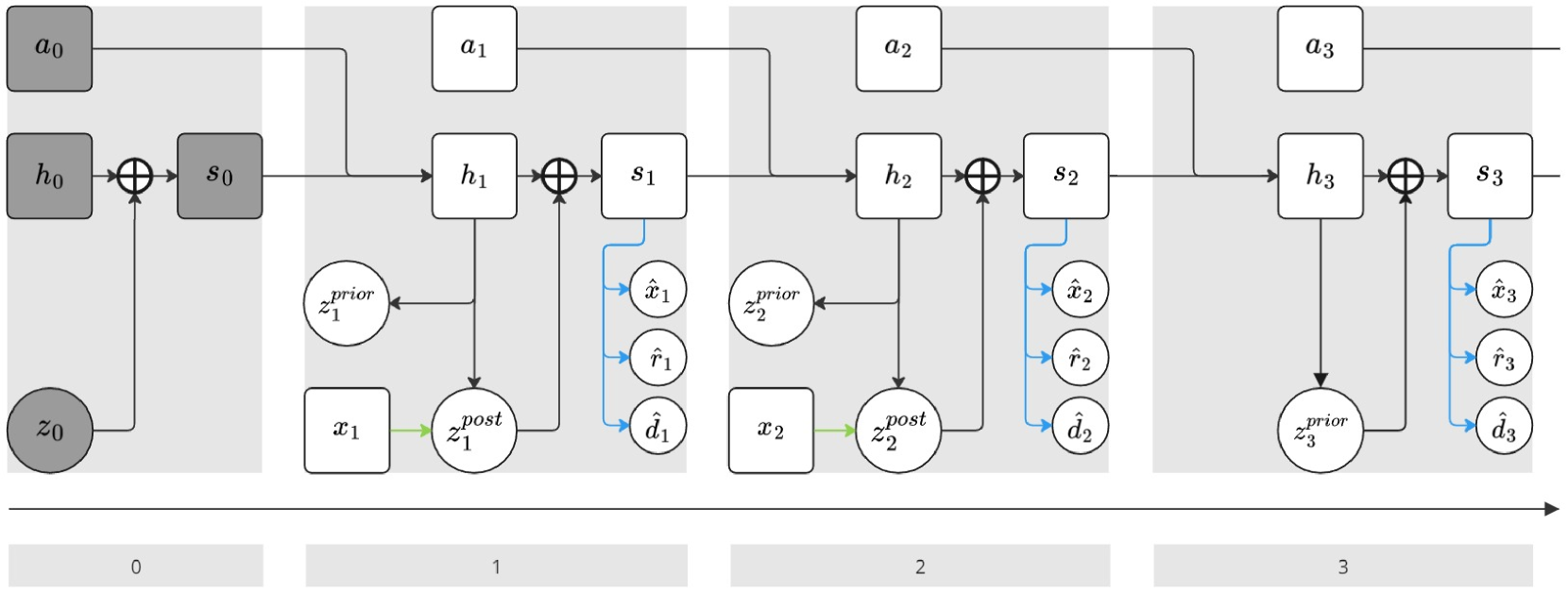
Model-based reinforcement learning (MBRL) holds the promise of sample-efficient learning by utilizing a world model, which models how the environment works and typically encompasses components for two tasks: observation modeling and reward modeling. In this paper, through a dedicated empirical investigation, we gain a deeper understanding of the role each task plays in world models and uncover the overlooked potential of sample-efficient MBRL by mitigating the domination of either observation or reward modeling. Our key insight is that while prevalent approaches of explicit MBRL attempt to restore abundant details of the environment via observation models, it is difficult due to the environment's complexity and limited model capacity. On the other hand, reward models, while dominating implicit MBRL and adept at learning compact task-centric dynamics, are inadequate for sample-efficient learning without richer learning signals. Motivated by these insights and discoveries, we propose a simple yet effective approach, HarmonyDream, which automatically adjusts loss coefficients to maintain task harmonization, i.e. a dynamic equilibrium between the two tasks in world model learning. Our experiments show that the base MBRL method equipped with HarmonyDream gains 10%-69% absolute performance boosts on visual robotic tasks and sets a new state-of-the-art result on the Atari 100K benchmark. Code is available at https://github.com/thuml/HarmonyDream.
Create account to get full access
Overview
- This paper explores the role of observation modeling and reward modeling in model-based reinforcement learning (MBRL) and proposes a novel approach to maintain a balance between the two.
- MBRL aims to learn a world model that can simulate the environment, which can then be used for sample-efficient learning.
- The paper finds that while prevalent MBRL methods focus on detailed observation modeling, it is challenging due to the complexity of the environment and limited model capacity.
- On the other hand, reward modeling, which is the focus of implicit MBRL, is more effective at learning compact task-centric dynamics but lacks the rich learning signals needed for sample-efficient learning.
Plain English Explanation
MBRL is a technique in reinforcement learning that tries to build a model of the environment, called a "world model", to help the agent learn more efficiently. The world model typically has two main components: one to predict the observations (what the agent sees) and one to predict the rewards (the signals the agent gets for performing well).
The paper's key insight is that current MBRL methods focus too much on accurately modeling the observations, which is difficult due to the complexity of real-world environments. This makes it hard for the agent to learn efficiently. On the other hand, modeling just the rewards, which is the focus of some other MBRL approaches, is not enough on its own to enable sample-efficient learning.
To address this, the paper proposes a new method called "HarmonyDream" that automatically adjusts the relative importance of observation modeling and reward modeling during the learning process. This helps maintain a balance between the two, allowing the agent to learn more effectively from the world model.
Technical Explanation
The paper conducts a dedicated empirical investigation to understand the roles of observation modeling and reward modeling in world models for MBRL. They find that prevalent explicit MBRL methods focus heavily on restoring detailed environment observations through observation models, but this is challenging due to the environment's complexity and limited model capacity. In contrast, reward models in implicit MBRL are more adept at learning compact task-centric dynamics, but lack the rich learning signals needed for sample-efficient learning.
Motivated by these insights, the authors propose a new approach called "HarmonyDream" that automatically adjusts the loss coefficients for observation modeling and reward modeling to maintain a dynamic equilibrium between the two tasks during world model learning. This "task harmonization" allows the MBRL agent to benefit from the complementary strengths of both modeling components.
The paper evaluates HarmonyDream on visual robotic tasks and the Atari 100K benchmark, showing that it can provide 10%-69% absolute performance boosts over base MBRL methods and set a new state-of-the-art result on the Atari 100K benchmark.
Critical Analysis
The paper provides valuable insights into the roles of observation and reward modeling in MBRL and proposes a novel approach to address the limitations of existing methods. However, the paper does not deeply explore the potential reasons why observation modeling is so challenging, nor does it investigate the specific tradeoffs between the two modeling tasks in different environments or problem settings.
Additionally, while the results on the Atari 100K benchmark are impressive, the paper does not discuss the scalability of HarmonyDream to more complex environments or its performance on a wider range of tasks. Further research would be needed to understand the broader applicability and limitations of the proposed method.
Overall, the paper makes a compelling case for the importance of balancing observation and reward modeling in MBRL and provides a promising solution in the form of HarmonyDream. However, there are still open questions and areas for further exploration to fully understand the potential and limitations of this approach.
Conclusion
This paper highlights the importance of maintaining a balance between observation modeling and reward modeling in model-based reinforcement learning (MBRL) and proposes a novel approach called HarmonyDream to achieve this. By automatically adjusting the relative importance of the two modeling tasks, HarmonyDream can help MBRL agents learn more efficiently from their world models, leading to significant performance improvements on visual robotic tasks and the Atari 100K benchmark.
The insights and discoveries in this paper contribute to our understanding of the key challenges and opportunities in MBRL, and the HarmonyDream method represents a promising step towards more sample-efficient reinforcement learning. Further research is needed to explore the broader applicability and limitations of this approach, but the paper's findings have important implications for the design of future MBRL systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Exploring the limits of Hierarchical World Models in Reinforcement Learning
Robin Schiewer, Anand Subramoney, Laurenz Wiskott
0
0
Hierarchical model-based reinforcement learning (HMBRL) aims to combine the benefits of better sample efficiency of model based reinforcement learning (MBRL) with the abstraction capability of hierarchical reinforcement learning (HRL) to solve complex tasks efficiently. While HMBRL has great potential, it still lacks wide adoption. In this work we describe a novel HMBRL framework and evaluate it thoroughly. To complement the multi-layered decision making idiom characteristic for HRL, we construct hierarchical world models that simulate environment dynamics at various levels of temporal abstraction. These models are used to train a stack of agents that communicate in a top-down manner by proposing goals to their subordinate agents. A significant focus of this study is the exploration of a static and environment agnostic temporal abstraction, which allows concurrent training of models and agents throughout the hierarchy. Unlike most goal-conditioned H(MB)RL approaches, it also leads to comparatively low dimensional abstract actions. Although our HMBRL approach did not outperform traditional methods in terms of final episode returns, it successfully facilitated decision making across two levels of abstraction using compact, low dimensional abstract actions. A central challenge in enhancing our method's performance, as uncovered through comprehensive experimentation, is model exploitation on the abstract level of our world model stack. We provide an in depth examination of this issue, discussing its implications for the field and suggesting directions for future research to overcome this challenge. By sharing these findings, we aim to contribute to the broader discourse on refining HMBRL methodologies and to assist in the development of more effective autonomous learning systems for complex decision-making environments.
6/4/2024

Learning Latent Dynamic Robust Representations for World Models
Ruixiang Sun, Hongyu Zang, Xin Li, Riashat Islam
0
0
Visual Model-Based Reinforcement Learning (MBRL) promises to encapsulate agent's knowledge about the underlying dynamics of the environment, enabling learning a world model as a useful planner. However, top MBRL agents such as Dreamer often struggle with visual pixel-based inputs in the presence of exogenous or irrelevant noise in the observation space, due to failure to capture task-specific features while filtering out irrelevant spatio-temporal details. To tackle this problem, we apply a spatio-temporal masking strategy, a bisimulation principle, combined with latent reconstruction, to capture endogenous task-specific aspects of the environment for world models, effectively eliminating non-essential information. Joint training of representations, dynamics, and policy often leads to instabilities. To further address this issue, we develop a Hybrid Recurrent State-Space Model (HRSSM) structure, enhancing state representation robustness for effective policy learning. Our empirical evaluation demonstrates significant performance improvements over existing methods in a range of visually complex control tasks such as Maniskill cite{gu2023maniskill2} with exogenous distractors from the Matterport environment. Our code is avaliable at https://github.com/bit1029public/HRSSM.
5/31/2024
🏅
A Unified View on Solving Objective Mismatch in Model-Based Reinforcement Learning
Ran Wei, Nathan Lambert, Anthony McDonald, Alfredo Garcia, Roberto Calandra
0
0
Model-based Reinforcement Learning (MBRL) aims to make agents more sample-efficient, adaptive, and explainable by learning an explicit model of the environment. While the capabilities of MBRL agents have significantly improved in recent years, how to best learn the model is still an unresolved question. The majority of MBRL algorithms aim at training the model to make accurate predictions about the environment and subsequently using the model to determine the most rewarding actions. However, recent research has shown that model predictive accuracy is often not correlated with action quality, tracing the root cause to the objective mismatch between accurate dynamics model learning and policy optimization of rewards. A number of interrelated solution categories to the objective mismatch problem have emerged as MBRL continues to mature as a research area. In this work, we provide an in-depth survey of these solution categories and propose a taxonomy to foster future research.
4/9/2024

HarmoDT: Harmony Multi-Task Decision Transformer for Offline Reinforcement Learning
Shengchao Hu, Ziqing Fan, Li Shen, Ya Zhang, Yanfeng Wang, Dacheng Tao
0
0
The purpose of offline multi-task reinforcement learning (MTRL) is to develop a unified policy applicable to diverse tasks without the need for online environmental interaction. Recent advancements approach this through sequence modeling, leveraging the Transformer architecture's scalability and the benefits of parameter sharing to exploit task similarities. However, variations in task content and complexity pose significant challenges in policy formulation, necessitating judicious parameter sharing and management of conflicting gradients for optimal policy performance. In this work, we introduce the Harmony Multi-Task Decision Transformer (HarmoDT), a novel solution designed to identify an optimal harmony subspace of parameters for each task. We approach this as a bi-level optimization problem, employing a meta-learning framework that leverages gradient-based techniques. The upper level of this framework is dedicated to learning a task-specific mask that delineates the harmony subspace, while the inner level focuses on updating parameters to enhance the overall performance of the unified policy. Empirical evaluations on a series of benchmarks demonstrate the superiority of HarmoDT, verifying the effectiveness of our approach.
5/29/2024