A Unified View on Solving Objective Mismatch in Model-Based Reinforcement Learning
2310.06253
0
0
🏅
Abstract
Model-based Reinforcement Learning (MBRL) aims to make agents more sample-efficient, adaptive, and explainable by learning an explicit model of the environment. While the capabilities of MBRL agents have significantly improved in recent years, how to best learn the model is still an unresolved question. The majority of MBRL algorithms aim at training the model to make accurate predictions about the environment and subsequently using the model to determine the most rewarding actions. However, recent research has shown that model predictive accuracy is often not correlated with action quality, tracing the root cause to the objective mismatch between accurate dynamics model learning and policy optimization of rewards. A number of interrelated solution categories to the objective mismatch problem have emerged as MBRL continues to mature as a research area. In this work, we provide an in-depth survey of these solution categories and propose a taxonomy to foster future research.
Create account to get full access
Overview
- Model-based Reinforcement Learning (MBRL) aims to train agents to be more sample-efficient, adaptable, and interpretable by learning an explicit model of their environment.
- While MBRL agents have made significant progress in recent years, how to best learn the model is still an open question.
- Many MBRL algorithms focus on training the model to make accurate predictions about the environment, then using that model to find the most rewarding actions.
- However, research has shown that model prediction accuracy often does not correlate with the quality of the actions the agent takes, due to a mismatch between the objectives of accurate model learning and reward-optimizing policy learning.
- Several related solution categories have emerged to address this mismatch as MBRL research has advanced.
Plain English Explanation
MBRL is a way to train AI agents to be more efficient, flexible, and understandable by having them learn an explicit model of their surroundings. The agents use this model to figure out the best actions to take in order to get the most rewards.
While MBRL agents have gotten much better in recent years, researchers are still trying to figure out the best way for the agents to learn these models. Most MBRL algorithms focus on training the model to make very accurate predictions about the environment, then using that model to decide on the most rewarding actions.
But research has shown that an accurate model doesn't always lead to the agent taking the best actions. This is because the objectives of building an accurate model and finding the most rewarding actions don't always align perfectly.
As MBRL has continued to develop, scientists have come up with several different approaches to try to solve this mismatch between model accuracy and action quality. This paper provides an in-depth look at these different solution categories and proposes a way to organize them to help guide future research.
Technical Explanation
The majority of MBRL algorithms aim to train the model to make highly accurate predictions about the environment, and then use that model to determine the most rewarding actions for the agent to take. However, recent research has shown that model predictive accuracy is often not correlated with the quality of the actions the agent selects.
This is due to an
To address this issue, a number of interrelated solution categories have emerged in the MBRL research space:
-
Demonstration-Guided Multi-Objective Reinforcement Learning: Incorporating expert demonstrations to help guide the model learning and policy optimization processes.
-
Bayesian Approach to Robust Inverse Reinforcement Learning: Using Bayesian methods to learn a robust reward function from limited demonstrations.
-
Contrastive UCB: Provably Efficient Contrastive Self-Supervised: Employing contrastive self-supervised learning techniques to improve model learning.
-
Imitation Game: Model-Based Imitation Learning from Deep: Leveraging imitation learning to help bridge the gap between model accuracy and policy performance.
-
Active Exploration in Bayesian Model-Based Reinforcement Learning: Using Bayesian techniques to guide the agent's exploration of the environment in order to learn a better model.
This paper proposes a taxonomy to organize these diverse solution categories and help direct future MBRL research efforts.
Critical Analysis
The paper provides a comprehensive overview of the objective mismatch problem in MBRL and the various solution categories that have emerged to address it. The authors do a good job of clearly explaining the core issue and highlighting the key ideas behind each proposed solution.
One limitation of the paper is that it does not go into deep technical details on the specific methods and algorithms within each solution category. This is understandable given the survey nature of the work, but readers looking for more implementation-level insights may need to refer to the individual papers cited.
Additionally, the paper does not critically examine the strengths, weaknesses, and trade-offs of the different solution approaches. A more in-depth analysis of the pros and cons of each category could help researchers and practitioners better understand when certain methods may be more appropriate than others.
The taxonomy proposed by the authors seems like a reasonable way to organize the MBRL solution space, but it would be valuable to see how this framework holds up as new techniques continue to emerge in this active area of research. Periodic updates and refinements to the taxonomy may be necessary.
Overall, this paper provides a solid foundation for understanding the key challenges in MBRL and the current state-of-the-art in addressing the objective mismatch problem. It should serve as a useful resource for researchers looking to navigate this complex and rapidly evolving field.
Conclusion
This paper offers an in-depth survey of the objective mismatch problem in Model-based Reinforcement Learning (MBRL) and the various solution categories that have been proposed to address it. MBRL aims to train more sample-efficient, adaptable, and explainable agents by having them learn an explicit model of their environment, but the disconnect between accurate model learning and reward-optimizing policy learning has proven to be a significant challenge.
The authors identify five key solution categories that researchers have explored to bridge this gap, including demonstration-guided multi-objective learning, Bayesian inverse reinforcement learning, contrastive self-supervised techniques, model-based imitation learning, and active exploration strategies. By providing a comprehensive overview of these approaches and proposing a unifying taxonomy, the paper offers a valuable roadmap to guide future MBRL research efforts.
As MBRL continues to advance, addressing the objective mismatch will remain a critical area of focus. The insights and framework laid out in this paper should help the research community build more effective MBRL agents that can truly leverage their learned models to make intelligent, reward-maximizing decisions.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
HarmonyDream: Task Harmonization Inside World Models
Haoyu Ma, Jialong Wu, Ningya Feng, Chenjun Xiao, Dong Li, Jianye Hao, Jianmin Wang, Mingsheng Long
0
0
Model-based reinforcement learning (MBRL) holds the promise of sample-efficient learning by utilizing a world model, which models how the environment works and typically encompasses components for two tasks: observation modeling and reward modeling. In this paper, through a dedicated empirical investigation, we gain a deeper understanding of the role each task plays in world models and uncover the overlooked potential of sample-efficient MBRL by mitigating the domination of either observation or reward modeling. Our key insight is that while prevalent approaches of explicit MBRL attempt to restore abundant details of the environment via observation models, it is difficult due to the environment's complexity and limited model capacity. On the other hand, reward models, while dominating implicit MBRL and adept at learning compact task-centric dynamics, are inadequate for sample-efficient learning without richer learning signals. Motivated by these insights and discoveries, we propose a simple yet effective approach, HarmonyDream, which automatically adjusts loss coefficients to maintain task harmonization, i.e. a dynamic equilibrium between the two tasks in world model learning. Our experiments show that the base MBRL method equipped with HarmonyDream gains 10%-69% absolute performance boosts on visual robotic tasks and sets a new state-of-the-art result on the Atari 100K benchmark. Code is available at https://github.com/thuml/HarmonyDream.
6/6/2024
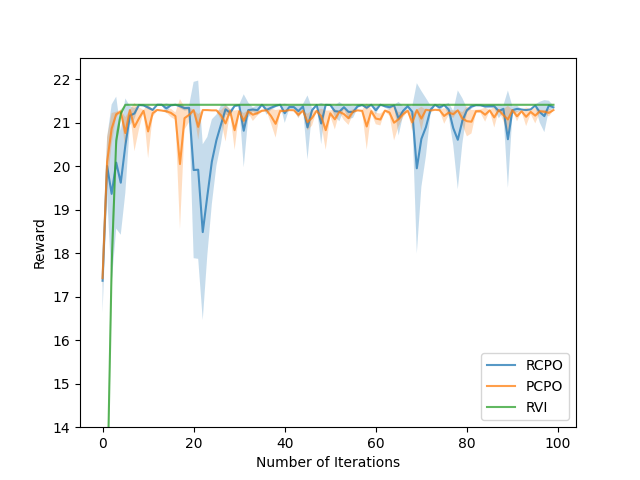
Constrained Reinforcement Learning Under Model Mismatch
Zhongchang Sun, Sihong He, Fei Miao, Shaofeng Zou
0
0
Existing studies on constrained reinforcement learning (RL) may obtain a well-performing policy in the training environment. However, when deployed in a real environment, it may easily violate constraints that were originally satisfied during training because there might be model mismatch between the training and real environments. To address the above challenge, we formulate the problem as constrained RL under model uncertainty, where the goal is to learn a good policy that optimizes the reward and at the same time satisfy the constraint under model mismatch. We develop a Robust Constrained Policy Optimization (RCPO) algorithm, which is the first algorithm that applies to large/continuous state space and has theoretical guarantees on worst-case reward improvement and constraint violation at each iteration during the training. We demonstrate the effectiveness of our algorithm on a set of RL tasks with constraints.
5/6/2024

Safe Deep Model-Based Reinforcement Learning with Lyapunov Functions
Harry Zhang
0
0
Model-based Reinforcement Learning (MBRL) has shown many desirable properties for intelligent control tasks. However, satisfying safety and stability constraints during training and rollout remains an open question. We propose a new Model-based RL framework to enable efficient policy learning with unknown dynamics based on learning model predictive control (LMPC) framework with mathematically provable guarantees of stability. We introduce and explore a novel method for adding safety constraints for model-based RL during training and policy learning. The new stability-augmented framework consists of a neural-network-based learner that learns to construct a Lyapunov function, and a model-based RL agent to consistently complete the tasks while satisfying user-specified constraints given only sub-optimal demonstrations and sparse-cost feedback. We demonstrate the capability of the proposed framework through simulated experiments.
5/28/2024
📈
Acting upon Imagination: when to trust imagined trajectories in model based reinforcement learning
Adrian Remonda, Eduardo Veas, Granit Luzhnica
0
0
Model-based reinforcement learning (MBRL) aims to learn model(s) of the environment dynamics that can predict the outcome of its actions. Forward application of the model yields so called imagined trajectories (sequences of action, predicted state-reward) used to optimize the set of candidate actions that maximize expected reward. The outcome, an ideal imagined trajectory or plan, is imperfect and typically MBRL relies on model predictive control (MPC) to overcome this by continuously re-planning from scratch, incurring thus major computational cost and increasing complexity in tasks with longer receding horizon. We propose uncertainty estimation methods for online evaluation of imagined trajectories to assess whether further planned actions can be trusted to deliver acceptable reward. These methods include comparing the error after performing the last action with the standard expected error and using model uncertainty to assess the deviation from expected outcomes. Additionally, we introduce methods that exploit the forward propagation of the dynamics model to evaluate if the remainder of the plan aligns with expected results and assess the remainder of the plan in terms of the expected reward. Our experiments demonstrate the effectiveness of the proposed uncertainty estimation methods by applying them to avoid unnecessary trajectory replanning in a shooting MBRL setting. Results highlight significant reduction on computational costs without sacrificing performance.
4/22/2024