Learning Latent Dynamic Robust Representations for World Models
2405.06263
0
0

Abstract
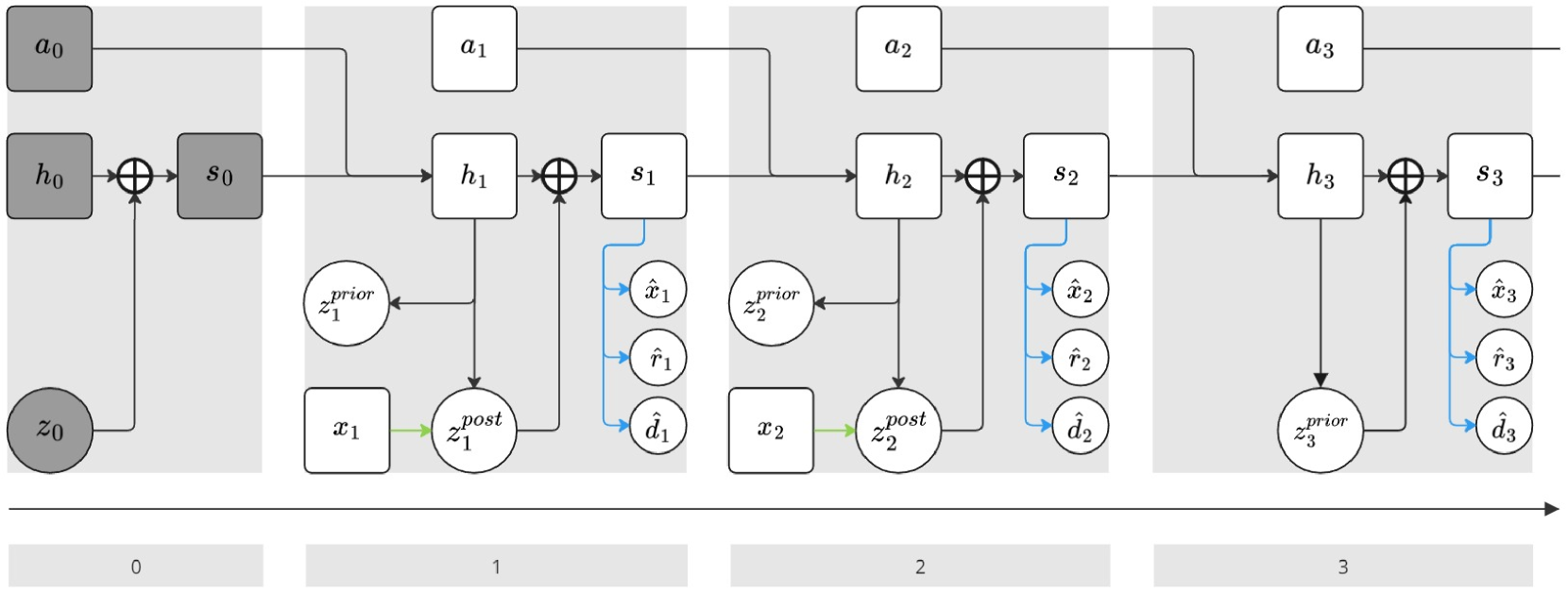
Visual Model-Based Reinforcement Learning (MBRL) promises to encapsulate agent's knowledge about the underlying dynamics of the environment, enabling learning a world model as a useful planner. However, top MBRL agents such as Dreamer often struggle with visual pixel-based inputs in the presence of exogenous or irrelevant noise in the observation space, due to failure to capture task-specific features while filtering out irrelevant spatio-temporal details. To tackle this problem, we apply a spatio-temporal masking strategy, a bisimulation principle, combined with latent reconstruction, to capture endogenous task-specific aspects of the environment for world models, effectively eliminating non-essential information. Joint training of representations, dynamics, and policy often leads to instabilities. To further address this issue, we develop a Hybrid Recurrent State-Space Model (HRSSM) structure, enhancing state representation robustness for effective policy learning. Our empirical evaluation demonstrates significant performance improvements over existing methods in a range of visually complex control tasks such as Maniskill cite{gu2023maniskill2} with exogenous distractors from the Matterport environment. Our code is avaliable at https://github.com/bit1029public/HRSSM.
Create account to get full access
Overview
- The paper proposes a novel approach to learning latent dynamic representations for world models, which are crucial for tasks like reinforcement learning.
- It introduces a regularized contrastive framework that learns robust and disentangled representations, allowing for more reliable and stable world models.
- The approach is evaluated on a range of benchmark tasks, demonstrating improved performance and sample efficiency compared to existing methods.
Plain English Explanation
The paper focuses on a fundamental challenge in reinforcement learning and artificial intelligence: how to build accurate and reliable "world models" - internal representations of the environment that an AI system can use to plan and make decisions.
One key aspect of building effective world models is learning latent, or hidden, representations of the environment that capture the underlying dynamics and structure. The authors propose a new technique called "Latent Dynamic Robust Representations" (LDRR) that learns these latent representations in a robust and disentangled way.
The core idea is to use a "regularized contrastive" framework, which means the representations are trained not just to predict the next state, but also to be different from similar-looking-but-different states. This helps the model learn representations that are more stable and can generalize better to new situations.
The authors evaluated LDRR on a variety of benchmark tasks, and showed it outperformed existing methods in terms of sample efficiency (needing less data to learn) and overall performance. This suggests LDRR could be a powerful tool for building more reliable and capable AI systems that can learn about their environment and plan effectively.
Technical Explanation
The paper introduces a new approach called "Learning Latent Dynamic Robust Representations for World Models" (LDRR). The key innovation is a regularized contrastive learning framework that learns latent representations capturing the underlying dynamics and structure of the environment.
At a high level, the LDRR model consists of an encoder that maps observations to a latent state representation, and a dynamics predictor that forecasts future latent states. The model is trained using a combination of reconstruction, contrastive, and dynamics prediction objectives.
The contrastive objective encourages the latent representations to be different for states that are visually similar but dynamically distinct. This helps the model learn disentangled and robust representations that are stable across different situations.
The authors evaluate LDRR on a range of challenging benchmark tasks, including link to ReCoRe paper, link to LSE paper, and link to Zero-shot Stitching paper. They demonstrate improved sample efficiency and overall performance compared to prior state-of-the-art methods.
Critical Analysis
The paper presents a compelling approach to learning robust latent representations for world models. The authors' use of a regularized contrastive objective is a promising direction, as it helps the model learn representations that are both predictive and disentangled.
One potential limitation is that the paper does not provide a detailed analysis of the learned representations. It would be interesting to see how the representations evolve during training, and to better understand what specific aspects of the environment the model is capturing.
Additionally, while the benchmark tasks are valuable, it would be helpful to see the approach evaluated on more complex, real-world environments. This could reveal additional challenges or limitations that are not apparent in the simpler test scenarios.
Overall, the LDRR framework represents an important step forward in building more reliable and capable world models. The authors' focus on robustness and disentanglement is well-aligned with the broader goals of link to Bridging State-History paper and link to Hierarchical Temporal Abstractions paper in the field of world model learning.
Conclusion
The "Learning Latent Dynamic Robust Representations for World Models" paper presents a novel approach to learning stable and disentangled representations for building effective world models. By incorporating a regularized contrastive objective, the LDRR framework is able to learn more robust and predictive latent representations than previous methods.
The demonstrated improvements in sample efficiency and overall performance on benchmark tasks suggest that LDRR could be a valuable tool for advancing the state-of-the-art in reinforcement learning and other areas of artificial intelligence that rely on accurate world models. As the field continues to grapple with the challenges of building reliable AI systems, techniques like LDRR will play an important role in helping us create agents that can better understand and interact with their environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Exploring the limits of Hierarchical World Models in Reinforcement Learning
Robin Schiewer, Anand Subramoney, Laurenz Wiskott
0
0
Hierarchical model-based reinforcement learning (HMBRL) aims to combine the benefits of better sample efficiency of model based reinforcement learning (MBRL) with the abstraction capability of hierarchical reinforcement learning (HRL) to solve complex tasks efficiently. While HMBRL has great potential, it still lacks wide adoption. In this work we describe a novel HMBRL framework and evaluate it thoroughly. To complement the multi-layered decision making idiom characteristic for HRL, we construct hierarchical world models that simulate environment dynamics at various levels of temporal abstraction. These models are used to train a stack of agents that communicate in a top-down manner by proposing goals to their subordinate agents. A significant focus of this study is the exploration of a static and environment agnostic temporal abstraction, which allows concurrent training of models and agents throughout the hierarchy. Unlike most goal-conditioned H(MB)RL approaches, it also leads to comparatively low dimensional abstract actions. Although our HMBRL approach did not outperform traditional methods in terms of final episode returns, it successfully facilitated decision making across two levels of abstraction using compact, low dimensional abstract actions. A central challenge in enhancing our method's performance, as uncovered through comprehensive experimentation, is model exploitation on the abstract level of our world model stack. We provide an in depth examination of this issue, discussing its implications for the field and suggesting directions for future research to overcome this challenge. By sharing these findings, we aim to contribute to the broader discourse on refining HMBRL methodologies and to assist in the development of more effective autonomous learning systems for complex decision-making environments.
6/4/2024

MuDreamer: Learning Predictive World Models without Reconstruction
Maxime Burchi, Radu Timofte
0
0
The DreamerV3 agent recently demonstrated state-of-the-art performance in diverse domains, learning powerful world models in latent space using a pixel reconstruction loss. However, while the reconstruction loss is essential to Dreamer's performance, it also necessitates modeling unnecessary information. Consequently, Dreamer sometimes fails to perceive crucial elements which are necessary for task-solving when visual distractions are present in the observation, significantly limiting its potential. In this paper, we present MuDreamer, a robust reinforcement learning agent that builds upon the DreamerV3 algorithm by learning a predictive world model without the need for reconstructing input signals. Rather than relying on pixel reconstruction, hidden representations are instead learned by predicting the environment value function and previously selected actions. Similar to predictive self-supervised methods for images, we find that the use of batch normalization is crucial to prevent learning collapse. We also study the effect of KL balancing between model posterior and prior losses on convergence speed and learning stability. We evaluate MuDreamer on the commonly used DeepMind Visual Control Suite and demonstrate stronger robustness to visual distractions compared to DreamerV3 and other reconstruction-free approaches, replacing the environment background with task-irrelevant real-world videos. Our method also achieves comparable performance on the Atari100k benchmark while benefiting from faster training.
5/27/2024
🧠
HarmonyDream: Task Harmonization Inside World Models
Haoyu Ma, Jialong Wu, Ningya Feng, Chenjun Xiao, Dong Li, Jianye Hao, Jianmin Wang, Mingsheng Long
0
0
Model-based reinforcement learning (MBRL) holds the promise of sample-efficient learning by utilizing a world model, which models how the environment works and typically encompasses components for two tasks: observation modeling and reward modeling. In this paper, through a dedicated empirical investigation, we gain a deeper understanding of the role each task plays in world models and uncover the overlooked potential of sample-efficient MBRL by mitigating the domination of either observation or reward modeling. Our key insight is that while prevalent approaches of explicit MBRL attempt to restore abundant details of the environment via observation models, it is difficult due to the environment's complexity and limited model capacity. On the other hand, reward models, while dominating implicit MBRL and adept at learning compact task-centric dynamics, are inadequate for sample-efficient learning without richer learning signals. Motivated by these insights and discoveries, we propose a simple yet effective approach, HarmonyDream, which automatically adjusts loss coefficients to maintain task harmonization, i.e. a dynamic equilibrium between the two tasks in world model learning. Our experiments show that the base MBRL method equipped with HarmonyDream gains 10%-69% absolute performance boosts on visual robotic tasks and sets a new state-of-the-art result on the Atari 100K benchmark. Code is available at https://github.com/thuml/HarmonyDream.
6/6/2024
🏅
Vision-Language Models Provide Promptable Representations for Reinforcement Learning
William Chen, Oier Mees, Aviral Kumar, Sergey Levine
0
0
Humans can quickly learn new behaviors by leveraging background world knowledge. In contrast, agents trained with reinforcement learning (RL) typically learn behaviors from scratch. We thus propose a novel approach that uses the vast amounts of general and indexable world knowledge encoded in vision-language models (VLMs) pre-trained on Internet-scale data for embodied RL. We initialize policies with VLMs by using them as promptable representations: embeddings that encode semantic features of visual observations based on the VLM's internal knowledge and reasoning capabilities, as elicited through prompts that provide task context and auxiliary information. We evaluate our approach on visually-complex, long horizon RL tasks in Minecraft and robot navigation in Habitat. We find that our policies trained on embeddings from off-the-shelf, general-purpose VLMs outperform equivalent policies trained on generic, non-promptable image embeddings. We also find our approach outperforms instruction-following methods and performs comparably to domain-specific embeddings. Finally, we show that our approach can use chain-of-thought prompting to produce representations of common-sense semantic reasoning, improving policy performance in novel scenes by 1.5 times.
5/24/2024