Exploring the limits of Hierarchical World Models in Reinforcement Learning
2406.00483
0
0
Abstract
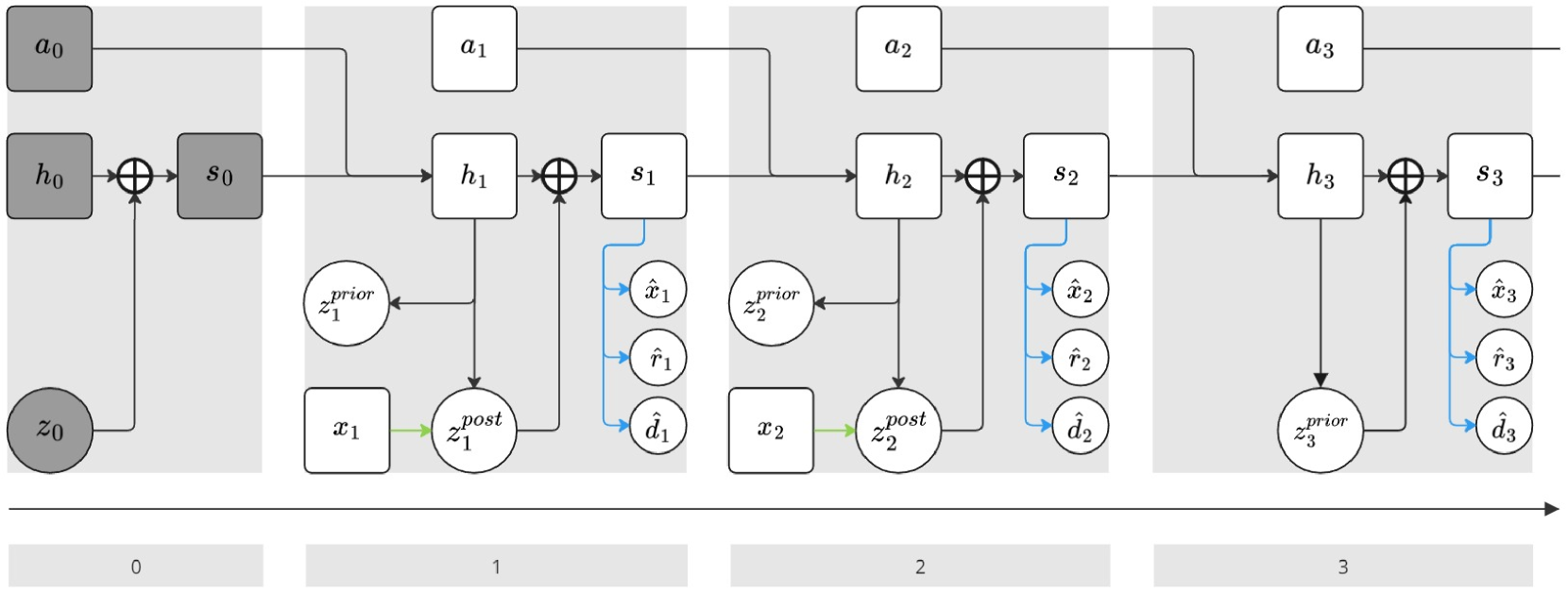
Hierarchical model-based reinforcement learning (HMBRL) aims to combine the benefits of better sample efficiency of model based reinforcement learning (MBRL) with the abstraction capability of hierarchical reinforcement learning (HRL) to solve complex tasks efficiently. While HMBRL has great potential, it still lacks wide adoption. In this work we describe a novel HMBRL framework and evaluate it thoroughly. To complement the multi-layered decision making idiom characteristic for HRL, we construct hierarchical world models that simulate environment dynamics at various levels of temporal abstraction. These models are used to train a stack of agents that communicate in a top-down manner by proposing goals to their subordinate agents. A significant focus of this study is the exploration of a static and environment agnostic temporal abstraction, which allows concurrent training of models and agents throughout the hierarchy. Unlike most goal-conditioned H(MB)RL approaches, it also leads to comparatively low dimensional abstract actions. Although our HMBRL approach did not outperform traditional methods in terms of final episode returns, it successfully facilitated decision making across two levels of abstraction using compact, low dimensional abstract actions. A central challenge in enhancing our method's performance, as uncovered through comprehensive experimentation, is model exploitation on the abstract level of our world model stack. We provide an in depth examination of this issue, discussing its implications for the field and suggesting directions for future research to overcome this challenge. By sharing these findings, we aim to contribute to the broader discourse on refining HMBRL methodologies and to assist in the development of more effective autonomous learning systems for complex decision-making environments.
Create account to get full access
Overview
- This paper explores the limits of hierarchical world models in reinforcement learning (RL), a technique for training AI agents to interact with and learn from their environment.
- The authors investigate how well these hierarchical models can capture the structure and dynamics of complex environments, and how this affects the agents' ability to plan and make decisions.
- The research builds on previous work on learning latent dynamic and robust representations, guided cooperation in hierarchical RL, and learning world models with temporal abstractions.
Plain English Explanation
Reinforcement learning is a type of machine learning where AI agents learn to make decisions by interacting with their environment and receiving rewards or punishments. Hierarchical world models are a way of structuring these models, where the agent builds a multi-level understanding of the environment, from low-level details to high-level patterns and relationships.
This paper examines the limits of these hierarchical models - how well they can capture the full complexity of real-world environments, and how that affects the agent's ability to plan and make good decisions. The authors build on previous research that has looked at different ways of representing the environment in reinforcement learning, including learning latent representations, guided cooperation between different parts of the model, and incorporating temporal abstractions.
The goal is to understand the strengths and limitations of hierarchical world models, and how they compare to other approaches for building intelligent agents that can navigate complex environments.
Technical Explanation
The paper evaluates hierarchical world models, which represent the environment at multiple levels of abstraction, from low-level details to high-level patterns and relationships. This builds on prior work that has explored learning latent representations, guided cooperation between different parts of the model, and incorporating temporal abstractions.
The authors conduct experiments to test the limits of these hierarchical models, examining how well they can capture the full complexity of real-world environments, and how that affects the agent's ability to plan and make decisions. They evaluate the models on challenging benchmark tasks that require reasoning about long-term dependencies and high-level structure.
The results provide insights into the strengths and weaknesses of hierarchical world models compared to other approaches, such as visual whole-body models and unified views of objective mismatch. The findings have implications for the design of more powerful and flexible reinforcement learning agents that can navigate complex, real-world environments.
Critical Analysis
The paper provides a thorough exploration of the limits of hierarchical world models in reinforcement learning, but there are a few potential areas for further research and discussion:
-
The experiments focus on a limited set of benchmark tasks, which may not fully capture the diversity of real-world environments. Additional testing on a wider range of environments could help validate the generalizability of the findings.
-
The paper does not delve into the computational and memory requirements of the hierarchical models, which could be an important practical consideration for deploying these systems in resource-constrained settings.
-
While the authors highlight the strengths and weaknesses of the hierarchical approach, they do not provide a direct comparison to other model architectures, such as the visual whole-body models or the unified view of objective mismatch. Such a comparative analysis could further elucidate the trade-offs between different modeling approaches.
-
The paper does not discuss potential ethical considerations or societal impacts of the research, which could be an important area for future work, given the increasing prevalence of reinforcement learning in real-world applications.
Conclusion
This paper explores the limits of hierarchical world models in reinforcement learning, providing valuable insights into the strengths and weaknesses of this approach. The findings suggest that while hierarchical models can effectively capture some aspects of complex environments, they may struggle to fully represent the full richness and dynamism of real-world scenarios.
The research builds on and complements previous work in areas such as learning latent representations, guided cooperation in hierarchical RL, and incorporating temporal abstractions. By examining the limitations of hierarchical models, the paper helps to inform the development of more powerful and flexible reinforcement learning agents that can navigate complex, real-world environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Learning Latent Dynamic Robust Representations for World Models
Ruixiang Sun, Hongyu Zang, Xin Li, Riashat Islam
0
0
Visual Model-Based Reinforcement Learning (MBRL) promises to encapsulate agent's knowledge about the underlying dynamics of the environment, enabling learning a world model as a useful planner. However, top MBRL agents such as Dreamer often struggle with visual pixel-based inputs in the presence of exogenous or irrelevant noise in the observation space, due to failure to capture task-specific features while filtering out irrelevant spatio-temporal details. To tackle this problem, we apply a spatio-temporal masking strategy, a bisimulation principle, combined with latent reconstruction, to capture endogenous task-specific aspects of the environment for world models, effectively eliminating non-essential information. Joint training of representations, dynamics, and policy often leads to instabilities. To further address this issue, we develop a Hybrid Recurrent State-Space Model (HRSSM) structure, enhancing state representation robustness for effective policy learning. Our empirical evaluation demonstrates significant performance improvements over existing methods in a range of visually complex control tasks such as Maniskill cite{gu2023maniskill2} with exogenous distractors from the Matterport environment. Our code is avaliable at https://github.com/bit1029public/HRSSM.
5/31/2024
🧠
HarmonyDream: Task Harmonization Inside World Models
Haoyu Ma, Jialong Wu, Ningya Feng, Chenjun Xiao, Dong Li, Jianye Hao, Jianmin Wang, Mingsheng Long
0
0
Model-based reinforcement learning (MBRL) holds the promise of sample-efficient learning by utilizing a world model, which models how the environment works and typically encompasses components for two tasks: observation modeling and reward modeling. In this paper, through a dedicated empirical investigation, we gain a deeper understanding of the role each task plays in world models and uncover the overlooked potential of sample-efficient MBRL by mitigating the domination of either observation or reward modeling. Our key insight is that while prevalent approaches of explicit MBRL attempt to restore abundant details of the environment via observation models, it is difficult due to the environment's complexity and limited model capacity. On the other hand, reward models, while dominating implicit MBRL and adept at learning compact task-centric dynamics, are inadequate for sample-efficient learning without richer learning signals. Motivated by these insights and discoveries, we propose a simple yet effective approach, HarmonyDream, which automatically adjusts loss coefficients to maintain task harmonization, i.e. a dynamic equilibrium between the two tasks in world model learning. Our experiments show that the base MBRL method equipped with HarmonyDream gains 10%-69% absolute performance boosts on visual robotic tasks and sets a new state-of-the-art result on the Atari 100K benchmark. Code is available at https://github.com/thuml/HarmonyDream.
6/6/2024
🔮
Learning World Models With Hierarchical Temporal Abstractions: A Probabilistic Perspective
Vaisakh Shaj
0
0
Machines that can replicate human intelligence with type 2 reasoning capabilities should be able to reason at multiple levels of spatio-temporal abstractions and scales using internal world models. Devising formalisms to develop such internal world models, which accurately reflect the causal hierarchies inherent in the dynamics of the real world, is a critical research challenge in the domains of artificial intelligence and machine learning. This thesis identifies several limitations with the prevalent use of state space models (SSMs) as internal world models and propose two new probabilistic formalisms namely Hidden-Parameter SSMs and Multi-Time Scale SSMs to address these drawbacks. The structure of graphical models in both formalisms facilitates scalable exact probabilistic inference using belief propagation, as well as end-to-end learning via backpropagation through time. This approach permits the development of scalable, adaptive hierarchical world models capable of representing nonstationary dynamics across multiple temporal abstractions and scales. Moreover, these probabilistic formalisms integrate the concept of uncertainty in world states, thus improving the system's capacity to emulate the stochastic nature of the real world and quantify the confidence in its predictions. The thesis also discuss how these formalisms are in line with related neuroscience literature on Bayesian brain hypothesis and predicitive processing. Our experiments on various real and simulated robots demonstrate that our formalisms can match and in many cases exceed the performance of contemporary transformer variants in making long-range future predictions. We conclude the thesis by reflecting on the limitations of our current models and suggesting directions for future research.
4/29/2024

Guided Cooperation in Hierarchical Reinforcement Learning via Model-based Rollout
Haoran Wang, Zeshen Tang, Leya Yang, Yaoru Sun, Fang Wang, Siyu Zhang, Yeming Chen
0
0
Goal-conditioned hierarchical reinforcement learning (HRL) presents a promising approach for enabling effective exploration in complex, long-horizon reinforcement learning (RL) tasks through temporal abstraction. Empirically, heightened inter-level communication and coordination can induce more stable and robust policy improvement in hierarchical systems. Yet, most existing goal-conditioned HRL algorithms have primarily focused on the subgoal discovery, neglecting inter-level cooperation. Here, we propose a goal-conditioned HRL framework named Guided Cooperation via Model-based Rollout (GCMR), aiming to bridge inter-layer information synchronization and cooperation by exploiting forward dynamics. Firstly, the GCMR mitigates the state-transition error within off-policy correction via model-based rollout, thereby enhancing sample efficiency. Secondly, to prevent disruption by the unseen subgoals and states, lower-level Q-function gradients are constrained using a gradient penalty with a model-inferred upper bound, leading to a more stable behavioral policy conducive to effective exploration. Thirdly, we propose a one-step rollout-based planning, using higher-level critics to guide the lower-level policy. Specifically, we estimate the value of future states of the lower-level policy using the higher-level critic function, thereby transmitting global task information downwards to avoid local pitfalls. These three critical components in GCMR are expected to facilitate inter-level cooperation significantly. Experimental results demonstrate that incorporating the proposed GCMR framework with a disentangled variant of HIGL, namely ACLG, yields more stable and robust policy improvement compared to various baselines and significantly outperforms previous state-of-the-art algorithms.
4/9/2024