Harnessing Neural Unit Dynamics for Effective and Scalable Class-Incremental Learning

0

Sign in to get full access
Overview
- This paper introduces a novel approach to class-incremental learning, which involves training a model to learn new classes without forgetting previously learned ones.
- The proposed method, called Dynamic Feature Learning (DFL), harnesses the dynamics of neural unit activations to effectively and scalably adapt to new classes.
- DFL aims to address the challenge of catastrophic forgetting, where a model's performance on previous tasks degrades as it learns new ones.
Plain English Explanation
The paper describes a way to teach an AI model new things without it forgetting what it already knows. This is important because AI models often struggle with this problem, called "catastrophic forgetting." The new method, called Dynamic Feature Learning (DFL), uses the way the model's internal units activate to help it adapt to new classes of information without losing what it has already learned. This makes the learning process more effective and scalable, allowing the model to continue expanding its knowledge over time.
Technical Explanation
The Dynamic Feature Learning (DFL) approach proposed in this paper focuses on leveraging the dynamics of neural unit activations to enable effective and scalable class-incremental learning. The key idea is to capture and harness the changes in neural unit activities as new classes are learned, allowing the model to adapt and expand its knowledge without catastrophically forgetting previously acquired information.
The authors introduce several novel techniques within the DFL framework. This includes a probability dampening mechanism to balance the model's predictions across new and old classes, and a cascaded gating module to selectively activate relevant features for different class groups. The model also employs a multihead rehearsal-free architecture to efficiently manage the growing number of classes.
Additionally, the paper explores techniques for feature expansion and enhanced compression to further improve the model's performance and scalability in class-incremental learning scenarios.
Critical Analysis
The paper presents a compelling approach to addressing the challenges of class-incremental learning, a crucial problem in the field of machine learning. The proposed DFL method appears to offer effective solutions for mitigating catastrophic forgetting and enabling scalable knowledge expansion.
However, the paper acknowledges certain limitations and areas for further research. For instance, the authors note that the performance of DFL may be affected by the specific network architectures and datasets used, suggesting the need for more extensive evaluation across a broader range of scenarios.
Additionally, while the paper demonstrates the effectiveness of DFL on various benchmarks, it would be valuable to explore its performance and practical implications in real-world applications, where the distribution and frequency of new classes may differ from the controlled experimental settings.
Furthermore, the paper could benefit from a deeper analysis of the underlying mechanisms and assumptions behind the DFL approach. A more rigorous investigation into the theoretical foundations and potential trade-offs of the proposed techniques could provide valuable insights for future research and development in this area.
Conclusion
The Harnessing Neural Unit Dynamics for Effective and Scalable Class-Incremental Learning paper presents a promising approach to addressing the critical challenge of class-incremental learning. By leveraging the dynamics of neural unit activations, the Dynamic Feature Learning (DFL) method offers an effective and scalable solution for expanding the knowledge of AI models without catastrophic forgetting.
The paper's innovative techniques, such as probability dampening, cascaded gating, and feature expansion, demonstrate the potential for significant advancements in the field of continual learning. While the research has some limitations, it opens up avenues for further exploration and could have far-reaching implications for developing more robust and adaptable AI systems capable of continuous growth and learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Harnessing Neural Unit Dynamics for Effective and Scalable Class-Incremental Learning
Depeng Li, Tianqi Wang, Junwei Chen, Wei Dai, Zhigang Zeng
Class-incremental learning (CIL) aims to train a model to learn new classes from non-stationary data streams without forgetting old ones. In this paper, we propose a new kind of connectionist model by tailoring neural unit dynamics that adapt the behavior of neural networks for CIL. In each training session, it introduces a supervisory mechanism to guide network expansion whose growth size is compactly commensurate with the intrinsic complexity of a newly arriving task. This constructs a near-minimal network while allowing the model to expand its capacity when cannot sufficiently hold new classes. At inference time, it automatically reactivates the required neural units to retrieve knowledge and leaves the remaining inactivated to prevent interference. We name our model AutoActivator, which is effective and scalable. To gain insights into the neural unit dynamics, we theoretically analyze the model's convergence property via a universal approximation theorem on learning sequential mappings, which is under-explored in the CIL community. Experiments show that our method achieves strong CIL performance in rehearsal-free and minimal-expansion settings with different backbones.
Read more6/5/2024
↗️
0
Class-Incremental Learning: A Survey
Da-Wei Zhou, Qi-Wei Wang, Zhi-Hong Qi, Han-Jia Ye, De-Chuan Zhan, Ziwei Liu
Deep models, e.g., CNNs and Vision Transformers, have achieved impressive achievements in many vision tasks in the closed world. However, novel classes emerge from time to time in our ever-changing world, requiring a learning system to acquire new knowledge continually. Class-Incremental Learning (CIL) enables the learner to incorporate the knowledge of new classes incrementally and build a universal classifier among all seen classes. Correspondingly, when directly training the model with new class instances, a fatal problem occurs -- the model tends to catastrophically forget the characteristics of former ones, and its performance drastically degrades. There have been numerous efforts to tackle catastrophic forgetting in the machine learning community. In this paper, we survey comprehensively recent advances in class-incremental learning and summarize these methods from several aspects. We also provide a rigorous and unified evaluation of 17 methods in benchmark image classification tasks to find out the characteristics of different algorithms empirically. Furthermore, we notice that the current comparison protocol ignores the influence of memory budget in model storage, which may result in unfair comparison and biased results. Hence, we advocate fair comparison by aligning the memory budget in evaluation, as well as several memory-agnostic performance measures. The source code is available at https://github.com/zhoudw-zdw/CIL_Survey/
Read more7/16/2024

0
Exploiting Fine-Grained Prototype Distribution for Boosting Unsupervised Class Incremental Learning
Jiaming Liu, Hongyuan Liu, Zhili Qin, Wei Han, Yulu Fan, Qinli Yang, Junming Shao
The dynamic nature of open-world scenarios has attracted more attention to class incremental learning (CIL). However, existing CIL methods typically presume the availability of complete ground-truth labels throughout the training process, an assumption rarely met in practical applications. Consequently, this paper explores a more challenging problem of unsupervised class incremental learning (UCIL). The essence of addressing this problem lies in effectively capturing comprehensive feature representations and discovering unknown novel classes. To achieve this, we first model the knowledge of class distribution by exploiting fine-grained prototypes. Subsequently, a granularity alignment technique is introduced to enhance the unsupervised class discovery. Additionally, we proposed a strategy to minimize overlap between novel and existing classes, thereby preserving historical knowledge and mitigating the phenomenon of catastrophic forgetting. Extensive experiments on the five datasets demonstrate that our approach significantly outperforms current state-of-the-art methods, indicating the effectiveness of the proposed method.
Read more8/20/2024
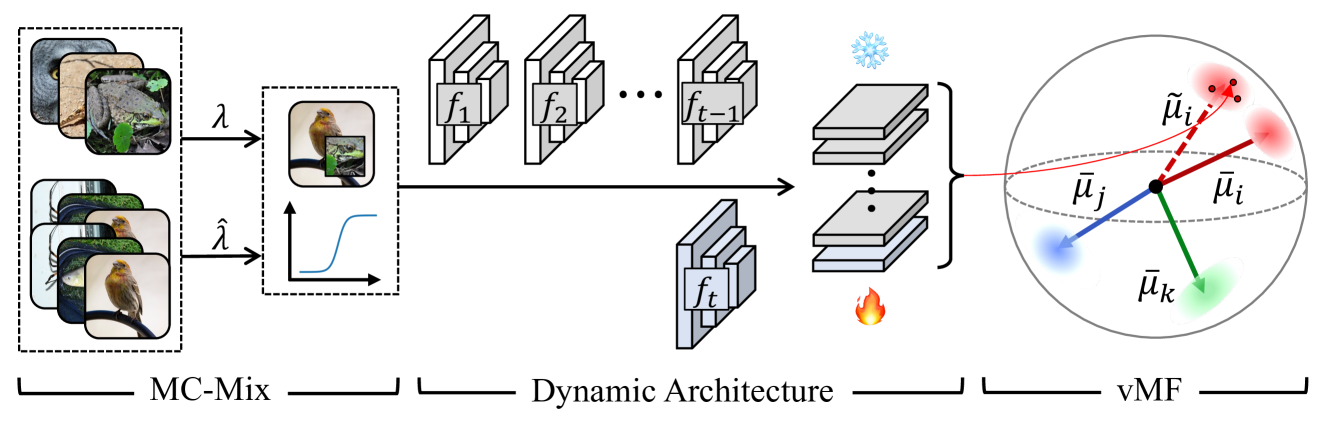
0
Dynamic Feature Learning and Matching for Class-Incremental Learning
Sunyuan Qiang, Yanyan Liang, Jun Wan, Du Zhang
Class-incremental learning (CIL) has emerged as a means to learn new classes incrementally without catastrophic forgetting of previous classes. Recently, CIL has undergone a paradigm shift towards dynamic architectures due to their superior performance. However, these models are still limited by the following aspects: (i) Data augmentation (DA), which are tightly coupled with CIL, remains under-explored in dynamic architecture scenarios. (ii) Feature representation. The discriminativeness of dynamic feature are sub-optimal and possess potential for refinement. (iii) Classifier. The misalignment between dynamic feature and classifier constrains the capabilities of the model. To tackle the aforementioned drawbacks, we propose the Dynamic Feature Learning and Matching (DFLM) model in this paper from above three perspectives. Specifically, we firstly introduce class weight information and non-stationary functions to extend the mix DA method for dynamically adjusting the focus on memory during training. Then, von Mises-Fisher (vMF) classifier is employed to effectively model the dynamic feature distribution and implicitly learn their discriminative properties. Finally, the matching loss is proposed to facilitate the alignment between the learned dynamic features and the classifier by minimizing the distribution distance. Extensive experiments on CIL benchmarks validate that our proposed model achieves significant performance improvements over existing methods.
Read more5/15/2024