Rethinking Class-Incremental Learning from a Dynamic Imbalanced Learning Perspective
2405.15157
0
0
Abstract
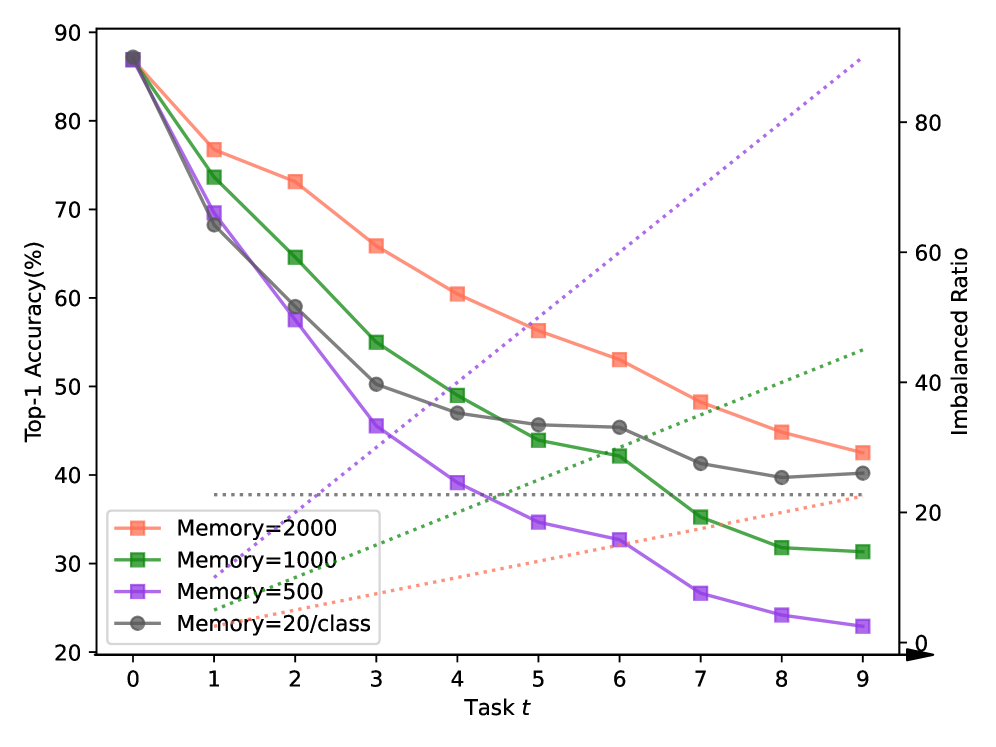
Deep neural networks suffer from catastrophic forgetting when continually learning new concepts. In this paper, we analyze this problem from a data imbalance point of view. We argue that the imbalance between old task and new task data contributes to forgetting of the old tasks. Moreover, the increasing imbalance ratio during incremental learning further aggravates the problem. To address the dynamic imbalance issue, we propose Uniform Prototype Contrastive Learning (UPCL), where uniform and compact features are learned. Specifically, we generate a set of non-learnable uniform prototypes before each task starts. Then we assign these uniform prototypes to each class and guide the feature learning through prototype contrastive learning. We also dynamically adjust the relative margin between old and new classes so that the feature distribution will be maintained balanced and compact. Finally, we demonstrate through extensive experiments that the proposed method achieves state-of-the-art performance on several benchmark datasets including CIFAR100, ImageNet100 and TinyImageNet.
Create account to get full access
Overview
- The paper "Rethinking Class-Incremental Learning from a Dynamic Imbalanced Learning Perspective" explores a new approach to class-incremental learning, which is the ability for AI models to continuously learn new classes of data without forgetting previously learned ones.
- The authors argue that existing class-incremental learning methods do not adequately address the challenge of dynamic class imbalance, where the distribution of classes changes over time.
- The paper proposes a framework that explicitly considers the dynamic imbalance problem and introduces strategies to mitigate its effects on model performance.
Plain English Explanation
The paper discusses a problem faced by machine learning models called "class-incremental learning." This means the ability of a model to continuously learn new classes of data, like different types of images, without forgetting what it has learned before.
The authors explain that existing methods for class-incremental learning don't properly address the issue of "dynamic class imbalance." This is when the distribution of the different classes of data changes over time, making it harder for the model to learn.
To solve this, the researchers propose a new framework that specifically takes the dynamic imbalance problem into account. Their approach introduces strategies to help the model adapt better as the class distribution shifts, leading to improved performance.
Technical Explanation
The paper presents a new perspective on class-incremental learning by framing it as a "dynamic imbalanced learning" problem. This links to the paper on "Simple Sampling Hard Mixup Prototypes to Rebalance" which also discusses imbalanced learning challenges.
The authors argue that existing class-incremental learning methods, such as feature expansion enhanced compression and brain-inspired continual learning, do not adequately handle the dynamic changes in class distribution over time.
To address this, the paper introduces a framework that explicitly models the dynamic imbalance problem. Key elements include:
- Adaptive sampling strategies to rebalance the training data as the class distribution shifts
- Prototype-based learning to capture the discriminative features of each class
- Contrastive loss functions to enhance feature learning related to the "Bayesian Learning Driven Prototypical Contrastive Loss" paper
The authors evaluate their approach on standard class-incremental learning benchmarks and demonstrate improved performance compared to existing methods.
Critical Analysis
The paper provides a fresh perspective on class-incremental learning by considering the dynamic imbalance problem, which is an important but often overlooked challenge in this area. The proposed framework and strategies seem promising based on the reported results.
However, the paper does not explore the limitations or potential downsides of the approach in depth. For example, it's unclear how the method would scale to scenarios with a large number of classes or extremely imbalanced distributions. Additionally, the computational overhead of the adaptive sampling and prototype-based learning components is not discussed.
Further research could investigate the robustness of the approach to more severe distribution shifts, as well as its applicability to a wider range of class-incremental learning settings. This links to the "Brain-Inspired Continual Learning" paper which explores robustness in continual learning.
Overall, the paper presents a valuable contribution to the field of class-incremental learning by highlighting the dynamic imbalance problem and proposing a novel framework to address it.
Conclusion
The paper "Rethinking Class-Incremental Learning from a Dynamic Imbalanced Learning Perspective" introduces a new approach to class-incremental learning that explicitly considers the challenge of dynamic class imbalance. The proposed framework and strategies demonstrate improved performance on standard benchmarks compared to existing methods.
This work highlights the importance of addressing the evolving distribution of classes in continual learning scenarios, which is an often overlooked but critical issue. The insights from this paper could lead to the development of more robust and adaptive class-incremental learning systems, with important implications for applications that require continuous learning, such as autonomous systems and personalized assistants.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
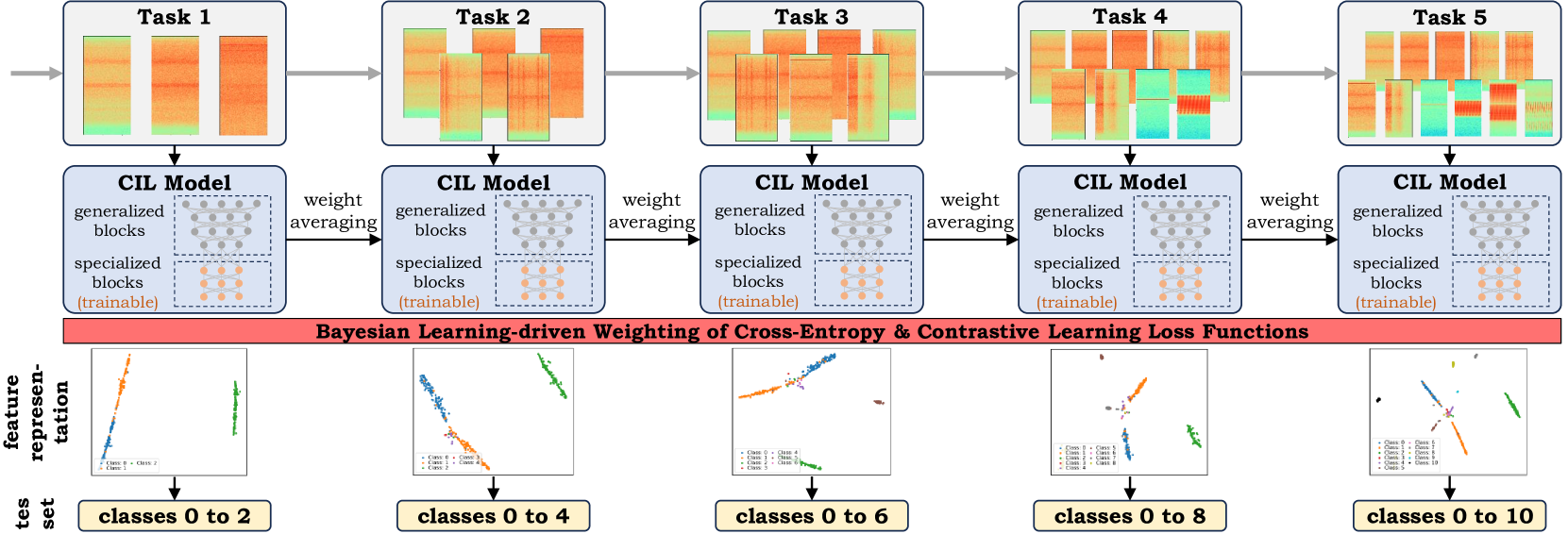
Bayesian Learning-driven Prototypical Contrastive Loss for Class-Incremental Learning
Nisha L. Raichur, Lucas Heublein, Tobias Feigl, Alexander Rugamer, Christopher Mutschler, Felix Ott
0
0
The primary objective of methods in continual learning is to learn tasks in a sequential manner over time from a stream of data, while mitigating the detrimental phenomenon of catastrophic forgetting. In this paper, we focus on learning an optimal representation between previous class prototypes and newly encountered ones. We propose a prototypical network with a Bayesian learning-driven contrastive loss (BLCL) tailored specifically for class-incremental learning scenarios. Therefore, we introduce a contrastive loss that incorporates new classes into the latent representation by reducing the intra-class distance and increasing the inter-class distance. Our approach dynamically adapts the balance between the cross-entropy and contrastive loss functions with a Bayesian learning technique. Empirical evaluations conducted on both the CIFAR-10 dataset for image classification and images of a GNSS-based dataset for interference classification validate the efficacy of our method, showcasing its superiority over existing state-of-the-art approaches.
5/21/2024

Simple-Sampling and Hard-Mixup with Prototypes to Rebalance Contrastive Learning for Text Classification
Mengyu Li, Yonghao Liu, Fausto Giunchiglia, Xiaoyue Feng, Renchu Guan
0
0
Text classification is a crucial and fundamental task in natural language processing. Compared with the previous learning paradigm of pre-training and fine-tuning by cross entropy loss, the recently proposed supervised contrastive learning approach has received tremendous attention due to its powerful feature learning capability and robustness. Although several studies have incorporated this technique for text classification, some limitations remain. First, many text datasets are imbalanced, and the learning mechanism of supervised contrastive learning is sensitive to data imbalance, which may harm the model performance. Moreover, these models leverage separate classification branch with cross entropy and supervised contrastive learning branch without explicit mutual guidance. To this end, we propose a novel model named SharpReCL for imbalanced text classification tasks. First, we obtain the prototype vector of each class in the balanced classification branch to act as a representation of each class. Then, by further explicitly leveraging the prototype vectors, we construct a proper and sufficient target sample set with the same size for each class to perform the supervised contrastive learning procedure. The empirical results show the effectiveness of our model, which even outperforms popular large language models across several datasets.
5/21/2024
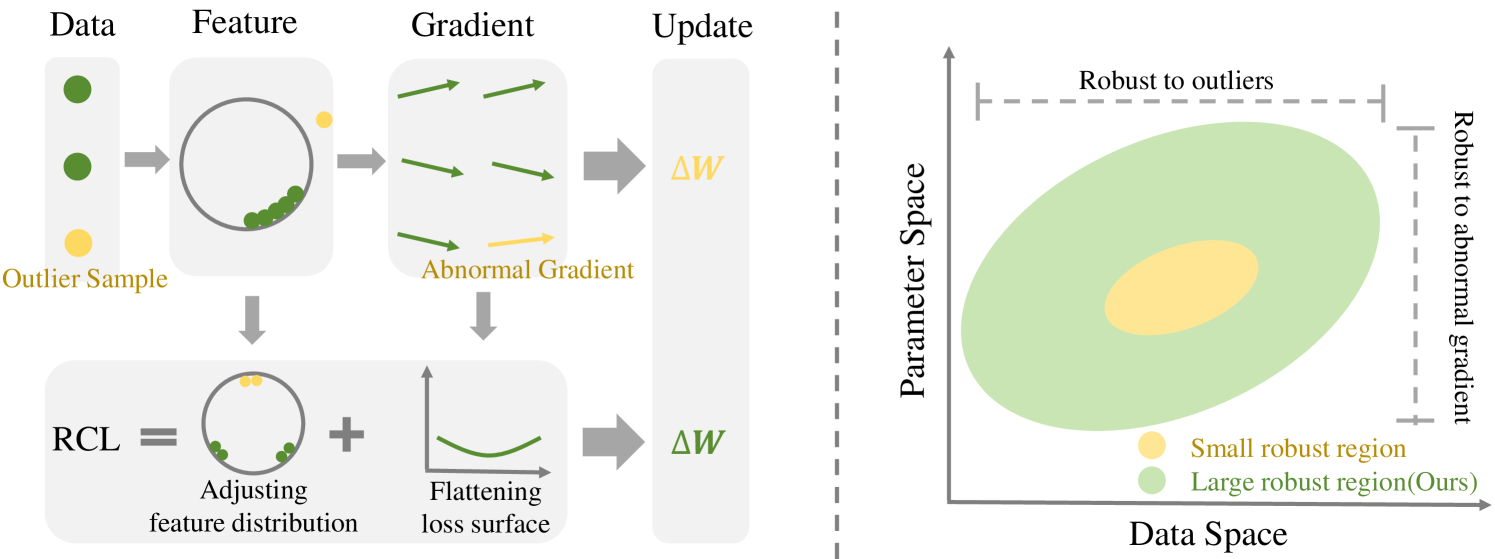
Improving Data-aware and Parameter-aware Robustness for Continual Learning
Hanxi Xiao, Fan Lyu
0
0
The goal of Continual Learning (CL) task is to continuously learn multiple new tasks sequentially while achieving a balance between the plasticity and stability of new and old knowledge. This paper analyzes that this insufficiency arises from the ineffective handling of outliers, leading to abnormal gradients and unexpected model updates. To address this issue, we enhance the data-aware and parameter-aware robustness of CL, proposing a Robust Continual Learning (RCL) method. From the data perspective, we develop a contrastive loss based on the concepts of uniformity and alignment, forming a feature distribution that is more applicable to outliers. From the parameter perspective, we present a forward strategy for worst-case perturbation and apply robust gradient projection to the parameters. The experimental results on three benchmarks show that the proposed method effectively maintains robustness and achieves new state-of-the-art (SOTA) results. The code is available at: https://github.com/HanxiXiao/RCL
5/28/2024
✨
Feature Expansion and enhanced Compression for Class Incremental Learning
Quentin Ferdinand (ENSTA Bretagne, Lab-STICC_MATRIX), Gilles Le Chenadec (ENSTA Bretagne, Lab-STICC_MATRIX), Benoit Clement (CROSSING, ENSTA Bretagne, Lab-STICC_MATRIX), Panagiotis Papadakis (Lab-STICC_RAMBO, IMT Atlantique - INFO), Quentin Oliveau
0
0
Class incremental learning consists in training discriminative models to classify an increasing number of classes over time. However, doing so using only the newly added class data leads to the known problem of catastrophic forgetting of the previous classes. Recently, dynamic deep learning architectures have been shown to exhibit a better stability-plasticity trade-off by dynamically adding new feature extractors to the model in order to learn new classes followed by a compression step to scale the model back to its original size, thus avoiding a growing number of parameters. In this context, we propose a new algorithm that enhances the compression of previous class knowledge by cutting and mixing patches of previous class samples with the new images during compression using our Rehearsal-CutMix method. We show that this new data augmentation reduces catastrophic forgetting by specifically targeting past class information and improving its compression. Extensive experiments performed on the CIFAR and ImageNet datasets under diverse incremental learning evaluation protocols demonstrate that our approach consistently outperforms the state-of-the-art . The code will be made available upon publication of our work.
5/15/2024