HC3 Plus: A Semantic-Invariant Human ChatGPT Comparison Corpus

0
🌿
Sign in to get full access
Overview
- Growing concern about the potential risks of ChatGPT, particularly in the detection of AI-generated content (AIGC)
- Current datasets for detecting ChatGPT-generated text focus on question-answering tasks, overlooking tasks with semantic-invariant properties
- Detecting model-generated text in semantic-invariant tasks is more challenging
Plain English Explanation
ChatGPT has gained significant attention for its impressive performance, but there are increasing concerns about the risks it poses. One key issue is the challenge of detecting content generated by ChatGPT and other AI models, as it can be difficult for untrained individuals to identify.
The datasets currently used to train models for detecting ChatGPT-generated text primarily focus on question-answering tasks. However, this overlooks other types of tasks that have semantic-invariant properties, such as summarization, translation, and paraphrasing.
The paper demonstrates that detecting model-generated text in these semantic-invariant tasks is actually more challenging than for question-answering. To address this gap, the researchers introduce a more extensive and comprehensive dataset that covers a wider range of tasks, including those with semantic-invariant properties.
Technical Explanation
The paper focuses on the challenge of detecting AI-generated content, particularly in tasks with semantic-invariant properties, such as summarization, translation, and paraphrasing.
The authors note that current datasets used for detecting ChatGPT-generated text primarily focus on question-answering tasks, which may not be representative of the full range of challenges in identifying AI-generated content. To address this, the researchers introduce a new, more comprehensive dataset that incorporates a wider variety of tasks, including those with semantic-invariant properties.
Through their experiments, the authors demonstrate that detecting model-generated text in semantic-invariant tasks is more challenging than for question-answering tasks. This suggests that existing detection models may not be well-equipped to handle the nuances of AI-generated content in these types of tasks.
Critical Analysis
The paper raises important concerns about the current limitations in detecting AI-generated content, particularly in tasks with semantic-invariant properties. The researchers' introduction of a more comprehensive dataset is a valuable contribution, as it highlights the need to expand the scope of research in this area.
However, the paper does not delve deeply into the potential reasons why detecting model-generated text is more challenging for semantic-invariant tasks. Further investigation into the underlying mechanisms and characteristics of these tasks could provide additional insights and inform the development of more robust detection methods.
Additionally, the paper does not address potential biases or limitations in the dataset itself, which could impact the generalizability of the findings. Exploring these aspects could help strengthen the overall research and provide a more well-rounded understanding of the challenges in AIGC detection.
Conclusion
This paper highlights the growing need to address the challenges in detecting AI-generated content, particularly in tasks with semantic-invariant properties. By introducing a more comprehensive dataset, the researchers have taken an important step towards advancing research in this critical area.
The findings underscore the limitations of current detection methods and the importance of expanding the scope of research to address a wider range of AI-generated content. As the use of language models like ChatGPT continues to expand, the development of robust and reliable AIGC detection capabilities will become increasingly crucial for maintaining trust and transparency in the digital landscape.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🌿
0
HC3 Plus: A Semantic-Invariant Human ChatGPT Comparison Corpus
Zhenpeng Su, Xing Wu, Wei Zhou, Guangyuan Ma, Songlin Hu
ChatGPT has garnered significant interest due to its impressive performance; however, there is growing concern about its potential risks, particularly in the detection of AI-generated content (AIGC), which is often challenging for untrained individuals to identify. Current datasets used for detecting ChatGPT-generated text primarily focus on question-answering tasks, often overlooking tasks with semantic-invariant properties, such as summarization, translation, and paraphrasing. In this paper, we demonstrate that detecting model-generated text in semantic-invariant tasks is more challenging. To address this gap, we introduce a more extensive and comprehensive dataset that incorporates a wider range of tasks than previous work, including those with semantic-invariant properties.
Read more8/29/2024
0
A Linguistic Comparison between Human and ChatGPT-Generated Conversations
Morgan Sandler, Hyesun Choung, Arun Ross, Prabu David
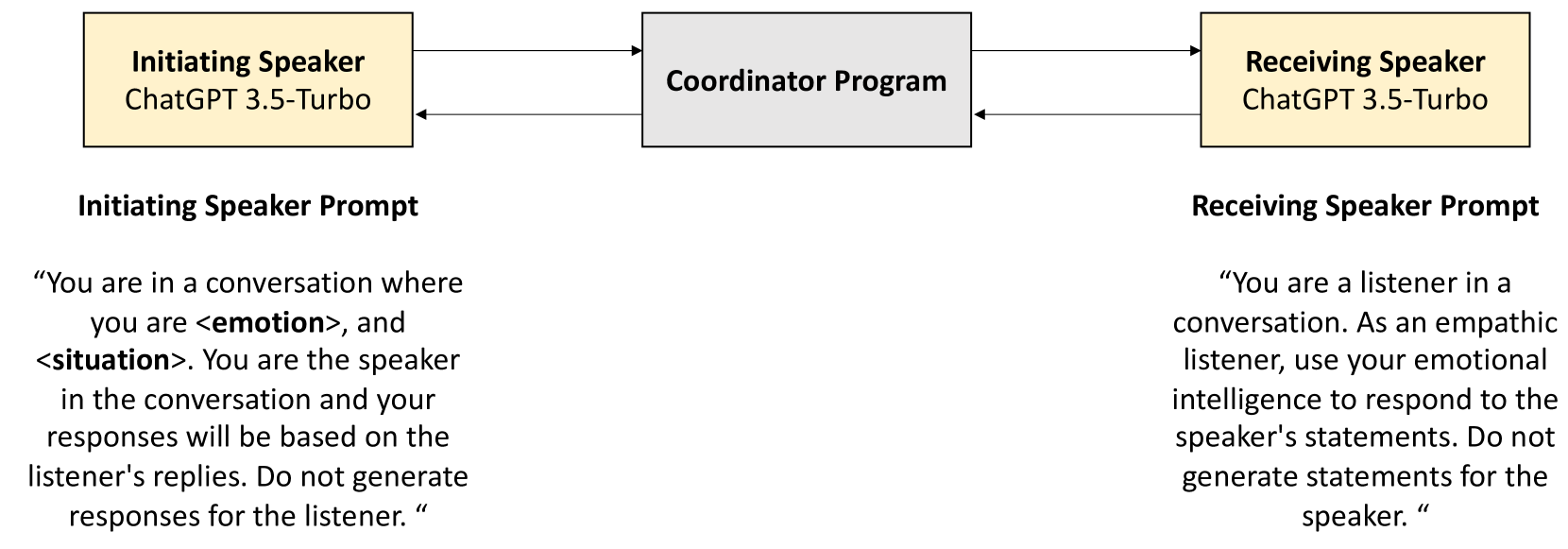
This study explores linguistic differences between human and LLM-generated dialogues, using 19.5K dialogues generated by ChatGPT-3.5 as a companion to the EmpathicDialogues dataset. The research employs Linguistic Inquiry and Word Count (LIWC) analysis, comparing ChatGPT-generated conversations with human conversations across 118 linguistic categories. Results show greater variability and authenticity in human dialogues, but ChatGPT excels in categories such as social processes, analytical style, cognition, attentional focus, and positive emotional tone, reinforcing recent findings of LLMs being more human than human. However, no significant difference was found in positive or negative affect between ChatGPT and human dialogues. Classifier analysis of dialogue embeddings indicates implicit coding of the valence of affect despite no explicit mention of affect in the conversations. The research also contributes a novel, companion ChatGPT-generated dataset of conversations between two independent chatbots, which were designed to replicate a corpus of human conversations available for open access and used widely in AI research on language modeling. Our findings enhance understanding of ChatGPT's linguistic capabilities and inform ongoing efforts to distinguish between human and LLM-generated text, which is critical in detecting AI-generated fakes, misinformation, and disinformation.
Read more4/29/2024

0
(Chat)GPT v BERT: Dawn of Justice for Semantic Change Detection
Francesco Periti, Haim Dubossarsky, Nina Tahmasebi
In the universe of Natural Language Processing, Transformer-based language models like BERT and (Chat)GPT have emerged as lexical superheroes with great power to solve open research problems. In this paper, we specifically focus on the temporal problem of semantic change, and evaluate their ability to solve two diachronic extensions of the Word-in-Context (WiC) task: TempoWiC and HistoWiC. In particular, we investigate the potential of a novel, off-the-shelf technology like ChatGPT (and GPT) 3.5 compared to BERT, which represents a family of models that currently stand as the state-of-the-art for modeling semantic change. Our experiments represent the first attempt to assess the use of (Chat)GPT for studying semantic change. Our results indicate that ChatGPT performs significantly worse than the foundational GPT version. Furthermore, our results demonstrate that (Chat)GPT achieves slightly lower performance than BERT in detecting long-term changes but performs significantly worse in detecting short-term changes.
Read more4/30/2024
❗
0
Distinguishing Chatbot from Human
Gauri Anil Godghase, Rishit Agrawal, Tanush Obili, Mark Stamp
There have been many recent advances in the fields of generative Artificial Intelligence (AI) and Large Language Models (LLM), with the Generative Pre-trained Transformer (GPT) model being a leading chatbot. LLM-based chatbots have become so powerful that it may seem difficult to differentiate between human-written and machine-generated text. To analyze this problem, we have developed a new dataset consisting of more than 750,000 human-written paragraphs, with a corresponding chatbot-generated paragraph for each. Based on this dataset, we apply Machine Learning (ML) techniques to determine the origin of text (human or chatbot). Specifically, we consider two methodologies for tackling this issue: feature analysis and embeddings. Our feature analysis approach involves extracting a collection of features from the text for classification. We also explore the use of contextual embeddings and transformer-based architectures to train classification models. Our proposed solutions offer high classification accuracy and serve as useful tools for textual analysis, resulting in a better understanding of chatbot-generated text in this era of advanced AI technology.
Read more8/12/2024