Head-to-Tail: How Knowledgeable are Large Language Models (LLMs)? A.K.A. Will LLMs Replace Knowledge Graphs?
2308.10168
0
0
💬
Abstract
Since the recent prosperity of Large Language Models (LLMs), there have been interleaved discussions regarding how to reduce hallucinations from LLM responses, how to increase the factuality of LLMs, and whether Knowledge Graphs (KGs), which store the world knowledge in a symbolic form, will be replaced with LLMs. In this paper, we try to answer these questions from a new angle: How knowledgeable are LLMs? To answer this question, we constructed Head-to-Tail, a benchmark that consists of 18K question-answer (QA) pairs regarding head, torso, and tail facts in terms of popularity. We designed an automated evaluation method and a set of metrics that closely approximate the knowledge an LLM confidently internalizes. Through a comprehensive evaluation of 16 publicly available LLMs, we show that existing LLMs are still far from being perfect in terms of their grasp of factual knowledge, especially for facts of torso-to-tail entities.
Create account to get full access
Overview
- Researchers examined the factual knowledge of Large Language Models (LLMs)
- Constructed a benchmark called "Head-to-Tail" to test LLMs on a range of factual knowledge
- Evaluated 16 publicly available LLMs to understand their grasp of factual information
Plain English Explanation
The recent surge in the capabilities of Large Language Models (LLMs) has led to a lot of discussion about how to make them more reliable and truthful. Researchers wanted to understand just how knowledgeable these LLMs really are when it comes to facts about the world.
To do this, they created a new benchmark called "Head-to-Tail" that tested the LLMs on 18,000 different questions. These questions covered a range of facts, from the most popular and well-known ("head" facts) to the more obscure and lesser-known ("tail" facts).
The researchers developed a way to automatically evaluate the LLMs and measure how confidently they knew the answers to these factual questions. They then tested 16 different publicly available LLMs to see how they performed.
The key finding was that even the most advanced LLMs today still struggle, especially when it comes to the more obscure "torso-to-tail" facts. While they may be able to handle the most common and well-known information, their grasp of more specialized or niche factual knowledge is still quite limited.
This suggests that relying on LLMs alone for accurate, factual information may not be advisable, especially for critical applications. The research highlights the continued need for other knowledge sources, like knowledge graphs, to supplement the capabilities of LLMs.
Technical Explanation
The researchers constructed the "Head-to-Tail" benchmark, which consists of 18,000 question-answer pairs covering a range of fact popularity, from the most common "head" facts to the more obscure "tail" facts. They designed an automated evaluation method and a set of metrics to assess how confidently the LLMs internalized this factual knowledge.
Through comprehensive evaluation of 16 publicly available LLMs, the researchers found that existing LLMs are still far from perfect in their grasp of factual knowledge, particularly for the less popular "torso-to-tail" facts. This suggests that LLMs alone may not be sufficient for applications that require accurate, factual information, and that other knowledge sources, such as knowledge graphs, may still be necessary to supplement their capabilities.
Critical Analysis
The paper provides a thorough and well-designed evaluation of LLM knowledge, but it's worth noting a few potential limitations and areas for further research:
- The benchmark focuses on factual knowledge, but LLMs may excel in other areas like commonsense reasoning or language understanding that were not assessed here.
- The evaluation metrics, while carefully designed, may not fully capture the nuances of how LLMs internalize and reason about knowledge.
- The researchers only tested publicly available LLMs, and it's possible that proprietary models developed by tech giants may perform better on these tasks.
Additionally, while the findings suggest the continued importance of knowledge graphs, it would be valuable to explore how LLMs and knowledge graphs could be integrated or used in a complementary fashion to leverage the strengths of both approaches.
Conclusion
This research provides valuable insights into the current limitations of LLMs when it comes to factual knowledge, particularly for less popular or obscure information. The findings highlight the need for continued development and the potential role of other knowledge sources, like knowledge graphs, in creating reliable and truthful AI systems. As LLMs continue to evolve, it will be important to closely monitor their knowledge capabilities and find ways to address their shortcomings to ensure they can be deployed safely and effectively in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Prompting Large Language Models with Knowledge Graphs for Question Answering Involving Long-tail Facts
Wenyu Huang, Guancheng Zhou, Mirella Lapata, Pavlos Vougiouklis, Sebastien Montella, Jeff Z. Pan
0
0
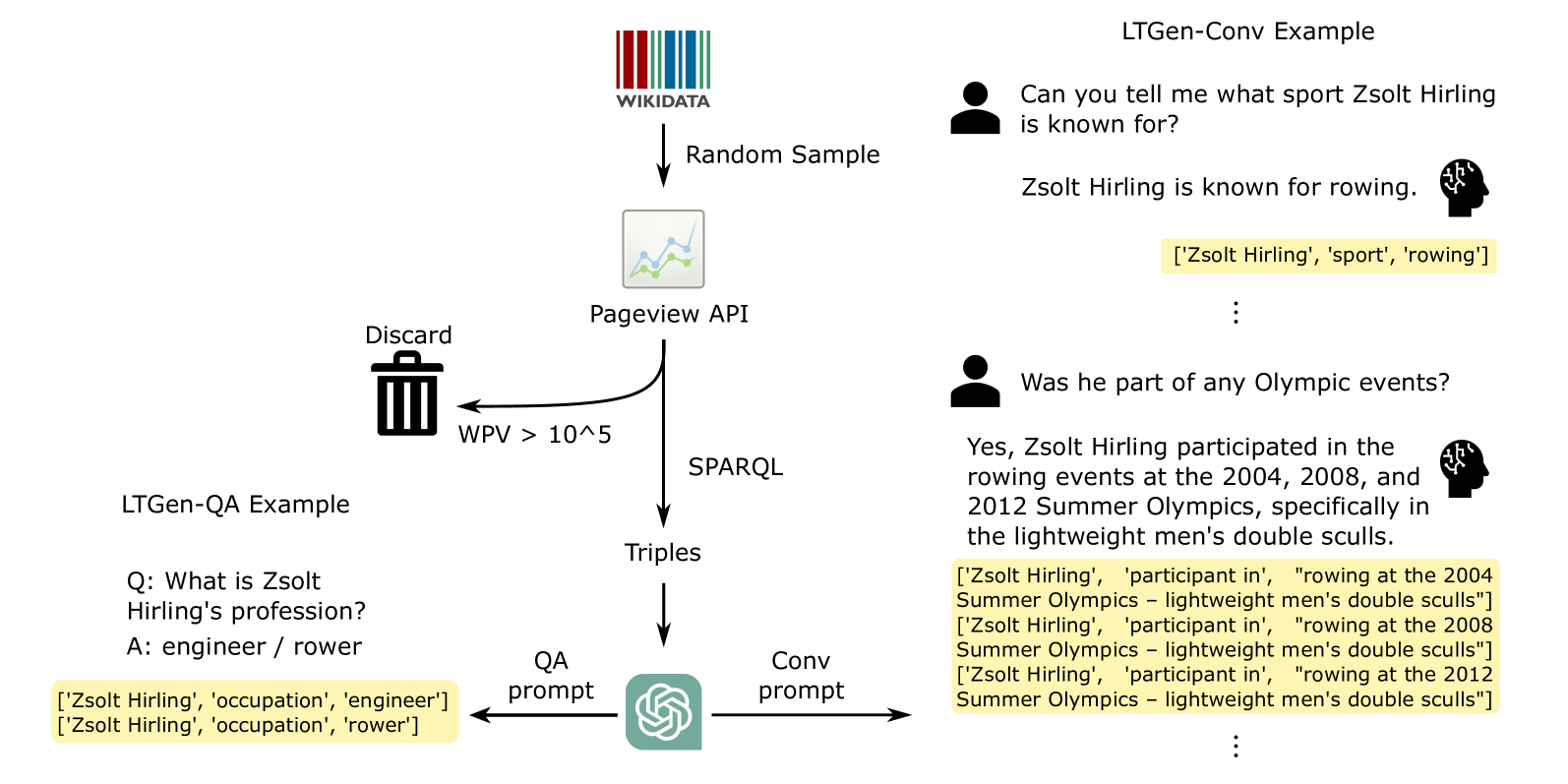
Although Large Language Models (LLMs) are effective in performing various NLP tasks, they still struggle to handle tasks that require extensive, real-world knowledge, especially when dealing with long-tail facts (facts related to long-tail entities). This limitation highlights the need to supplement LLMs with non-parametric knowledge. To address this issue, we analysed the effects of different types of non-parametric knowledge, including textual passage and knowledge graphs (KGs). Since LLMs have probably seen the majority of factual question-answering datasets already, to facilitate our analysis, we proposed a fully automatic pipeline for creating a benchmark that requires knowledge of long-tail facts for answering the involved questions. Using this pipeline, we introduce the LTGen benchmark. We evaluate state-of-the-art LLMs in different knowledge settings using the proposed benchmark. Our experiments show that LLMs alone struggle with answering these questions, especially when the long-tail level is high or rich knowledge is required. Nonetheless, the performance of the same models improved significantly when they were prompted with non-parametric knowledge. We observed that, in most cases, prompting LLMs with KG triples surpasses passage-based prompting using a state-of-the-art retriever. In addition, while prompting LLMs with both KG triples and documents does not consistently improve knowledge coverage, it can dramatically reduce hallucinations in the generated content.
5/13/2024
Counter-intuitive: Large Language Models Can Better Understand Knowledge Graphs Than We Thought
Xinbang Dai, Yuncheng Hua, Tongtong Wu, Yang Sheng, Qiu Ji, Guilin Qi
0
0
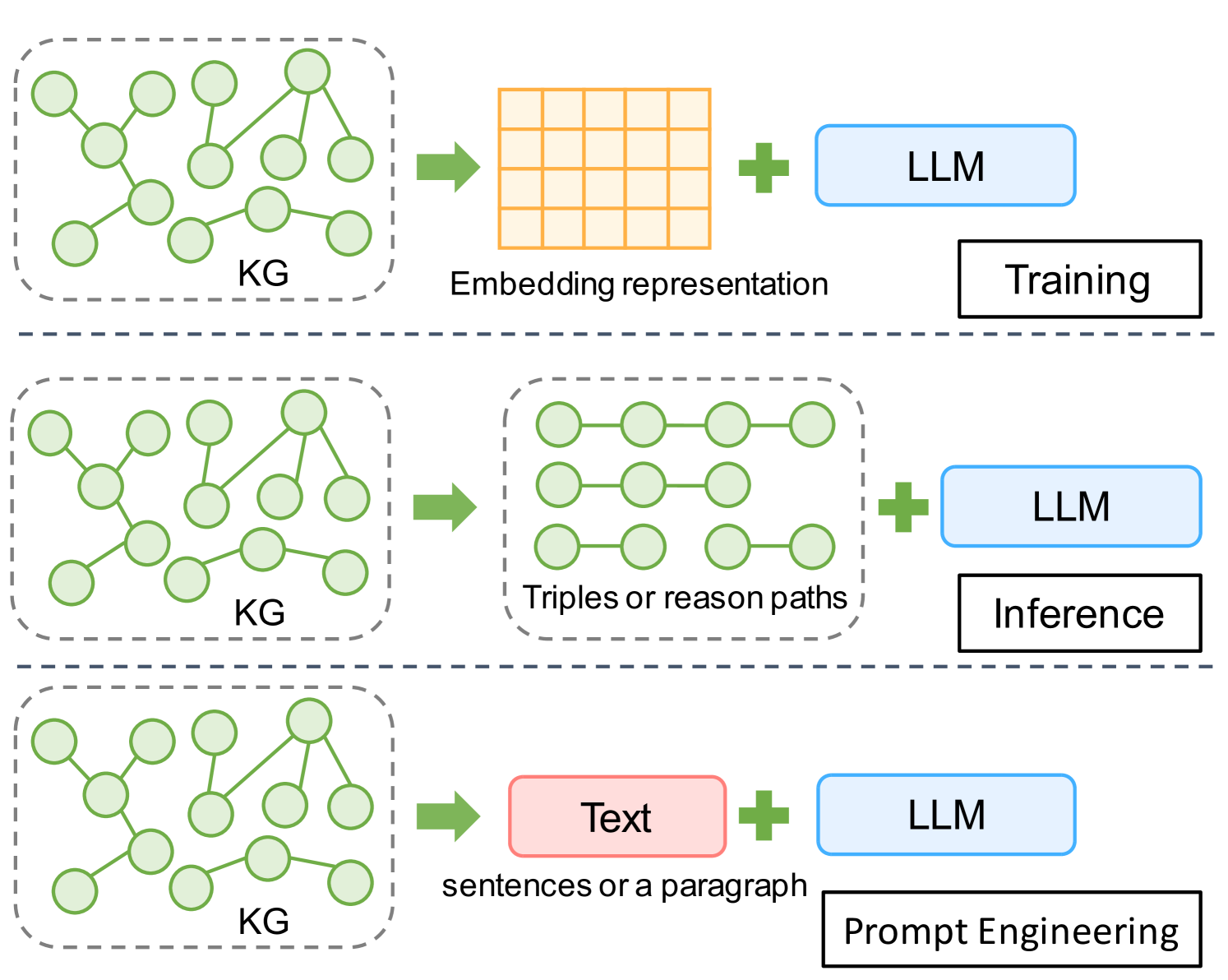
As the parameter scale of large language models (LLMs) grows, jointly training knowledge graph (KG) embeddings with model parameters to enhance LLM capabilities becomes increasingly costly. Consequently, the community has shown interest in developing prompt strategies that effectively integrate KG information into LLMs. However, the format for incorporating KGs into LLMs lacks standardization; for instance, KGs can be transformed into linearized triples or natural language (NL) text. Current prompting methods often rely on a trial-and-error approach, leaving researchers with an incomplete understanding of which KG input format best facilitates LLM comprehension of KG content. To elucidate this, we design a series of experiments to explore LLMs' understanding of different KG input formats within the context of prompt engineering. Our analysis examines both literal and attention distribution levels. Through extensive experiments, we indicate a counter-intuitive phenomenon: when addressing fact-related questions, unordered linearized triples are more effective for LLMs' understanding of KGs compared to fluent NL text. Furthermore, noisy, incomplete, or marginally relevant subgraphs can still enhance LLM performance. Finally, different LLMs have distinct preferences for different formats of organizing unordered triples.
6/18/2024
🧠
HOLMES: Hyper-Relational Knowledge Graphs for Multi-hop Question Answering using LLMs
Pranoy Panda, Ankush Agarwal, Chaitanya Devaguptapu, Manohar Kaul, Prathosh A P
0
0
Given unstructured text, Large Language Models (LLMs) are adept at answering simple (single-hop) questions. However, as the complexity of the questions increase, the performance of LLMs degrade. We believe this is due to the overhead associated with understanding the complex question followed by filtering and aggregating unstructured information in the raw text. Recent methods try to reduce this burden by integrating structured knowledge triples into the raw text, aiming to provide a structured overview that simplifies information processing. However, this simplistic approach is query-agnostic and the extracted facts are ambiguous as they lack context. To address these drawbacks and to enable LLMs to answer complex (multi-hop) questions with ease, we propose to use a knowledge graph (KG) that is context-aware and is distilled to contain query-relevant information. The use of our compressed distilled KG as input to the LLM results in our method utilizing up to $67%$ fewer tokens to represent the query relevant information present in the supporting documents, compared to the state-of-the-art (SoTA) method. Our experiments show consistent improvements over the SoTA across several metrics (EM, F1, BERTScore, and Human Eval) on two popular benchmark datasets (HotpotQA and MuSiQue).
6/11/2024

Are Large Language Models a Good Replacement of Taxonomies?
Yushi Sun, Hao Xin, Kai Sun, Yifan Ethan Xu, Xiao Yang, Xin Luna Dong, Nan Tang, Lei Chen
0
0
Large language models (LLMs) demonstrate an impressive ability to internalize knowledge and answer natural language questions. Although previous studies validate that LLMs perform well on general knowledge while presenting poor performance on long-tail nuanced knowledge, the community is still doubtful about whether the traditional knowledge graphs should be replaced by LLMs. In this paper, we ask if the schema of knowledge graph (i.e., taxonomy) is made obsolete by LLMs. Intuitively, LLMs should perform well on common taxonomies and at taxonomy levels that are common to people. Unfortunately, there lacks a comprehensive benchmark that evaluates the LLMs over a wide range of taxonomies from common to specialized domains and at levels from root to leaf so that we can draw a confident conclusion. To narrow the research gap, we constructed a novel taxonomy hierarchical structure discovery benchmark named TaxoGlimpse to evaluate the performance of LLMs over taxonomies. TaxoGlimpse covers ten representative taxonomies from common to specialized domains with in-depth experiments of different levels of entities in this taxonomy from root to leaf. Our comprehensive experiments of eighteen state-of-the-art LLMs under three prompting settings validate that LLMs can still not well capture the knowledge of specialized taxonomies and leaf-level entities.
6/21/2024