Audio Simulation for Sound Source Localization in Virtual Evironment
2404.01611
0
0
↗️
Abstract
Non-line-of-sight localization in signal-deprived environments is a challenging yet pertinent problem. Acoustic methods in such predominantly indoor scenarios encounter difficulty due to the reverberant nature. In this study, we aim to locate sound sources to specific locations within a virtual environment by leveraging physically grounded sound propagation simulations and machine learning methods. This process attempts to overcome the issue of data insufficiency to localize sound sources to their location of occurrence especially in post-event localization. We achieve 0.786+/- 0.0136 F1-score using an audio transformer spectrogram approach.
Create account to get full access
Overview
- Locating sound sources in indoor environments without a direct line-of-sight is a challenging problem.
- Acoustic methods often struggle in these reverberant, signal-deprived scenarios.
- This study aims to locate sound sources within a virtual environment using sound propagation simulations and machine learning.
- The goal is to overcome data insufficiency issues, especially for post-event localization.
- The researchers achieved an F1-score of 0.786 ± 0.0136 using an audio transformer spectrogram approach.
Plain English Explanation
Imagine you're trying to find the source of a sound inside a building, but you can't see it directly. This is a common problem, especially in complex indoor environments where sound waves bounce and echo off walls, floors, and furniture. Traditional methods that rely on sound alone often struggle in these situations.
In this study, the researchers tried a different approach. They used computer simulations to model how sound waves would travel through a virtual version of the building. By combining this physical simulation with machine learning techniques, they were able to predict the location of a sound source, even if the direct path to it was blocked.
This is particularly useful for situations where you might need to locate a sound source after the fact, such as investigating a crime or an accident. In these cases, you may not have access to real-time data, so being able to reconstruct the sound's origin from other evidence is valuable.
The researchers were able to achieve a high level of accuracy in their sound source localization, with an F1-score of around 0.786. This means their method was able to correctly identify the location of the sound source most of the time.
Technical Explanation
The researchers used a combination of physically grounded sound propagation simulations and machine learning methods to locate sound sources within a virtual environment. This approach aimed to overcome the challenge of data insufficiency, which can hinder the effectiveness of sound localization, especially in post-event scenarios.
The researchers employed an audio transformer spectrogram model to process the simulated audio data. This deep learning architecture was able to learn the complex patterns and relationships between the sound waves and their propagation within the virtual environment.
By leveraging the physically accurate sound propagation simulations, the researchers were able to generate a larger and more diverse dataset for training the machine learning model. This helped to compensate for the lack of real-world data that is often a limitation in sound localization research.
The experiments conducted by the researchers demonstrated the efficacy of their approach, achieving an impressive F1-score of 0.786 ± 0.0136 in locating sound sources within the virtual environment.
Critical Analysis
The researchers acknowledge that their approach is limited to virtual environments and may not directly translate to real-world scenarios. The fidelity of the sound propagation simulations and the accuracy of the virtual environment model could be potential sources of error that may affect the localization performance.
Additionally, the researchers did not explore the performance of their method in complex, cluttered environments with multiple sound sources or dynamic conditions. Further research would be needed to assess the robustness of the approach in more realistic and challenging settings.
While the researchers achieved high accuracy in their experiments, it would be beneficial to compare their method to other state-of-the-art sound localization techniques to better understand its relative strengths and weaknesses. This could help identify areas for improvement or suggest potential avenues for further research.
Overall, the researchers have presented a promising approach to sound source localization in signal-deprived environments. However, additional validation and testing in real-world scenarios would be necessary to fully assess the practical applicability and broader impact of their work.
Conclusion
This study demonstrates the potential of combining physically grounded sound propagation simulations and machine learning techniques to address the challenge of sound source localization in complex, indoor environments. By leveraging the accuracy of the simulations and the learning capabilities of the audio transformer model, the researchers were able to achieve impressive results in locating sound sources within a virtual environment.
While the approach is currently limited to simulated scenarios, the insights gained from this research could pave the way for more robust and reliable sound localization systems in the future. These advancements could have significant implications for a wide range of applications, from security and surveillance to search and rescue operations, where the ability to quickly and accurately locate sound sources is crucial.
As the field of sound localization continues to evolve, this study serves as a valuable contribution, highlighting the potential of integrating physical simulations and machine learning to overcome the limitations of traditional acoustic methods in signal-deprived environments.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
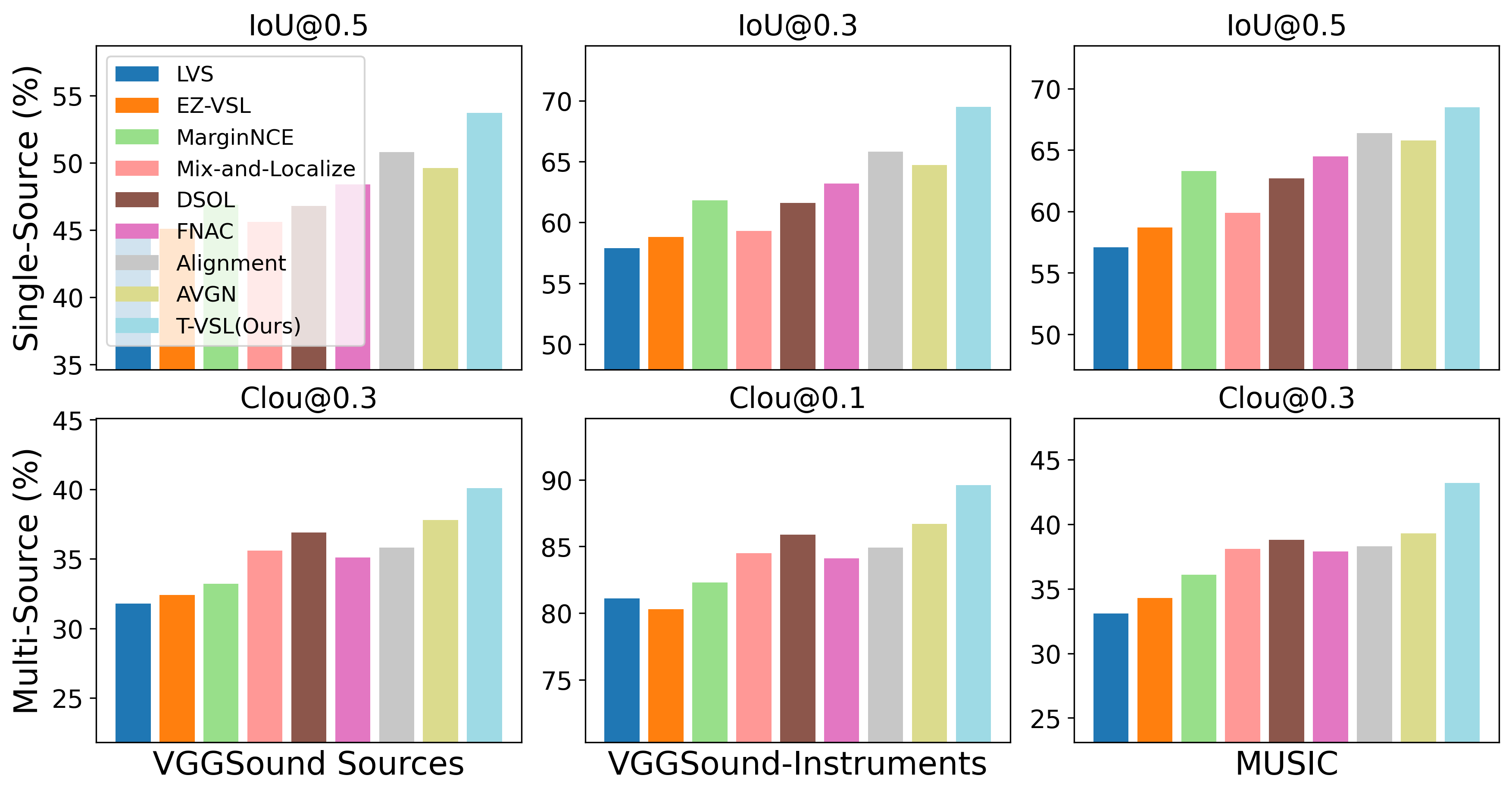
T-VSL: Text-Guided Visual Sound Source Localization in Mixtures
Tanvir Mahmud, Yapeng Tian, Diana Marculescu
0
0
Visual sound source localization poses a significant challenge in identifying the semantic region of each sounding source within a video. Existing self-supervised and weakly supervised source localization methods struggle to accurately distinguish the semantic regions of each sounding object, particularly in multi-source mixtures. These methods often rely on audio-visual correspondence as guidance, which can lead to substantial performance drops in complex multi-source localization scenarios. The lack of access to individual source sounds in multi-source mixtures during training exacerbates the difficulty of learning effective audio-visual correspondence for localization. To address this limitation, in this paper, we propose incorporating the text modality as an intermediate feature guide using tri-modal joint embedding models (e.g., AudioCLIP) to disentangle the semantic audio-visual source correspondence in multi-source mixtures. Our framework, dubbed T-VSL, begins by predicting the class of sounding entities in mixtures. Subsequently, the textual representation of each sounding source is employed as guidance to disentangle fine-grained audio-visual source correspondence from multi-source mixtures, leveraging the tri-modal AudioCLIP embedding. This approach enables our framework to handle a flexible number of sources and exhibits promising zero-shot transferability to unseen classes during test time. Extensive experiments conducted on the MUSIC, VGGSound, and VGGSound-Instruments datasets demonstrate significant performance improvements over state-of-the-art methods.
4/3/2024
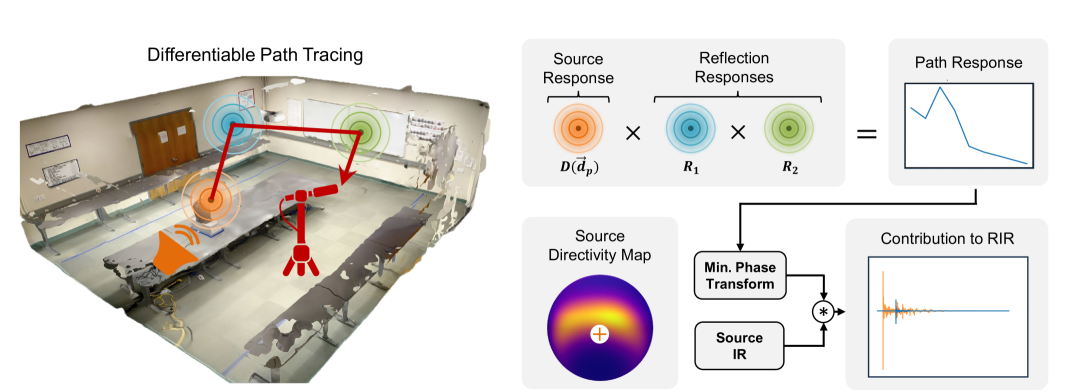
Hearing Anything Anywhere
Mason Wang, Ryosuke Sawata, Samuel Clarke, Ruohan Gao, Shangzhe Wu, Jiajun Wu
0
0
Recent years have seen immense progress in 3D computer vision and computer graphics, with emerging tools that can virtualize real-world 3D environments for numerous Mixed Reality (XR) applications. However, alongside immersive visual experiences, immersive auditory experiences are equally vital to our holistic perception of an environment. In this paper, we aim to reconstruct the spatial acoustic characteristics of an arbitrary environment given only a sparse set of (roughly 12) room impulse response (RIR) recordings and a planar reconstruction of the scene, a setup that is easily achievable by ordinary users. To this end, we introduce DiffRIR, a differentiable RIR rendering framework with interpretable parametric models of salient acoustic features of the scene, including sound source directivity and surface reflectivity. This allows us to synthesize novel auditory experiences through the space with any source audio. To evaluate our method, we collect a dataset of RIR recordings and music in four diverse, real environments. We show that our model outperforms state-ofthe-art baselines on rendering monaural and binaural RIRs and music at unseen locations, and learns physically interpretable parameters characterizing acoustic properties of the sound source and surfaces in the scene.
6/12/2024
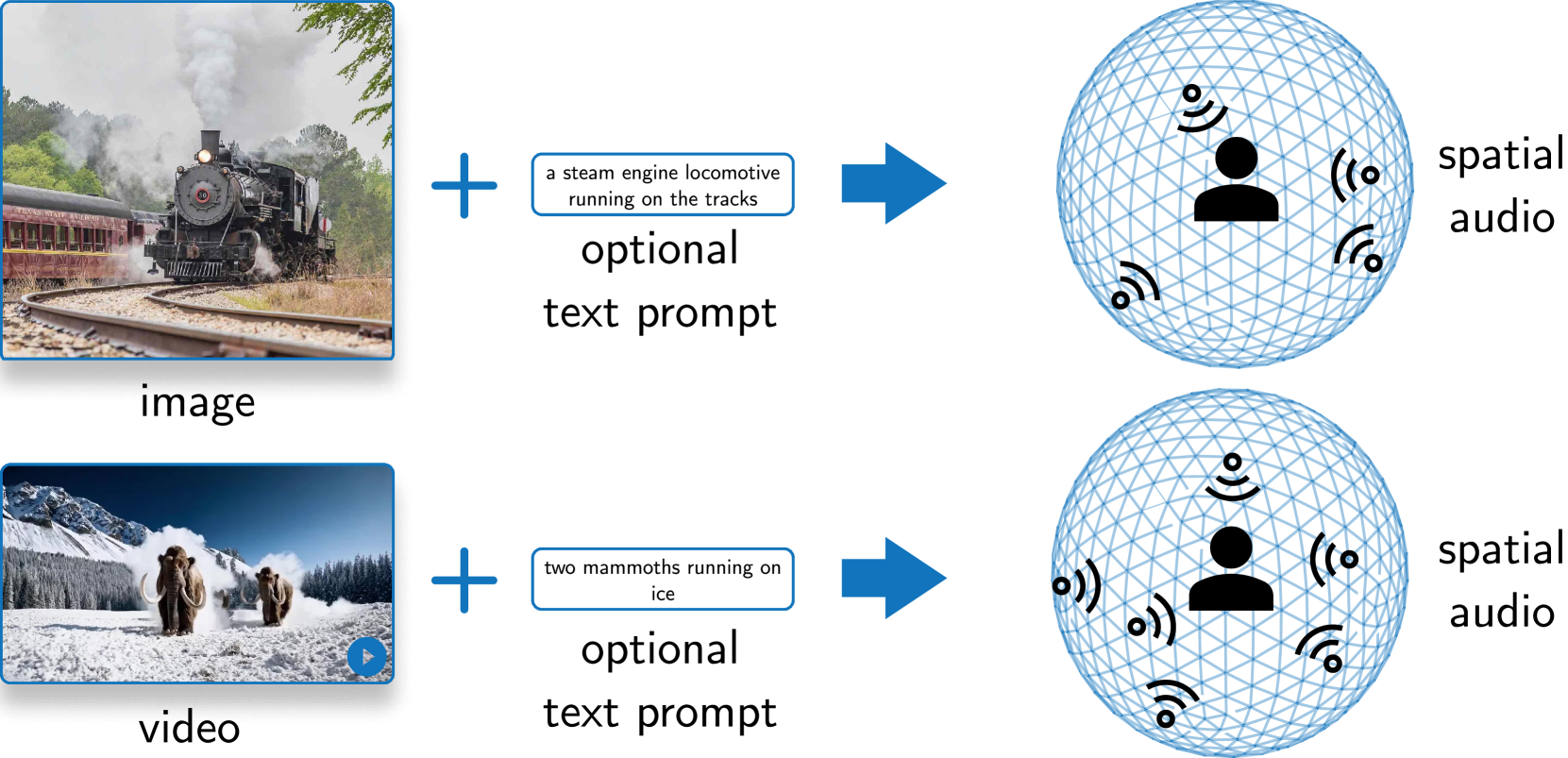
SEE-2-SOUND: Zero-Shot Spatial Environment-to-Spatial Sound
Rishit Dagli, Shivesh Prakash, Robert Wu, Houman Khosravani
0
0
Generating combined visual and auditory sensory experiences is critical for the consumption of immersive content. Recent advances in neural generative models have enabled the creation of high-resolution content across multiple modalities such as images, text, speech, and videos. Despite these successes, there remains a significant gap in the generation of high-quality spatial audio that complements generated visual content. Furthermore, current audio generation models excel in either generating natural audio or speech or music but fall short in integrating spatial audio cues necessary for immersive experiences. In this work, we introduce SEE-2-SOUND, a zero-shot approach that decomposes the task into (1) identifying visual regions of interest; (2) locating these elements in 3D space; (3) generating mono-audio for each; and (4) integrating them into spatial audio. Using our framework, we demonstrate compelling results for generating spatial audio for high-quality videos, images, and dynamic images from the internet, as well as media generated by learned approaches.
6/12/2024

Sound event localization and classification using WASN in Outdoor Environment
Dongzhe Zhang, Jianfeng Chen, Jisheng Bai, Mou Wang
0
0
Deep learning-based sound event localization and classification is an emerging research area within wireless acoustic sensor networks. However, current methods for sound event localization and classification typically rely on a single microphone array, making them susceptible to signal attenuation and environmental noise, which limits their monitoring range. Moreover, methods using multiple microphone arrays often focus solely on source localization, neglecting the aspect of sound event classification. In this paper, we propose a deep learning-based method that employs multiple features and attention mechanisms to estimate the location and class of sound source. We introduce a Soundmap feature to capture spatial information across multiple frequency bands. We also use the Gammatone filter to generate acoustic features more suitable for outdoor environments. Furthermore, we integrate attention mechanisms to learn channel-wise relationships and temporal dependencies within the acoustic features. To evaluate our proposed method, we conduct experiments using simulated datasets with different levels of noise and size of monitoring areas, as well as different arrays and source positions. The experimental results demonstrate the superiority of our proposed method over state-of-the-art methods in both sound event classification and sound source localization tasks. And we provide further analysis to explain the reasons for the observed errors.
4/1/2024