Heat Death of Generative Models in Closed-Loop Learning
2404.02325
0
0
🧠
Abstract
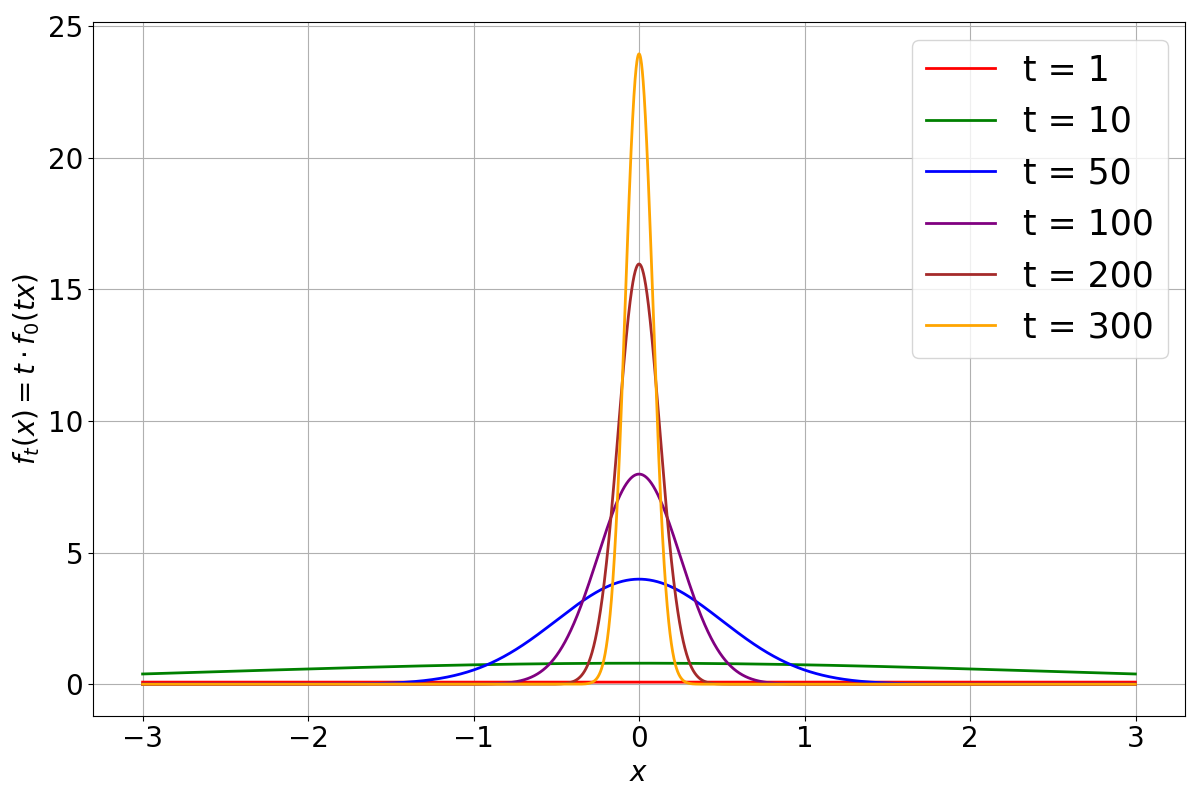
Improvement and adoption of generative machine learning models is rapidly accelerating, as exemplified by the popularity of LLMs (Large Language Models) for text, and diffusion models for image generation.As generative models become widespread, data they generate is incorporated into shared content through the public web. This opens the question of what happens when data generated by a model is fed back to the model in subsequent training campaigns. This is a question about the stability of the training process, whether the distribution of publicly accessible content, which we refer to as knowledge, remains stable or collapses. Small scale empirical experiments reported in the literature show that this closed-loop training process is prone to degenerating. Models may start producing gibberish data, or sample from only a small subset of the desired data distribution (a phenomenon referred to as mode collapse). So far there has been only limited theoretical understanding of this process, in part due to the complexity of the deep networks underlying these generative models. The aim of this paper is to provide insights into this process (that we refer to as generative closed-loop learning) by studying the learning dynamics of generative models that are fed back their own produced content in addition to their original training dataset. The sampling of many of these models can be controlled via a temperature parameter. Using dynamical systems tools, we show that, unless a sufficient amount of external data is introduced at each iteration, any non-trivial temperature leads the model to asymptotically degenerate. In fact, either the generative distribution collapses to a small set of outputs, or becomes uniform over a large set of outputs.
Create account to get full access
Overview
- This paper examines the "heat death" phenomenon in generative models used in closed-loop learning systems.
- Closed-loop learning refers to systems where the model's outputs are fed back as inputs, creating a feedback loop.
- The researchers investigate how this feedback loop can lead to a loss of diversity and eventual stagnation in the generated outputs.
- They propose a theoretical framework to understand this heat death effect and validate it through experiments.
Plain English Explanation
Generative models are AI systems that can create new data, like images or text, based on what they've learned. When these models are used in closed-loop systems, where the output gets fed back as input, an interesting phenomenon can occur.
Imagine a machine learning model that generates images. In a closed-loop system, the generated images could be used to further train the model, creating a feedback loop. Over time, this feedback loop can cause the model to become "stuck," only generating very similar outputs. It's like the model has reached a "heat death" - a point where the diversity of its outputs dwindles and it becomes unable to explore new creative directions.
The researchers in this paper developed a theoretical framework to understand why this heat death occurs. They found that the feedback loop can lead the model to converge on a small set of stable outputs, losing the ability to generate diverse and novel content. Through experiments, they validated this heat death effect and provided insights into the underlying mechanisms.
Understanding this heat death phenomenon is important, as closed-loop learning systems are becoming increasingly common in areas like creative AI and robotics. By recognizing the limitations and potential pitfalls of these systems, researchers can work towards developing more robust and versatile generative models that can maintain their creativity and adaptability over time.
Technical Explanation
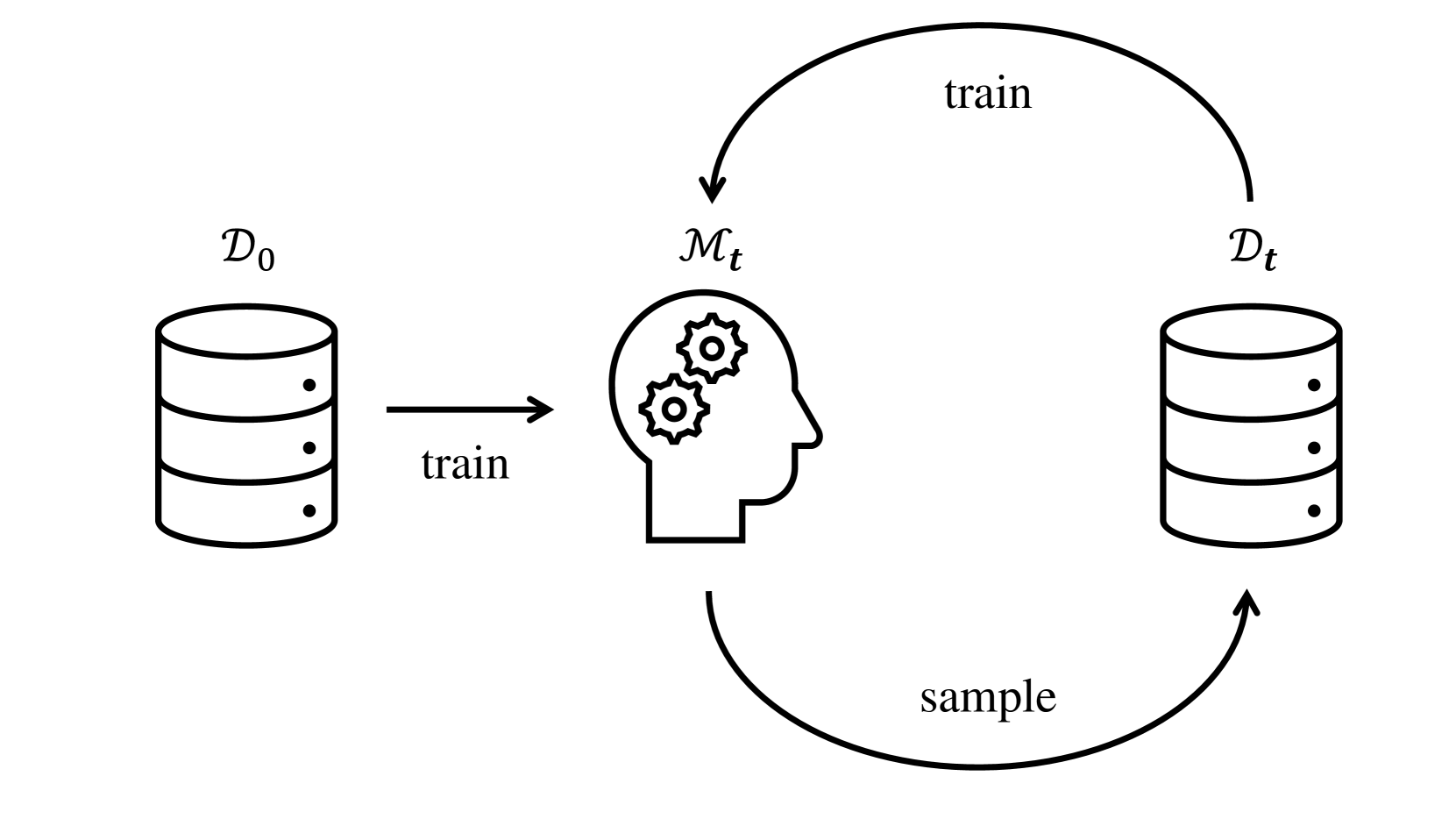
The paper introduces the concept of "heat death" in the context of generative closed-loop learning systems. These are systems where the model's outputs are fed back as inputs, creating a feedback loop that can influence the model's behavior over time.
The researchers develop a theoretical framework to analyze the heat death phenomenon. They model the closed-loop system as a dynamical system and derive conditions under which the system can converge to a stable, low-diversity state - the heat death. This involves analyzing the spectral properties of the feedback operator and the model's reparameterization.
Through experiments, the authors validate the heat death effect in several generative modeling tasks, including image generation and text generation. They show that as the closed-loop system evolves, the diversity of the generated outputs decreases, and the model becomes increasingly stuck in a narrow range of similar outputs.
The paper also discusses potential mitigation strategies, such as introducing external perturbations or considering alternative model architectures and training objectives. The findings have implications for the design and deployment of closed-loop learning systems, particularly in domains where maintaining creativity and adaptability is crucial.
Critical Analysis
The paper provides a well-grounded theoretical foundation for understanding the heat death phenomenon in generative closed-loop learning systems. The authors' analysis of the underlying dynamics is thorough and the experimental validation is convincing.
However, the paper does not delve deeply into the practical implications and potential solutions to this problem. While it mentions some mitigation strategies, further exploration of their effectiveness and applicability to real-world scenarios would be valuable.
Additionally, the paper focuses on relatively simple generative modeling tasks and does not consider more complex, hierarchical systems. It would be interesting to see how the heat death effect scales and manifests in more sophisticated closed-loop architectures.
Another area for further investigation is the interplay between the closed-loop dynamics and the model's inductive biases. The paper suggests that the reparameterization of the model plays a role in the heat death, but a more detailed examination of how different architectural choices and training approaches could influence the system's long-term behavior would provide deeper insights.
Overall, this paper makes an important contribution to the understanding of closed-loop learning systems and their potential limitations. Continued research in this direction, with a focus on practical solutions and applications, could lead to the development of more robust and versatile generative models.
Conclusion
This paper sheds light on the "heat death" phenomenon that can occur in generative closed-loop learning systems, where the model's outputs are fed back as inputs. The researchers develop a theoretical framework to analyze this effect and demonstrate its manifestation in various generative modeling tasks.
The findings highlight the potential pitfalls of closed-loop learning, where the feedback loop can lead to a loss of diversity and the model becoming stuck in a narrow range of similar outputs. Understanding this heat death effect is crucial as these types of systems become more prevalent in areas like creative AI and robotics, where maintaining adaptability and creativity is essential.
While the paper provides a solid theoretical foundation, further research is needed to explore practical solutions and scale the analysis to more complex closed-loop architectures. By addressing the heat death challenge, the field can work towards developing generative models that can thrive in dynamic, closed-loop environments and continue to generate diverse and novel outputs over time.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Mathematical Model of the Hidden Feedback Loop Effect in Machine Learning Systems
Andrey Veprikov, Alexander Afanasiev, Anton Khritankov
0
0
Widespread deployment of societal-scale machine learning systems necessitates a thorough understanding of the resulting long-term effects these systems have on their environment, including loss of trustworthiness, bias amplification, and violation of AI safety requirements. We introduce a repeated learning process to jointly describe several phenomena attributed to unintended hidden feedback loops, such as error amplification, induced concept drift, echo chambers and others. The process comprises the entire cycle of obtaining the data, training the predictive model, and delivering predictions to end-users within a single mathematical model. A distinctive feature of such repeated learning setting is that the state of the environment becomes causally dependent on the learner itself over time, thus violating the usual assumptions about the data distribution. We present a novel dynamical systems model of the repeated learning process and prove the limiting set of probability distributions for positive and negative feedback loop modes of the system operation. We conduct a series of computational experiments using an exemplary supervised learning problem on two synthetic data sets. The results of the experiments correspond to the theoretical predictions derived from the dynamical model. Our results demonstrate the feasibility of the proposed approach for studying the repeated learning processes in machine learning systems and open a range of opportunities for further research in the area.
5/7/2024
Large Language Models Suffer From Their Own Output: An Analysis of the Self-Consuming Training Loop
Martin Briesch, Dominik Sobania, Franz Rothlauf
0
0
Large Language Models (LLM) are already widely used to generate content for a variety of online platforms. As we are not able to safely distinguish LLM-generated content from human-produced content, LLM-generated content is used to train the next generation of LLMs, giving rise to a self-consuming training loop. From the image generation domain we know that such a self-consuming training loop reduces both quality and diversity of images finally ending in a model collapse. However, it is unclear whether this alarming effect can also be observed for LLMs. Therefore, we present the first study investigating the self-consuming training loop for LLMs. Further, we propose a novel method based on logic expressions that allows us to unambiguously verify the correctness of LLM-generated content, which is difficult for natural language text. We find that the self-consuming training loop produces correct outputs, however, the output declines in its diversity depending on the proportion of the used generated data. Fresh data can slow down this decline, but not stop it. Given these concerning results, we encourage researchers to study methods to negate this process.
6/18/2024
🏋️
The Curse of Recursion: Training on Generated Data Makes Models Forget
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, Ross Anderson
0
0
Stable Diffusion revolutionised image creation from descriptive text. GPT-2, GPT-3(.5) and GPT-4 demonstrated astonishing performance across a variety of language tasks. ChatGPT introduced such language models to the general public. It is now clear that large language models (LLMs) are here to stay, and will bring about drastic change in the whole ecosystem of online text and images. In this paper we consider what the future might hold. What will happen to GPT-{n} once LLMs contribute much of the language found online? We find that use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear. We refer to this effect as Model Collapse and show that it can occur in Variational Autoencoders, Gaussian Mixture Models and LLMs. We build theoretical intuition behind the phenomenon and portray its ubiquity amongst all learned generative models. We demonstrate that it has to be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of content generated by LLMs in data crawled from the Internet.
4/16/2024
🔎
Towards Theoretical Understandings of Self-Consuming Generative Models
Shi Fu, Sen Zhang, Yingjie Wang, Xinmei Tian, Dacheng Tao
0
0
This paper tackles the emerging challenge of training generative models within a self-consuming loop, wherein successive generations of models are recursively trained on mixtures of real and synthetic data from previous generations. We construct a theoretical framework to rigorously evaluate how this training procedure impacts the data distributions learned by future models, including parametric and non-parametric models. Specifically, we derive bounds on the total variation (TV) distance between the synthetic data distributions produced by future models and the original real data distribution under various mixed training scenarios for diffusion models with a one-hidden-layer neural network score function. Our analysis demonstrates that this distance can be effectively controlled under the condition that mixed training dataset sizes or proportions of real data are large enough. Interestingly, we further unveil a phase transition induced by expanding synthetic data amounts, proving theoretically that while the TV distance exhibits an initial ascent, it declines beyond a threshold point. Finally, we present results for kernel density estimation, delivering nuanced insights such as the impact of mixed data training on error propagation.
6/26/2024