Towards Theoretical Understandings of Self-Consuming Generative Models
2402.11778
0
0
🔎
Abstract
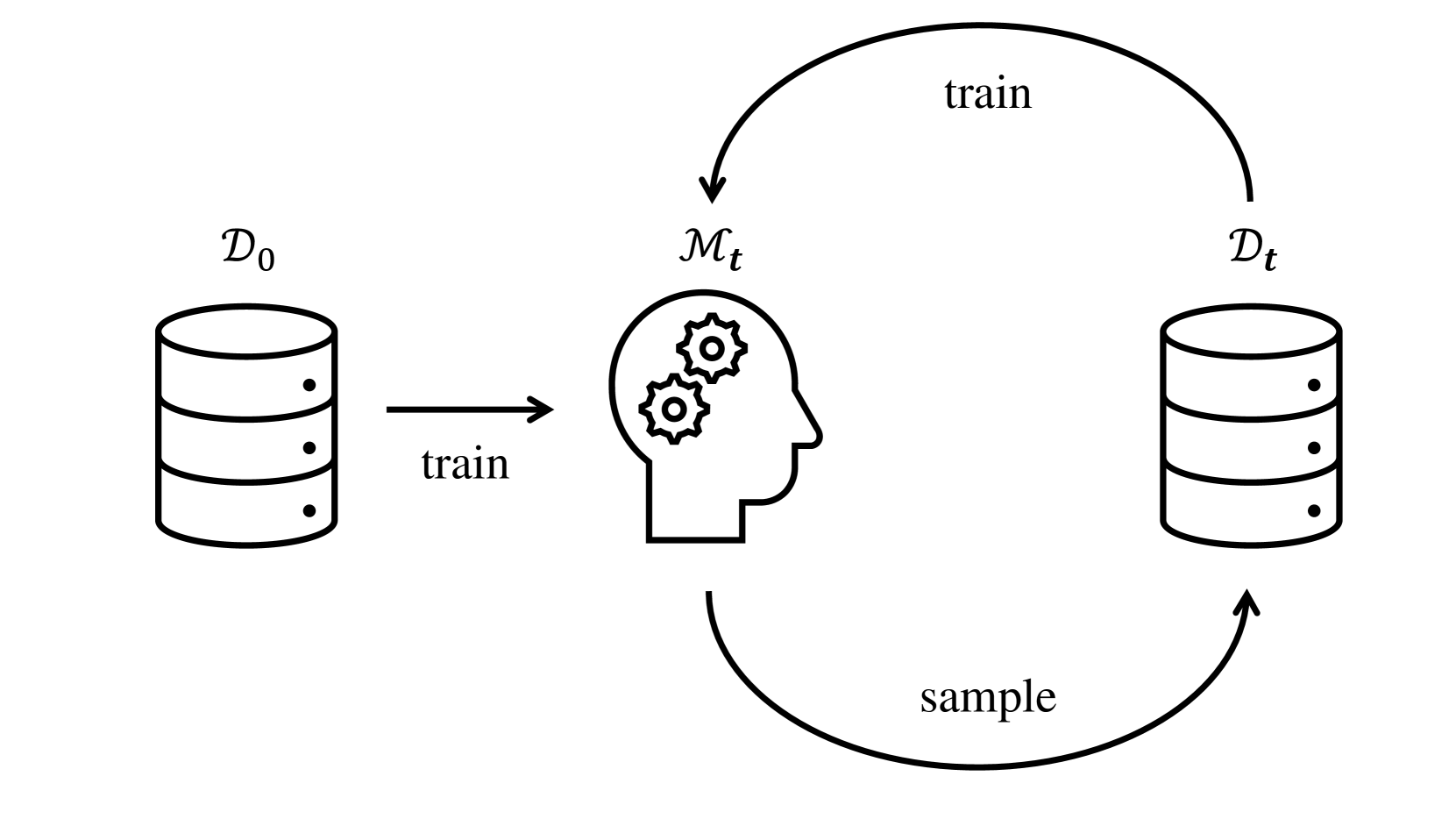
This paper tackles the emerging challenge of training generative models within a self-consuming loop, wherein successive generations of models are recursively trained on mixtures of real and synthetic data from previous generations. We construct a theoretical framework to rigorously evaluate how this training procedure impacts the data distributions learned by future models, including parametric and non-parametric models. Specifically, we derive bounds on the total variation (TV) distance between the synthetic data distributions produced by future models and the original real data distribution under various mixed training scenarios for diffusion models with a one-hidden-layer neural network score function. Our analysis demonstrates that this distance can be effectively controlled under the condition that mixed training dataset sizes or proportions of real data are large enough. Interestingly, we further unveil a phase transition induced by expanding synthetic data amounts, proving theoretically that while the TV distance exhibits an initial ascent, it declines beyond a threshold point. Finally, we present results for kernel density estimation, delivering nuanced insights such as the impact of mixed data training on error propagation.
Create account to get full access
Overview
- This paper explores the challenges of training generative models in a self-consuming loop, where successive generations of models are recursively trained on a mix of real and synthetic data.
- The researchers develop a theoretical framework to analyze how this training procedure impacts the data distributions learned by future models, including both parametric and non-parametric models.
- They derive bounds on the total variation (TV) distance between the synthetic data distributions produced by future models and the original real data distribution under various mixed training scenarios for diffusion models with a one-hidden-layer neural network score function.
Plain English Explanation
The paper examines a scenario where generative models are trained in a self-consuming loop. In this loop, each new generation of models is trained on a mix of real data and synthetic data generated by the previous generation of models.
The researchers wanted to understand how this recursive training process affects the data distributions that the future models learn. They focused on a specific type of generative model called a diffusion model with a simple neural network architecture.
The key finding is that the distance between the synthetic data and the original real data can be controlled, as long as the mixed training dataset is large enough or contains a sufficient proportion of real data. Interestingly, the researchers also found a "phase transition" – the distance initially increases as more synthetic data is used, but then starts to decline beyond a certain threshold.
The paper also looks at the impact of this mixed training on kernel density estimation, which is a way to estimate the probability distribution of data. The researchers provide nuanced insights into how the mixed training affects the propagation of errors in this estimation process.
Technical Explanation
The researchers construct a theoretical framework to analyze how the self-consuming training loop impacts the data distributions learned by future generations of generative models. Specifically, they derive bounds on the total variation (TV) distance between the synthetic data distributions produced by future models and the original real data distribution.
They consider diffusion models with a one-hidden-layer neural network score function, and explore various mixed training scenarios where the models are trained on a combination of real and synthetic data. The analysis demonstrates that the TV distance can be effectively controlled, provided that the mixed training dataset sizes or proportions of real data are large enough.
Interestingly, the researchers also unveil a "phase transition" effect, where the TV distance initially exhibits an ascent as the amount of synthetic data is expanded, but then declines beyond a certain threshold. This suggests that there may be an optimal balance between real and synthetic data in the mixed training datasets.
Furthermore, the paper presents results for kernel density estimation, revealing nuanced insights into how the mixed data training impacts the propagation of errors in this estimation process.
Critical Analysis
The paper provides a rigorous theoretical analysis of the self-consuming training loop for generative models, which is an important and emerging challenge in the field. The researchers' framework and insights offer valuable guidance for practitioners working with these types of models.
However, the paper also acknowledges several caveats and limitations. For example, the analysis is focused on a specific type of diffusion model with a relatively simple neural network architecture. It remains to be seen how the findings would extend to more complex model architectures or other types of generative models, such as large language models.
Additionally, the paper does not address the potential issues that may arise from the data pollution caused by the self-consuming training loop, such as the amplification of biases or the introduction of anomalies in the synthetic data. These are important considerations that future research should explore.
Overall, the paper provides a solid theoretical foundation for understanding the challenges of self-consuming training loops, but more work is needed to fully characterize the implications and develop practical mitigation strategies.
Conclusion
This paper tackles the emerging challenge of training generative models within a self-consuming loop, where successive generations of models are recursively trained on a mix of real and synthetic data. The researchers construct a theoretical framework to analyze the impact of this training procedure on the data distributions learned by future models.
The key finding is that the distance between the synthetic data and the original real data can be effectively controlled, as long as the mixed training dataset is large enough or contains a sufficient proportion of real data. Interestingly, the researchers also uncover a "phase transition" effect, where the distance initially increases but then starts to decline beyond a certain threshold.
The paper also explores the impact of mixed training on kernel density estimation, providing nuanced insights into how the process affects the propagation of errors. While the theoretical analysis offers valuable guidance, the researchers acknowledge several caveats and limitations that warrant further investigation, such as the potential issues arising from data pollution in the self-consuming loop.
Overall, this work contributes to our understanding of the challenges and trade-offs involved in training generative models in a self-consuming manner, paving the way for the development of more robust and reliable AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Self-Correcting Self-Consuming Loops for Generative Model Training
Nate Gillman, Michael Freeman, Daksh Aggarwal, Chia-Hong Hsu, Calvin Luo, Yonglong Tian, Chen Sun
0
0
As synthetic data becomes higher quality and proliferates on the internet, machine learning models are increasingly trained on a mix of human- and machine-generated data. Despite the successful stories of using synthetic data for representation learning, using synthetic data for generative model training creates self-consuming loops which may lead to training instability or even collapse, unless certain conditions are met. Our paper aims to stabilize self-consuming generative model training. Our theoretical results demonstrate that by introducing an idealized correction function, which maps a data point to be more likely under the true data distribution, self-consuming loops can be made exponentially more stable. We then propose self-correction functions, which rely on expert knowledge (e.g. the laws of physics programmed in a simulator), and aim to approximate the idealized corrector automatically and at scale. We empirically validate the effectiveness of self-correcting self-consuming loops on the challenging human motion synthesis task, and observe that it successfully avoids model collapse, even when the ratio of synthetic data to real data is as high as 100%.
6/11/2024
📊
On the Stability of Iterative Retraining of Generative Models on their own Data
Quentin Bertrand, Avishek Joey Bose, Alexandre Duplessis, Marco Jiralerspong, Gauthier Gidel
0
0
Deep generative models have made tremendous progress in modeling complex data, often exhibiting generation quality that surpasses a typical human's ability to discern the authenticity of samples. Undeniably, a key driver of this success is enabled by the massive amounts of web-scale data consumed by these models. Due to these models' striking performance and ease of availability, the web will inevitably be increasingly populated with synthetic content. Such a fact directly implies that future iterations of generative models will be trained on both clean and artificially generated data from past models. In this paper, we develop a framework to rigorously study the impact of training generative models on mixed datasets -- from classical training on real data to self-consuming generative models trained on purely synthetic data. We first prove the stability of iterative training under the condition that the initial generative models approximate the data distribution well enough and the proportion of clean training data (w.r.t. synthetic data) is large enough. We empirically validate our theory on both synthetic and natural images by iteratively training normalizing flows and state-of-the-art diffusion models on CIFAR10 and FFHQ.
4/3/2024
🤖
When AI Eats Itself: On the Caveats of Data Pollution in the Era of Generative AI
Xiaodan Xing, Fadong Shi, Jiahao Huang, Yinzhe Wu, Yang Nan, Sheng Zhang, Yingying Fang, Mike Roberts, Carola-Bibiane Schonlieb, Javier Del Ser, Guang Yang
0
0
Generative artificial intelligence (AI) technologies and large models are producing realistic outputs across various domains, such as images, text, speech, and music. Creating these advanced generative models requires significant resources, particularly large and high-quality datasets. To minimize training expenses, many algorithm developers use data created by the models themselves as a cost-effective training solution. However, not all synthetic data effectively improve model performance, necessitating a strategic balance in the use of real versus synthetic data to optimize outcomes. Currently, the previously well-controlled integration of real and synthetic data is becoming uncontrollable. The widespread and unregulated dissemination of synthetic data online leads to the contamination of datasets traditionally compiled through web scraping, now mixed with unlabeled synthetic data. This trend portends a future where generative AI systems may increasingly rely blindly on consuming self-generated data, raising concerns about model performance and ethical issues. What will happen if generative AI continuously consumes itself without discernment? What measures can we take to mitigate the potential adverse effects? There is a significant gap in the scientific literature regarding the impact of synthetic data use in generative AI, particularly in terms of the fusion of multimodal information. To address this research gap, this review investigates the consequences of integrating synthetic data blindly on training generative AI on both image and text modalities and explores strategies to mitigate these effects. The goal is to offer a comprehensive view of synthetic data's role, advocating for a balanced approach to its use and exploring practices that promote the sustainable development of generative AI technologies in the era of large models.
5/17/2024
Large Language Models Suffer From Their Own Output: An Analysis of the Self-Consuming Training Loop
Martin Briesch, Dominik Sobania, Franz Rothlauf
0
0
Large Language Models (LLM) are already widely used to generate content for a variety of online platforms. As we are not able to safely distinguish LLM-generated content from human-produced content, LLM-generated content is used to train the next generation of LLMs, giving rise to a self-consuming training loop. From the image generation domain we know that such a self-consuming training loop reduces both quality and diversity of images finally ending in a model collapse. However, it is unclear whether this alarming effect can also be observed for LLMs. Therefore, we present the first study investigating the self-consuming training loop for LLMs. Further, we propose a novel method based on logic expressions that allows us to unambiguously verify the correctness of LLM-generated content, which is difficult for natural language text. We find that the self-consuming training loop produces correct outputs, however, the output declines in its diversity depending on the proportion of the used generated data. Fresh data can slow down this decline, but not stop it. Given these concerning results, we encourage researchers to study methods to negate this process.
6/18/2024