Large Language Models Suffer From Their Own Output: An Analysis of the Self-Consuming Training Loop
2311.16822
0
0
Abstract
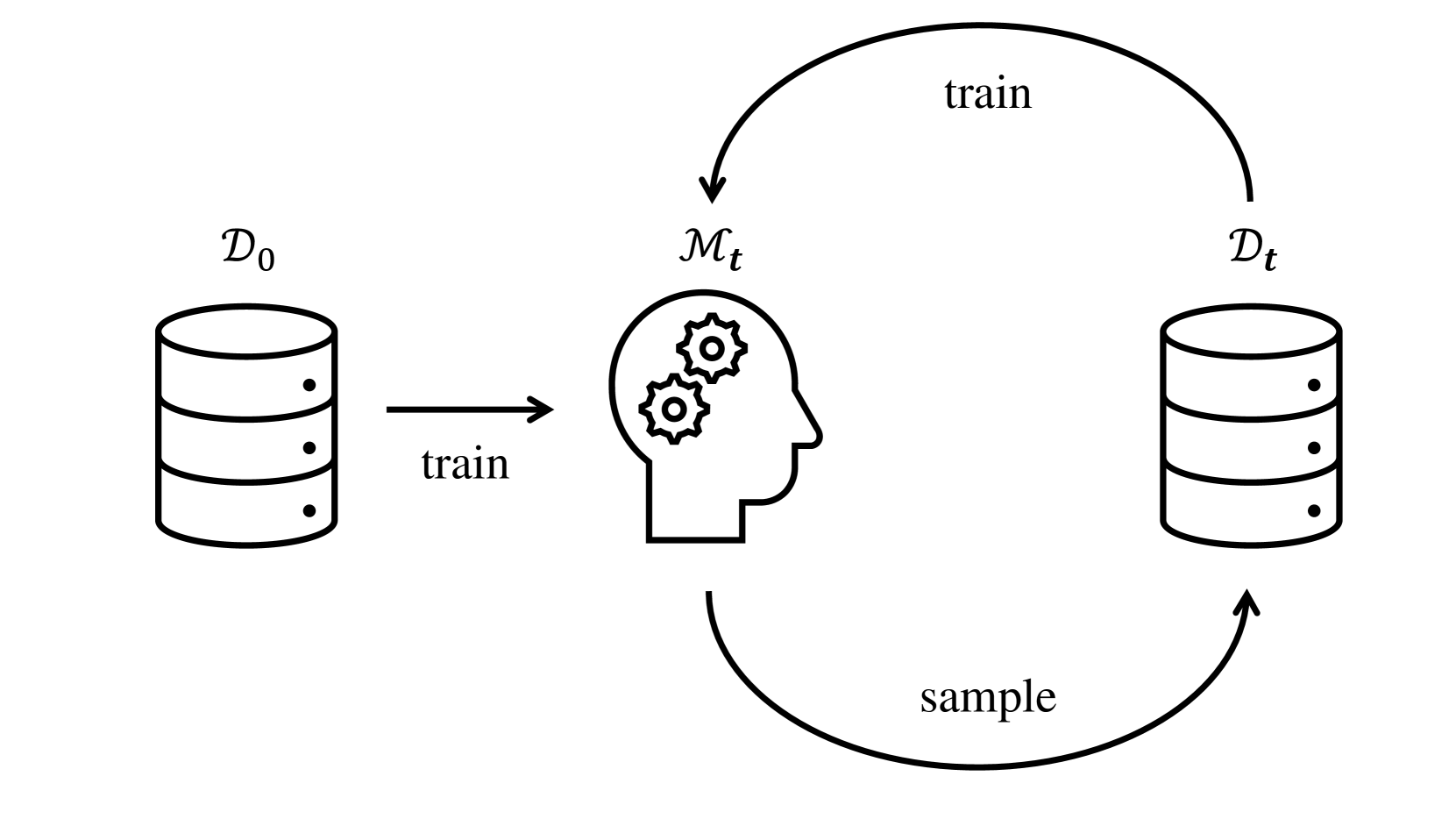
Large Language Models (LLM) are already widely used to generate content for a variety of online platforms. As we are not able to safely distinguish LLM-generated content from human-produced content, LLM-generated content is used to train the next generation of LLMs, giving rise to a self-consuming training loop. From the image generation domain we know that such a self-consuming training loop reduces both quality and diversity of images finally ending in a model collapse. However, it is unclear whether this alarming effect can also be observed for LLMs. Therefore, we present the first study investigating the self-consuming training loop for LLMs. Further, we propose a novel method based on logic expressions that allows us to unambiguously verify the correctness of LLM-generated content, which is difficult for natural language text. We find that the self-consuming training loop produces correct outputs, however, the output declines in its diversity depending on the proportion of the used generated data. Fresh data can slow down this decline, but not stop it. Given these concerning results, we encourage researchers to study methods to negate this process.
Create account to get full access
Overview
- This paper examines the phenomenon of "self-consuming training loops" in large language models (LLMs), where the model's own generated output is fed back into the training process.
- The researchers analyze the potential issues that can arise from this self-consuming training loop, including a lack of diversity in the model's output and the amplification of biases.
- The paper also discusses various techniques that have been proposed to address these challenges, such as generation-driven contrastive self-training and self-training through knowledge.
Plain English Explanation
Large language models, like the ones used in chatbots and language assistants, are trained on huge amounts of text data from the internet. During the training process, the model starts to generate its own output, which can then be fed back into the training process. This creates a "self-consuming training loop" where the model is essentially training on its own output.
The researchers behind this paper found that this self-consuming training loop can cause some issues. For example, the model may start to produce less diverse output, as it becomes more and more focused on generating text that is similar to what it has produced before. This can lead to a lack of creativity and a narrowing of the model's capabilities.
Additionally, the researchers found that the self-consuming training loop can amplify any biases or errors that are present in the model's initial output. This means that if the model starts generating text that contains biases or inaccuracies, those issues can become more and more pronounced as the training process continues.
To address these challenges, the researchers discuss several techniques that have been proposed, such as generation-driven contrastive self-training and self-training through knowledge. These approaches aim to introduce more diversity and accuracy into the training process, helping to counteract the negative effects of the self-consuming training loop.
Technical Explanation
The paper begins by describing the phenomenon of the "self-consuming training loop" in large language models (LLMs). As LLMs are trained on large datasets of text, they gradually learn to generate their own text that resembles the input data. This generated text can then be fed back into the training process, creating a loop where the model is essentially training on its own output.
The researchers conducted experiments to explore the potential issues that can arise from this self-consuming training loop. They found that it can lead to a lack of diversity in the model's output, as the model becomes increasingly focused on generating text that is similar to what it has produced before. This can result in the model becoming less creative and more limited in its capabilities.
Additionally, the researchers found that the self-consuming training loop can amplify any biases or errors that are present in the model's initial output. This is because the model's own generated text, which may contain biases or inaccuracies, is then used to further train the model, leading to the perpetuation and amplification of these issues.
To address these challenges, the researchers discuss several techniques that have been proposed, such as generation-driven contrastive self-training and self-training through knowledge. These approaches aim to introduce more diversity and accuracy into the training process by incorporating external data or knowledge sources, helping to counteract the negative effects of the self-consuming training loop.
Critical Analysis
The researchers in this paper have done a thorough job of identifying and analyzing the potential issues that can arise from the self-consuming training loop in large language models. Their findings around the loss of diversity and the amplification of biases are particularly concerning, as these issues could have significant implications for the real-world applications of these models.
One potential limitation of the study is that it focuses primarily on the self-consuming training loop in isolation, without considering other factors that may also contribute to these problems. For example, the initial dataset and model architecture used for training could also play a significant role in shaping the model's output and biases.
Additionally, the paper does not provide a comprehensive evaluation of the proposed techniques for addressing the self-consuming training loop. While the researchers discuss these approaches, more detailed analysis and empirical testing would be needed to fully assess their effectiveness and practical implications.
Overall, this paper makes an important contribution to the ongoing discussion around the challenges and limitations of large language models. By highlighting the risks of self-consuming training loops, the researchers encourage the AI community to think critically about the design and deployment of these powerful models, and to continue exploring innovative solutions to ensure their safe and responsible use.
Conclusion
This paper sheds light on the phenomenon of "self-consuming training loops" in large language models, where the model's own generated output is fed back into the training process. The researchers found that this can lead to a lack of diversity in the model's output and the amplification of biases, which could have significant implications for the real-world applications of these models.
To address these challenges, the researchers discuss various techniques that have been proposed, such as generation-driven contrastive self-training and self-training through knowledge. These approaches aim to introduce more diversity and accuracy into the training process, helping to counteract the negative effects of the self-consuming training loop.
As large language models continue to play an increasingly important role in our lives, it is crucial that the AI community remains vigilant in identifying and addressing the potential pitfalls of these powerful systems. The insights and recommendations provided in this paper offer valuable guidance for the responsible development and deployment of large language models, with the ultimate goal of ensuring their safe and beneficial use for society.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Self-Correcting Self-Consuming Loops for Generative Model Training
Nate Gillman, Michael Freeman, Daksh Aggarwal, Chia-Hong Hsu, Calvin Luo, Yonglong Tian, Chen Sun
0
0
As synthetic data becomes higher quality and proliferates on the internet, machine learning models are increasingly trained on a mix of human- and machine-generated data. Despite the successful stories of using synthetic data for representation learning, using synthetic data for generative model training creates self-consuming loops which may lead to training instability or even collapse, unless certain conditions are met. Our paper aims to stabilize self-consuming generative model training. Our theoretical results demonstrate that by introducing an idealized correction function, which maps a data point to be more likely under the true data distribution, self-consuming loops can be made exponentially more stable. We then propose self-correction functions, which rely on expert knowledge (e.g. the laws of physics programmed in a simulator), and aim to approximate the idealized corrector automatically and at scale. We empirically validate the effectiveness of self-correcting self-consuming loops on the challenging human motion synthesis task, and observe that it successfully avoids model collapse, even when the ratio of synthetic data to real data is as high as 100%.
6/11/2024
🏋️
The Curse of Recursion: Training on Generated Data Makes Models Forget
Ilia Shumailov, Zakhar Shumaylov, Yiren Zhao, Yarin Gal, Nicolas Papernot, Ross Anderson
0
0
Stable Diffusion revolutionised image creation from descriptive text. GPT-2, GPT-3(.5) and GPT-4 demonstrated astonishing performance across a variety of language tasks. ChatGPT introduced such language models to the general public. It is now clear that large language models (LLMs) are here to stay, and will bring about drastic change in the whole ecosystem of online text and images. In this paper we consider what the future might hold. What will happen to GPT-{n} once LLMs contribute much of the language found online? We find that use of model-generated content in training causes irreversible defects in the resulting models, where tails of the original content distribution disappear. We refer to this effect as Model Collapse and show that it can occur in Variational Autoencoders, Gaussian Mixture Models and LLMs. We build theoretical intuition behind the phenomenon and portray its ubiquity amongst all learned generative models. We demonstrate that it has to be taken seriously if we are to sustain the benefits of training from large-scale data scraped from the web. Indeed, the value of data collected about genuine human interactions with systems will be increasingly valuable in the presence of content generated by LLMs in data crawled from the Internet.
4/16/2024
Self-training Large Language Models through Knowledge Detection
Wei Jie Yeo, Teddy Ferdinan, Przemyslaw Kazienko, Ranjan Satapathy, Erik Cambria
0
0
Large language models (LLMs) often necessitate extensive labeled datasets and training compute to achieve impressive performance across downstream tasks. This paper explores a self-training paradigm, where the LLM autonomously curates its own labels and selectively trains on unknown data samples identified through a reference-free consistency method. Empirical evaluations demonstrate significant improvements in reducing hallucination in generation across multiple subjects. Furthermore, the selective training framework mitigates catastrophic forgetting in out-of-distribution benchmarks, addressing a critical limitation in training LLMs. Our findings suggest that such an approach can substantially reduce the dependency on large labeled datasets, paving the way for more scalable and cost-effective language model training.
6/18/2024
🔎
Towards Theoretical Understandings of Self-Consuming Generative Models
Shi Fu, Sen Zhang, Yingjie Wang, Xinmei Tian, Dacheng Tao
0
0
This paper tackles the emerging challenge of training generative models within a self-consuming loop, wherein successive generations of models are recursively trained on mixtures of real and synthetic data from previous generations. We construct a theoretical framework to rigorously evaluate how this training procedure impacts the data distributions learned by future models, including parametric and non-parametric models. Specifically, we derive bounds on the total variation (TV) distance between the synthetic data distributions produced by future models and the original real data distribution under various mixed training scenarios for diffusion models with a one-hidden-layer neural network score function. Our analysis demonstrates that this distance can be effectively controlled under the condition that mixed training dataset sizes or proportions of real data are large enough. Interestingly, we further unveil a phase transition induced by expanding synthetic data amounts, proving theoretically that while the TV distance exhibits an initial ascent, it declines beyond a threshold point. Finally, we present results for kernel density estimation, delivering nuanced insights such as the impact of mixed data training on error propagation.
6/26/2024