HetHub: A Heterogeneous distributed hybrid training system for large-scale models

0

Sign in to get full access
Overview
- Introduces a distributed training approach for machine learning models across heterogeneous hardware resources
- Proposes a novel algorithm called "Holmes" to enable efficient training across diverse cluster environments
- Compares Holmes to other state-of-the-art techniques for distributed and parallel training
Plain English Explanation
The paper discusses a technique called "Holmes" that aims to make it easier to train machine learning models across a variety of different computer hardware. This is an important problem because modern AI models can require massive amounts of computing power, which is often spread across many different servers or devices with varying capabilities.
The Holmes technique tries to address this by dynamically adjusting the training workload and resource allocation to match the available hardware. This allows the training to happen more efficiently, without any one part of the system becoming a bottleneck.
The paper compares Holmes to other approaches for distributed and parallel training, such as 4D-Hybrid, Universal Performance Modeling, and RavNest. It shows that Holmes can provide better performance and resource utilization, especially in heterogeneous environments where the hardware capabilities vary widely.
Technical Explanation
The paper introduces a distributed training approach called "Holmes" that aims to efficiently utilize diverse hardware resources in a cluster environment. The key components of the Holmes system include:
-
Data Parallelism: Holmes leverages data parallelism, where multiple workers process different subsets of the training data simultaneously. This helps to speed up the overall training process.
-
Heterogeneous Resource Allocation: Holmes dynamically allocates training workloads to workers based on their individual hardware capabilities. This helps to avoid bottlenecks and ensure that all resources are utilized efficiently.
-
Adaptive Gradient Aggregation: Holmes uses an adaptive gradient aggregation scheme to combine the updates from different workers, accounting for their varying compute speeds and hardware configurations.
-
Decentralized Training Coordination: Holmes employs a decentralized training coordination approach, where workers communicate directly with each other to coordinate the training process. This avoids the need for a central coordinator, which can become a performance bottleneck.
The paper evaluates the performance of Holmes on several benchmark tasks and compares it to other state-of-the-art techniques for distributed and parallel training, such as 4D-Hybrid, Universal Performance Modeling, and RavNest. The results demonstrate that Holmes can outperform these other approaches, especially in heterogeneous hardware environments.
Critical Analysis
The paper provides a comprehensive evaluation of the Holmes technique and highlights its key advantages over other distributed training approaches. However, the authors also acknowledge several caveats and limitations:
-
Hardware-Specific Optimization: The performance of Holmes is heavily dependent on the specific hardware configurations in the cluster. The authors suggest that further hardware-specific optimizations may be necessary to achieve optimal performance.
-
Communication Overhead: The decentralized training coordination approach used by Holmes can introduce additional communication overhead, which may impact performance on certain workloads or network topologies.
-
Scalability Limits: While Holmes demonstrates good scalability, the authors note that there may be practical limits to the number of workers that can be effectively utilized, depending on the specific problem and hardware setup.
-
Heterogeneity Assumptions: The paper assumes a certain degree of heterogeneity in the hardware resources, but it is unclear how Holmes would perform in more homogeneous environments.
Overall, the paper presents a promising approach for distributed training of machine learning models, particularly in the context of heterogeneous hardware resources. However, further research and experimentation may be needed to fully understand the limitations and potential areas for improvement.
Conclusion
The "Holmes" technique introduced in this paper represents an important contribution to the field of distributed machine learning training. By dynamically allocating workloads and coordinating the training process in a decentralized manner, Holmes can effectively utilize diverse hardware resources and outperform other state-of-the-art approaches, especially in heterogeneous environments.
The paper's findings have significant implications for the development of large-scale AI systems, which often require massive computational resources. The Holmes approach could help to make the training of these models more efficient and scalable, potentially leading to faster development cycles and more accessible AI capabilities.
While the paper highlights some caveats and areas for further research, the overall results are compelling and suggest that the Holmes technique is a valuable addition to the toolbox of distributed training algorithms. As the demand for powerful AI models continues to grow, techniques like Holmes will become increasingly important in enabling the Next Generation of Artificial Intelligence.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HetHub: A Heterogeneous distributed hybrid training system for large-scale models
Si Xu, Zixiao Huang, Yan Zeng, Shengen Yan, Xuefei Ning, Quanlu Zhang, Haolin Ye, Sipei Gu, Chunsheng Shui, Zhezheng Lin, Hao Zhang, Sheng Wang, Guohao Dai, Yu Wang
Training large-scale models relies on a vast number of computing resources. For example, training the GPT-4 model (1.8 trillion parameters) requires 25000 A100 GPUs . It is a challenge to build a large-scale cluster with one type of GPU-accelerator. Using multiple types of GPU-accelerators to construct a large-scale cluster is an effective way to solve the problem of insufficient homogeneous GPU-accelerators. However, the existing distributed training systems for large-scale models only support homogeneous GPU-accelerators, not support heterogeneous GPU-accelerators. To address the problem, this paper proposes a distributed training system with hybrid parallelism, HETHUB, for large-scale models, which supports heterogeneous cluster, including AMD, Nvidia GPU and other types of GPU-accelerators . It introduces a distributed unified communicator to realize the communication between heterogeneous GPU-accelerators, a distributed performance predictor, and an automatic parallel planner to develop and train models efficiently with heterogeneous GPU-accelerators. Compared to the distributed training system with homogeneous GPU-accelerators, our system can support six combinations of heterogeneous GPU-accelerators. We train the Llama-140B model on a heterogeneous cluster with 768 GPU-accelerators(128 AMD and 640 GPU-accelerator A). The experiment results show that the optimal performance of our system in the heterogeneous cluster has achieved up to 97.49% of the theoretical upper bound performance.
Read more8/12/2024
0
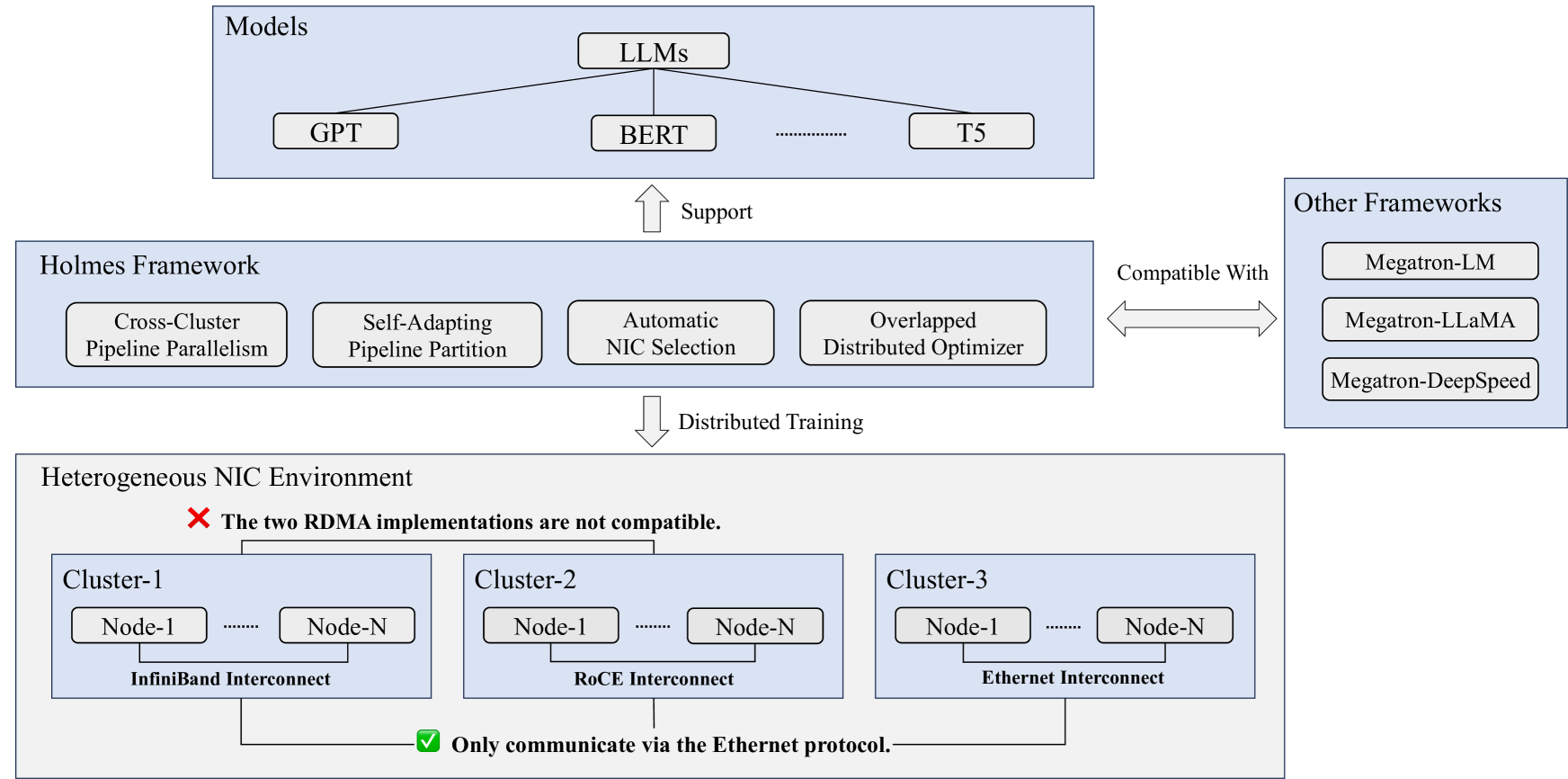
Holmes: Towards Distributed Training Across Clusters with Heterogeneous NIC Environment
Fei Yang, Shuang Peng, Ning Sun, Fangyu Wang, Yuanyuan Wang, Fu Wu, Jiezhong Qiu, Aimin Pan
Large language models (LLMs) such as GPT-3, OPT, and LLaMA have demonstrated remarkable accuracy in a wide range of tasks. However, training these models can incur significant expenses, often requiring tens of thousands of GPUs for months of continuous operation. Typically, this training is carried out in specialized GPU clusters equipped with homogeneous high-speed Remote Direct Memory Access (RDMA) network interface cards (NICs). The acquisition and maintenance of such dedicated clusters is challenging. Current LLM training frameworks, like Megatron-LM and Megatron-DeepSpeed, focus primarily on optimizing training within homogeneous cluster settings. In this paper, we introduce Holmes, a training framework for LLMs that employs thoughtfully crafted data and model parallelism strategies over the heterogeneous NIC environment. Our primary technical contribution lies in a novel scheduling method that intelligently allocates distinct computational tasklets in LLM training to specific groups of GPU devices based on the characteristics of their connected NICs. Furthermore, our proposed framework, utilizing pipeline parallel techniques, demonstrates scalability to multiple GPU clusters, even in scenarios without high-speed interconnects between nodes in distinct clusters. We conducted comprehensive experiments that involved various scenarios in the heterogeneous NIC environment. In most cases, our framework achieves performance levels close to those achievable with homogeneous RDMA-capable networks (InfiniBand or RoCE), significantly exceeding training efficiency within the pure Ethernet environment. Additionally, we verified that our framework outperforms other mainstream LLM frameworks under heterogeneous NIC environment in terms of training efficiency and can be seamlessly integrated with them.
Read more4/30/2024
🔍
0
A 4D Hybrid Algorithm to Scale Parallel Training to Thousands of GPUs
Siddharth Singh, Prajwal Singhania, Aditya K. Ranjan, Zack Sating, Abhinav Bhatele
Heavy communication, in particular, collective operations, can become a critical performance bottleneck in scaling the training of billion-parameter neural networks to large-scale parallel systems. This paper introduces a four-dimensional (4D) approach to optimize communication in parallel training. This 4D approach is a hybrid of 3D tensor and data parallelism, and is implemented in the AxoNN framework. In addition, we employ two key strategies to further minimize communication overheads. First, we aggressively overlap expensive collective operations (reduce-scatter, all-gather, and all-reduce) with computation. Second, we develop an analytical model to identify high-performing configurations within the large search space defined by our 4D algorithm. This model empowers practitioners by simplifying the tuning process for their specific training workloads. When training an 80-billion parameter GPT on 1024 GPUs of Perlmutter, AxoNN surpasses Megatron-LM, a state-of-the-art framework, by a significant 26%. Additionally, it achieves a significantly high 57% of the theoretical peak FLOP/s or 182 PFLOP/s in total.
Read more5/15/2024

0
Efficient Training of Large Language Models on Distributed Infrastructures: A Survey
Jiangfei Duan, Shuo Zhang, Zerui Wang, Lijuan Jiang, Wenwen Qu, Qinghao Hu, Guoteng Wang, Qizhen Weng, Hang Yan, Xingcheng Zhang, Xipeng Qiu, Dahua Lin, Yonggang Wen, Xin Jin, Tianwei Zhang, Peng Sun
Large Language Models (LLMs) like GPT and LLaMA are revolutionizing the AI industry with their sophisticated capabilities. Training these models requires vast GPU clusters and significant computing time, posing major challenges in terms of scalability, efficiency, and reliability. This survey explores recent advancements in training systems for LLMs, including innovations in training infrastructure with AI accelerators, networking, storage, and scheduling. Additionally, the survey covers parallelism strategies, as well as optimizations for computation, communication, and memory in distributed LLM training. It also includes approaches of maintaining system reliability over extended training periods. By examining current innovations and future directions, this survey aims to provide valuable insights towards improving LLM training systems and tackling ongoing challenges. Furthermore, traditional digital circuit-based computing systems face significant constraints in meeting the computational demands of LLMs, highlighting the need for innovative solutions such as optical computing and optical networks.
Read more7/30/2024