Hey..! This medicine made me sick: Sentiment Analysis of User-Generated Drug Reviews using Machine Learning Techniques
2404.13057
0
0
Abstract
Sentiment analysis has become increasingly important in healthcare, especially in the biomedical and pharmaceutical fields. The data generated by the general public on the effectiveness, side effects, and adverse drug reactions are goldmines for different agencies and medicine producers to understand the concerns and reactions of people. Despite the challenge of obtaining datasets on drug-related problems, sentiment analysis on this topic would be a significant boon to the field. This project proposes a drug review classification system that classifies user reviews on a particular drug into different classes, such as positive, negative, and neutral. This approach uses a dataset that is collected from publicly available sources containing drug reviews, such as drugs.com. The collected data is manually labeled and verified manually to ensure that the labels are correct. Three pre-trained language models, such as BERT, SciBERT, and BioBERT, are used to obtain embeddings, which were later used as features to different machine learning classifiers such as decision trees, support vector machines, random forests, and also deep learning algorithms such as recurrent neural networks. The performance of these classifiers is quantified using precision, recall, and f1-score, and the results show that the proposed approaches are useful in analyzing the sentiments of people on different drugs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper explores the use of machine learning techniques for sentiment analysis of user-generated drug reviews.
- The researchers aim to develop a model that can accurately classify the sentiment (positive, negative, or neutral) of user reviews about medications.
- The study utilizes a dataset of real-world drug reviews collected from online platforms and applies various machine learning algorithms to perform sentiment analysis.
Plain English Explanation
The researchers in this study were interested in understanding how people feel about the medications they take. They collected a large number of reviews that people had written about different drugs online. These reviews often express how the drug made the person feel, whether it was effective, or if they experienced any side effects.
The researchers used machine learning techniques to analyze the sentiment, or the overall feeling, expressed in these reviews. They wanted to create a model that could automatically categorize the reviews as positive, negative, or neutral. This could be useful for healthcare providers, drug companies, and patients to better understand the real-world experiences and perceptions of different medications.
By applying various machine learning algorithms to the dataset of drug reviews, the researchers aimed to develop an accurate and reliable sentiment analysis system. This could provide valuable insights into how people feel about the medications they use, which could inform decision-making and improve patient outcomes.
Technical Explanation
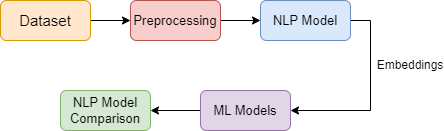
The researchers collected a dataset of user-generated drug reviews from online platforms. They preprocessed the data by cleaning and tokenizing the text. They then applied several supervised machine learning algorithms, including Naive Bayes, Random Forest, and Support Vector Machines (SVMs), to classify the sentiment of the reviews as positive, negative, or neutral.
The performance of the models was evaluated using metrics such as accuracy, precision, recall, and F1-score. The researchers also explored the use of BERT, a popular deep learning-based language model, for sentiment analysis on the drug review data.
The results of the study indicate that the machine learning models were able to achieve high accuracy in classifying the sentiment of the user-generated drug reviews. The researchers found that the Random Forest and SVM models outperformed the Naive Bayes classifier, demonstrating the potential of more advanced machine learning techniques for this task.
Critical Analysis
The paper acknowledges several limitations of the study, including the potential for bias in the user-generated review data and the need for further validation of the models on larger and more diverse datasets. The researchers also note that the interpretation of sentiment in drug reviews can be complex, as users may express mixed or nuanced emotions that are not easily categorized into binary positive or negative sentiments.
Additionally, the study does not explore the potential ethical implications of using sentiment analysis on medical-related data, such as concerns around privacy, data privacy, and the potential misuse of the technology. Further research is needed to address these important considerations.
Overall, the study demonstrates the feasibility of using machine learning for sentiment analysis of user-generated drug reviews, but additional work is required to fully understand the practical applications and limitations of this approach in real-world healthcare settings.
Conclusion
This research paper presents a promising approach for leveraging machine learning techniques to analyze the sentiment expressed in user-generated drug reviews. By developing accurate sentiment classification models, the researchers aim to provide valuable insights that can inform decision-making and improve patient outcomes in the healthcare domain.
The study's findings suggest that advanced machine learning algorithms, such as Random Forest and Support Vector Machines, can effectively capture the nuanced sentiments expressed in online drug reviews. However, the researchers acknowledge the need for further validation and consideration of ethical implications, highlighting the importance of responsible development and deployment of such sentiment analysis systems.
As the volume of user-generated healthcare data continues to grow, the ability to extract meaningful insights from this information through techniques like sentiment analysis will become increasingly valuable. This research contributes to the ongoing efforts to harness the power of machine learning for enhancing our understanding of patient experiences and perceptions in the medical field.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
A Sentiment Analysis of Medical Text Based on Deep Learning
Yinan Chen
0
0
The field of natural language processing (NLP) has made significant progress with the rapid development of deep learning technologies. One of the research directions in text sentiment analysis is sentiment analysis of medical texts, which holds great potential for application in clinical diagnosis. However, the medical field currently lacks sufficient text datasets, and the effectiveness of sentiment analysis is greatly impacted by different model design approaches, which presents challenges. Therefore, this paper focuses on the medical domain, using bidirectional encoder representations from transformers (BERT) as the basic pre-trained model and experimenting with modules such as convolutional neural network (CNN), fully connected network (FCN), and graph convolutional networks (GCN) at the output layer. Experiments and analyses were conducted on the METS-CoV dataset to explore the training performance after integrating different deep learning networks. The results indicate that CNN models outperform other networks when trained on smaller medical text datasets in combination with pre-trained models like BERT. This study highlights the significance of model selection in achieving effective sentiment analysis in the medical domain and provides a reference for future research to develop more efficient model architectures.
4/17/2024
📈
Finding fake reviews in e-commerce platforms by using hybrid algorithms
Mathivanan Periasamy, Rohith Mahadevan, Bagiya Lakshmi S, Raja CSP Raman, Hasan Kumar S, Jasper Jessiman
0
0
Sentiment analysis, a vital component in natural language processing, plays a crucial role in understanding the underlying emotions and opinions expressed in textual data. In this paper, we propose an innovative ensemble approach for sentiment analysis for finding fake reviews that amalgamate the predictive capabilities of Support Vector Machine (SVM), K-Nearest Neighbors (KNN), and Decision Tree classifiers. Our ensemble architecture strategically combines these diverse models to capitalize on their strengths while mitigating inherent weaknesses, thereby achieving superior accuracy and robustness in fake review prediction. By combining all the models of our classifiers, the predictive performance is boosted and it also fosters adaptability to varied linguistic patterns and nuances present in real-world datasets. The metrics accounted for on fake reviews demonstrate the efficacy and competitiveness of the proposed ensemble method against traditional single-model approaches. Our findings underscore the potential of ensemble techniques in advancing the state-of-the-art in finding fake reviews using hybrid algorithms, with implications for various applications in different social media and e-platforms to find the best reviews and neglect the fake ones, eliminating puffery and bluffs.
4/10/2024
🤔
Understanding Social Perception, Interactions, and Safety Aspects of Sidewalk Delivery Robots Using Sentiment Analysis
Yuchen Du, Tho V. Le
0
0
This article presents a comprehensive sentiment analysis (SA) of comments on YouTube videos related to Sidewalk Delivery Robots (SDRs). We manually annotated the collected YouTube comments with three sentiment labels: negative (0), positive (1), and neutral (2). We then constructed models for text sentiment classification and tested the models' performance on both binary and ternary classification tasks in terms of accuracy, precision, recall, and F1 score. Our results indicate that, in binary classification tasks, the Support Vector Machine (SVM) model using Term Frequency-Inverse Document Frequency (TF-IDF) and N-gram get the highest accuracy. In ternary classification tasks, the model using Bidirectional Encoder Representations from Transformers (BERT), Long Short-Term Memory Networks (LSTM) and Gated Recurrent Unit (GRU) significantly outperforms other machine learning models, achieving an accuracy, precision, recall, and F1 score of 0.78. Additionally, we employ the Latent Dirichlet Allocation model to generate 10 topics from the comments to explore the public's underlying views on SDRs. Drawing from these findings, we propose targeted recommendations for shaping future policies concerning SDRs. This work provides valuable insights for stakeholders in the SDR sector regarding social perception, interaction, and safety.
5/3/2024
🌿
It's Difficult to be Neutral -- Human and LLM-based Sentiment Annotation of Patient Comments
Petter M{ae}hlum, David Samuel, Rebecka Maria Norman, Elma Jelin, {O}yvind Andresen Bjertn{ae}s, Lilja {O}vrelid, Erik Velldal
0
0
Sentiment analysis is an important tool for aggregating patient voices, in order to provide targeted improvements in healthcare services. A prerequisite for this is the availability of in-domain data annotated for sentiment. This article documents an effort to add sentiment annotations to free-text comments in patient surveys collected by the Norwegian Institute of Public Health (NIPH). However, annotation can be a time-consuming and resource-intensive process, particularly when it requires domain expertise. We therefore also evaluate a possible alternative to human annotation, using large language models (LLMs) as annotators. We perform an extensive evaluation of the approach for two openly available pretrained LLMs for Norwegian, experimenting with different configurations of prompts and in-context learning, comparing their performance to human annotators. We find that even for zero-shot runs, models perform well above the baseline for binary sentiment, but still cannot compete with human annotators on the full dataset.
4/30/2024