Finding fake reviews in e-commerce platforms by using hybrid algorithms
2404.06339
0
0
📈
Abstract
Sentiment analysis, a vital component in natural language processing, plays a crucial role in understanding the underlying emotions and opinions expressed in textual data. In this paper, we propose an innovative ensemble approach for sentiment analysis for finding fake reviews that amalgamate the predictive capabilities of Support Vector Machine (SVM), K-Nearest Neighbors (KNN), and Decision Tree classifiers. Our ensemble architecture strategically combines these diverse models to capitalize on their strengths while mitigating inherent weaknesses, thereby achieving superior accuracy and robustness in fake review prediction. By combining all the models of our classifiers, the predictive performance is boosted and it also fosters adaptability to varied linguistic patterns and nuances present in real-world datasets. The metrics accounted for on fake reviews demonstrate the efficacy and competitiveness of the proposed ensemble method against traditional single-model approaches. Our findings underscore the potential of ensemble techniques in advancing the state-of-the-art in finding fake reviews using hybrid algorithms, with implications for various applications in different social media and e-platforms to find the best reviews and neglect the fake ones, eliminating puffery and bluffs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes an ensemble approach for sentiment analysis to detect fake reviews.
- The ensemble combines the strengths of Support Vector Machine (SVM), K-Nearest Neighbors (KNN), and Decision Tree classifiers.
- The goal is to achieve superior accuracy and robustness in predicting fake reviews by leveraging the complementary capabilities of these diverse models.
Plain English Explanation
The paper focuses on sentiment analysis, which is the process of understanding the emotions and opinions expressed in text. The researchers developed a new approach that combines multiple machine learning models to detect fake reviews more accurately.
Fake reviews can be a problem on e-commerce and social media platforms, as they can mislead consumers and distort the true sentiment of a product or service. To address this, the researchers used a combination of three well-known machine learning algorithms: Support Vector Machines (SVM), K-Nearest Neighbors (KNN), and Decision Trees.
By combining these different models, the researchers were able to take advantage of the unique strengths of each one. This "ensemble" approach allowed them to create a more robust and accurate system for identifying fake reviews, even in the face of complex language patterns and nuances in real-world data.
The key benefit of this approach is that it outperforms traditional single-model methods in terms of accuracy and adaptability. This has important implications for various applications, such as helping e-commerce platforms and social media sites to distinguish genuine reviews from fake ones, ultimately providing consumers with more trustworthy information.
Technical Explanation
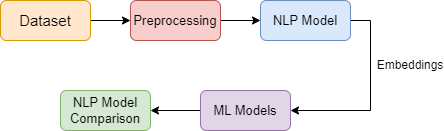
The researchers propose an ensemble approach that combines the predictive capabilities of three machine learning classifiers: Support Vector Machine (SVM), K-Nearest Neighbors (KNN), and Decision Tree. By strategically integrating these diverse models, the ensemble architecture aims to capitalize on their respective strengths while mitigating their inherent weaknesses, resulting in superior accuracy and robustness in fake review prediction.
The ensemble method works by aggregating the outputs of the individual classifiers to make the final prediction. This allows the system to leverage the unique strengths of each model and adapt to the varied linguistic patterns and nuances present in real-world datasets, such as those found in social media and e-commerce platforms.
The researchers evaluated the performance of the ensemble approach on fake review datasets and found that it outperformed traditional single-model approaches. The metrics reported in the paper demonstrate the efficacy and competitiveness of the proposed method, highlighting its potential for advancing the state-of-the-art in fake review detection.
Critical Analysis
The paper provides a robust evaluation of the ensemble approach and demonstrates its effectiveness in detecting fake reviews. However, the researchers acknowledge that their method may be limited in its ability to handle highly sophisticated or adversarial attacks on the sentiment analysis system.
Additionally, the paper does not explore the interpretability of the ensemble model, which could be an important consideration for real-world applications where transparency and explainability are crucial. Further research could investigate ways to enhance the interpretability of the ensemble approach without compromising its performance.
Another potential limitation is the reliance on traditional machine learning algorithms, which may not fully capture the complexity of human language and sentiment. Future work could explore the integration of more advanced techniques, such as deep learning models, to further improve the accuracy and robustness of the fake review detection system.
Conclusion
This paper presents an innovative ensemble approach for sentiment analysis that combines the predictive capabilities of SVM, KNN, and Decision Tree classifiers to detect fake reviews. The researchers demonstrate the efficacy of their method, which outperforms traditional single-model approaches in terms of accuracy and adaptability to varied linguistic patterns.
The proposed ensemble technique has significant implications for various applications, particularly in e-commerce and social media platforms, where distinguishing genuine reviews from fake ones is crucial for providing consumers with trustworthy information. The findings of this research underscore the potential of ensemble methods in advancing the state-of-the-art in sentiment analysis and fake review detection.
Related Papers
✨
Efficient Sentiment Analysis: A Resource-Aware Evaluation of Feature Extraction Techniques, Ensembling, and Deep Learning Models
Mahammed Kamruzzaman, Gene Louis Kim
0
0
While reaching for NLP systems that maximize accuracy, other important metrics of system performance are often overlooked. Prior models are easily forgotten despite their possible suitability in settings where large computing resources are unavailable or relatively more costly. In this paper, we perform a broad comparative evaluation of document-level sentiment analysis models with a focus on resource costs that are important for the feasibility of model deployment and general climate consciousness. Our experiments consider different feature extraction techniques, the effect of ensembling, task-specific deep learning modeling, and domain-independent large language models (LLMs). We find that while a fine-tuned LLM achieves the best accuracy, some alternate configurations provide huge (up to 24, 283 *) resource savings for a marginal (<1%) loss in accuracy. Furthermore, we find that for smaller datasets, the differences in accuracy shrink while the difference in resource consumption grows further.
4/19/2024
Hey..! This medicine made me sick: Sentiment Analysis of User-Generated Drug Reviews using Machine Learning Techniques
Abhiram B. Nair, Abhinand K., Anamika U., Denil Tom Jaison, Ajitha V., V. S. Anoop
0
0
Sentiment analysis has become increasingly important in healthcare, especially in the biomedical and pharmaceutical fields. The data generated by the general public on the effectiveness, side effects, and adverse drug reactions are goldmines for different agencies and medicine producers to understand the concerns and reactions of people. Despite the challenge of obtaining datasets on drug-related problems, sentiment analysis on this topic would be a significant boon to the field. This project proposes a drug review classification system that classifies user reviews on a particular drug into different classes, such as positive, negative, and neutral. This approach uses a dataset that is collected from publicly available sources containing drug reviews, such as drugs.com. The collected data is manually labeled and verified manually to ensure that the labels are correct. Three pre-trained language models, such as BERT, SciBERT, and BioBERT, are used to obtain embeddings, which were later used as features to different machine learning classifiers such as decision trees, support vector machines, random forests, and also deep learning algorithms such as recurrent neural networks. The performance of these classifiers is quantified using precision, recall, and f1-score, and the results show that the proposed approaches are useful in analyzing the sentiments of people on different drugs.
4/23/2024
➖
RELIANCE: Reliable Ensemble Learning for Information and News Credibility Evaluation
Majid Ramezani, Hamed Mohammadshahi, Mahshid Daliry, Soroor Rahmani, Amir-Hosein Asghari
0
0
In the era of information proliferation, discerning the credibility of news content poses an ever-growing challenge. This paper introduces RELIANCE, a pioneering ensemble learning system designed for robust information and fake news credibility evaluation. Comprising five diverse base models, including Support Vector Machine (SVM), naive Bayes, logistic regression, random forest, and Bidirectional Long Short Term Memory Networks (BiLSTMs), RELIANCE employs an innovative approach to integrate their strengths, harnessing the collective intelligence of the ensemble for enhanced accuracy. Experiments demonstrate the superiority of RELIANCE over individual models, indicating its efficacy in distinguishing between credible and non-credible information sources. RELIANCE, also surpasses baseline models in information and news credibility assessment, establishing itself as an effective solution for evaluating the reliability of information sources.
4/23/2024
🔎
Bengali Fake Reviews: A Benchmark Dataset and Detection System
G. M. Shahariar, Md. Tanvir Rouf Shawon, Faisal Muhammad Shah, Mohammad Shafiul Alam, Md. Shahriar Mahbub
0
0
The proliferation of fake reviews on various online platforms has created a major concern for both consumers and businesses. Such reviews can deceive customers and cause damage to the reputation of products or services, making it crucial to identify them. Although the detection of fake reviews has been extensively studied in English language, detecting fake reviews in non-English languages such as Bengali is still a relatively unexplored research area. This paper introduces the Bengali Fake Review Detection (BFRD) dataset, the first publicly available dataset for identifying fake reviews in Bengali. The dataset consists of 7710 non-fake and 1339 fake food-related reviews collected from social media posts. To convert non-Bengali words in a review, a unique pipeline has been proposed that translates English words to their corresponding Bengali meaning and also back transliterates Romanized Bengali to Bengali. We have conducted rigorous experimentation using multiple deep learning and pre-trained transformer language models to develop a reliable detection system. Finally, we propose a weighted ensemble model that combines four pre-trained transformers: BanglaBERT, BanglaBERT Base, BanglaBERT Large, and BanglaBERT Generator . According to the experiment results, the proposed ensemble model obtained a weighted F1-score of 0.9843 on 13390 reviews, including 1339 actual fake reviews and 5356 augmented fake reviews generated with the nlpaug library. The remaining 6695 reviews were randomly selected from the 7710 non-fake instances. The model achieved a 0.9558 weighted F1-score when the fake reviews were augmented using the bnaug library.
5/7/2024