Intuitive Fine-Tuning: Towards Unifying SFT and RLHF into a Single Process
2405.11870
0
0
Abstract
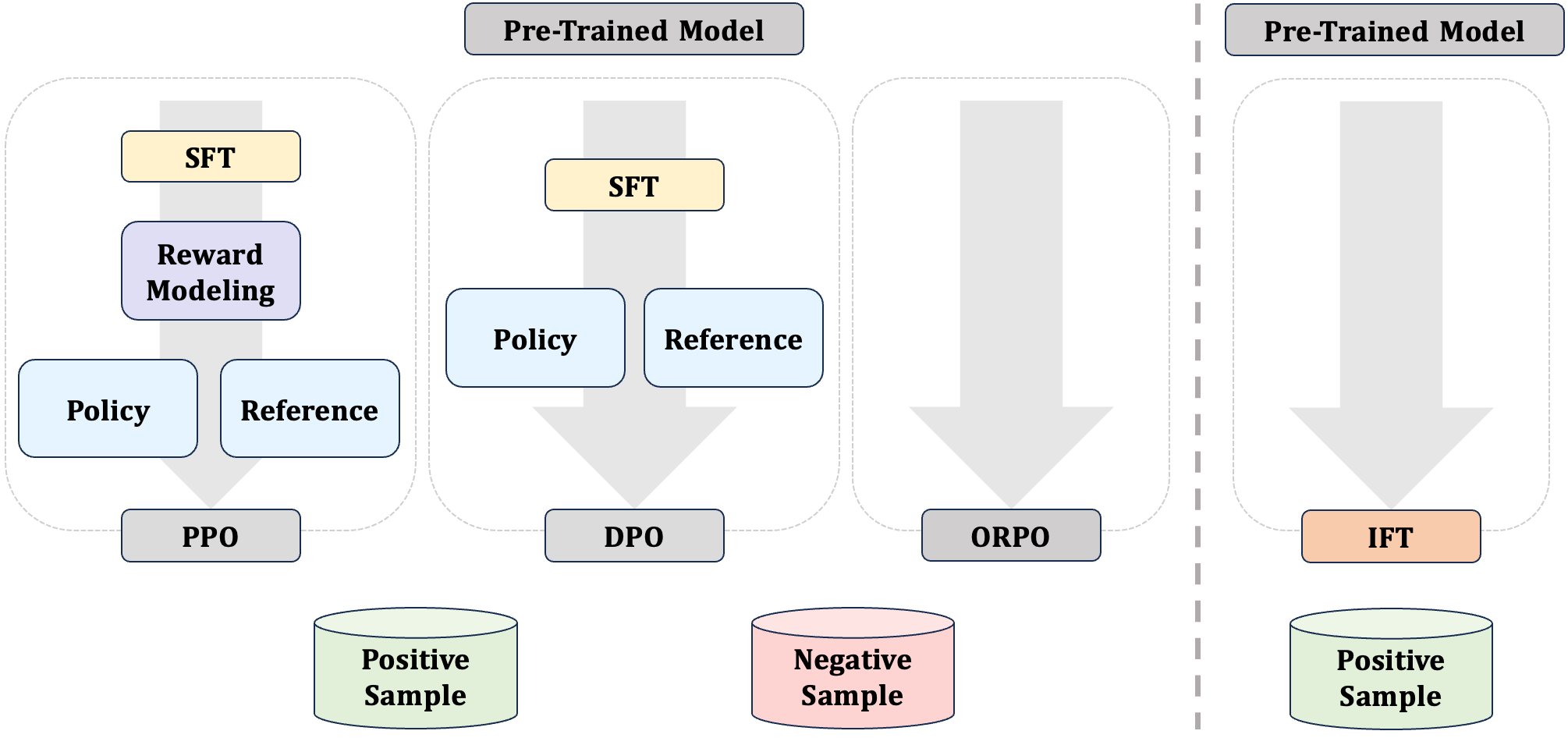
Supervised Fine-Tuning (SFT) and Preference Optimization (PO) are two fundamental processes for enhancing the capabilities of Language Models (LMs) post pre-training, aligning them better with human preferences. Although SFT advances in training efficiency, PO delivers better alignment, thus they are often combined. However, common practices simply apply them sequentially without integrating their optimization objectives, ignoring the opportunities to bridge their paradigm gap and take the strengths from both. To obtain a unified understanding, we interpret SFT and PO with two sub-processes -- Preference Estimation and Transition Optimization -- defined at token level within the Markov Decision Process (MDP) framework. This modeling shows that SFT is only a specialized case of PO with inferior estimation and optimization. PO evaluates the quality of model's entire generated answer, whereas SFT only scores predicted tokens based on preceding tokens from target answers. Therefore, SFT overestimates the ability of model, leading to inferior optimization. Building on this view, we introduce Intuitive Fine-Tuning (IFT) to integrate SFT and Preference Optimization into a single process. IFT captures LMs' intuitive sense of the entire answers through a temporal residual connection, but it solely relies on a single policy and the same volume of non-preference-labeled data as SFT. Our experiments show that IFT performs comparably or even superiorly to sequential recipes of SFT and some typical Preference Optimization methods across several tasks, particularly those requires generation, reasoning, and fact-following abilities. An explainable Frozen Lake game further validates the effectiveness of IFT for getting competitive policy.
Create account to get full access
Overview
- Presents a new approach called "Intuitive Fine-Tuning" that aims to unify two existing methods, Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), into a single process.
- Argues that this unified approach can provide benefits like improved performance, safety, and alignment with human values compared to using the methods separately.
- Introduces a novel training algorithm and discusses how it relates to and improves upon existing techniques.
Plain English Explanation
"Intuitive Fine-Tuning" is a new way of training AI systems that combines two existing methods - Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF). SFT involves directly teaching the AI system by showing it examples of desired behavior, while RLHF involves rewarding the AI when it does something good and punishing it when it does something bad.
The researchers behind this paper argue that by bringing these two methods together into a single process, they can create AI systems that are more capable, safer, and better aligned with human values. The key idea is that the AI can learn intuitively, in a way that feels natural to humans, rather than through a more rigid or mechanical training process.
The paper introduces a new training algorithm to implement this "Intuitive Fine-Tuning" approach. While the technical details can get quite complex, the core concept is about finding a more seamless and holistic way to train AI systems that combines the strengths of existing methods.
Technical Explanation
The paper proposes a new training approach called "Intuitive Fine-Tuning" that aims to unify Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) into a single process. The key idea is to create a more natural and intuitive learning experience for the AI system, drawing on the strengths of both SFT and RLHF.
The core training algorithm involves a novel combination of techniques. First, the AI is exposed to examples of desired behavior through SFT, similar to traditional fine-tuning approaches. However, the AI also receives feedback, both positive and negative, through RLHF-style reward signals. This allows the AI to learn not just what to do, but why certain actions are preferable.
The authors argue that this unified approach can lead to AI systems that are more capable, safer, and better aligned with human values compared to using SFT and RLHF separately. By blending these methods, the AI can learn in a more natural and intuitive way, drawing on both direct instruction and reward-based feedback.
The paper discusses how "Intuitive Fine-Tuning" relates to and builds upon existing techniques like HFT (Half Fine-Tuning) and Self-Refine. It also highlights potential benefits in terms of improving trust and impact compared to traditional fine-tuning approaches.
Critical Analysis
The paper presents a compelling vision for a more holistic and intuitive approach to training AI systems. By unifying SFT and RLHF, the researchers aim to create a learning process that is more natural and aligned with human values. This is an important goal, as AI systems become increasingly powerful and influential.
However, the paper does not provide a full implementation or empirical evaluation of the "Intuitive Fine-Tuning" approach. While the training algorithm is described in detail, the authors acknowledge that further research and experimentation are needed to fully validate the benefits of this unified method.
Additionally, the paper does not delve deeply into potential challenges or limitations of the proposed approach. For example, it's unclear how the method would scale to more complex AI systems or handle edge cases where the human feedback might be ambiguous or contradictory.
Further research is needed to explore these areas and provide a more comprehensive assessment of the "Intuitive Fine-Tuning" approach. Nonetheless, the core idea of blending SFT and RLHF in a more seamless and intuitive way is a valuable contribution to the ongoing efforts to develop AI systems that are safe, capable, and aligned with human values.
Conclusion
The "Intuitive Fine-Tuning" paper presents a novel approach to training AI systems that aims to unify Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF) into a single, more intuitive process. The researchers argue that this unified method can lead to AI systems that are more capable, safer, and better aligned with human values compared to using these techniques separately.
While the paper does not provide a full implementation or empirical evaluation, it offers a compelling vision for a more holistic and natural way of training AI. The core idea of blending direct instruction and reward-based feedback to create an intuitive learning experience is a valuable contribution to the ongoing efforts to develop AI systems that are truly beneficial to humanity.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Getting More Juice Out of the SFT Data: Reward Learning from Human Demonstration Improves SFT for LLM Alignment
Jiaxiang Li, Siliang Zeng, Hoi-To Wai, Chenliang Li, Alfredo Garcia, Mingyi Hong
0
0
Aligning human preference and value is an important requirement for contemporary foundation models. State-of-the-art techniques such as Reinforcement Learning from Human Feedback (RLHF) often consist of two stages: 1) supervised fine-tuning (SFT), where the model is fine-tuned by learning from human demonstration data; 2) Preference learning, where preference data is used to learn a reward model, which is in turn used by a reinforcement learning (RL) step to fine-tune the model. Such reward model serves as a proxy to human preference, and it is critical to guide the RL step towards improving the model quality. In this work, we argue that the SFT stage significantly benefits from learning a reward model as well. Instead of using the human demonstration data directly via supervised learning, we propose to leverage an Inverse Reinforcement Learning (IRL) technique to (explicitly or implicitly) build an reward model, while learning the policy model. This approach leads to new SFT algorithms that are not only efficient to implement, but also promote the ability to distinguish between the preferred and non-preferred continuations. Moreover, we identify a connection between the proposed IRL based approach, and certain self-play approach proposed recently, and showed that self-play is a special case of modeling a reward-learning agent. Theoretically, we show that the proposed algorithms converge to the stationary solutions of the IRL problem. Empirically, we align 1B and 7B models using proposed methods and evaluate them on a reward benchmark model and the HuggingFace Open LLM Leaderboard. The proposed methods show significant performance improvement over existing SFT approaches. Our results indicate that it is beneficial to explicitly or implicitly leverage reward learning throughout the entire alignment process.
5/30/2024
👨🏫
Unlock the Correlation between Supervised Fine-Tuning and Reinforcement Learning in Training Code Large Language Models
Jie Chen, Xintian Han, Yu Ma, Xun Zhou, Liang Xiang
0
0
Automatic code generation has been a longstanding research topic. With the advancement of general-purpose large language models (LLMs), the ability to code stands out as one important measure to the model's reasoning performance. Usually, a two-stage training paradigm is implemented to obtain a Code LLM, namely the pretraining and the fine-tuning. Within the fine-tuning, supervised fine-tuning (SFT), and reinforcement learning (RL) are often used to improve the model's zero-shot ability. A large number of work has been conducted to improve the model's performance on code-related benchmarks with either modifications to the algorithm or refinement of the dataset. However, we still lack a deep insight into the correlation between SFT and RL. For instance, what kind of dataset should be used to ensure generalization, or what if we abandon the SFT phase in fine-tuning. In this work, we make an attempt to understand the correlation between SFT and RL. To facilitate our research, we manually craft 100 basis python functions, called atomic functions, and then a synthesizing pipeline is deployed to create a large number of synthetic functions on top of the atomic ones. In this manner, we ensure that the train and test sets remain distinct, preventing data contamination. Through comprehensive ablation study, we find: (1) Both atomic and synthetic functions are indispensable for SFT's generalization, and only a handful of synthetic functions are adequate; (2) Through RL, the SFT's generalization to target domain can be greatly enhanced, even with the same training prompts; (3) Training RL from scratch can alleviate the over-fitting issue introduced in the SFT phase.
6/18/2024
Self-Evolution Fine-Tuning for Policy Optimization
Ruijun Chen, Jiehao Liang, Shiping Gao, Fanqi Wan, Xiaojun Quan
0
0
The alignment of large language models (LLMs) is crucial not only for unlocking their potential in specific tasks but also for ensuring that responses meet human expectations and adhere to safety and ethical principles. Current alignment methodologies face considerable challenges. For instance, supervised fine-tuning (SFT) requires extensive, high-quality annotated samples, while reinforcement learning from human feedback (RLHF) is complex and often unstable. In this paper, we introduce self-evolution fine-tuning (SEFT) for policy optimization, with the aim of eliminating the need for annotated samples while retaining the stability and efficiency of SFT. SEFT first trains an adaptive reviser to elevate low-quality responses while maintaining high-quality ones. The reviser then gradually guides the policy's optimization by fine-tuning it with enhanced responses. One of the prominent features of this method is its ability to leverage unlimited amounts of unannotated data for policy optimization through supervised fine-tuning. Our experiments on AlpacaEval 2.0 and MT-Bench demonstrate the effectiveness of SEFT. We also provide a comprehensive analysis of its advantages over existing alignment techniques.
6/18/2024
🌀
New!ReFT: Reasoning with Reinforced Fine-Tuning
Trung Quoc Luong, Xinbo Zhang, Zhanming Jie, Peng Sun, Xiaoran Jin, Hang Li
0
0
One way to enhance the reasoning capability of Large Language Models (LLMs) is to conduct Supervised Fine-Tuning (SFT) using Chain-of-Thought (CoT) annotations. This approach does not show sufficiently strong generalization ability, however, because the training only relies on the given CoT data. In math problem-solving, for example, there is usually only one annotated reasoning path for each question in the training data. Intuitively, it would be better for the algorithm to learn from multiple annotated reasoning paths given a question. To address this issue, we propose a simple yet effective approach called Reinforced Fine-Tuning (ReFT) to enhance the generalizability of learning LLMs for reasoning, with math problem-solving as an example. ReFT first warmups the model with SFT, and then employs on-line reinforcement learning, specifically the PPO algorithm in this paper, to further fine-tune the model, where an abundance of reasoning paths are automatically sampled given the question and the rewards are naturally derived from the ground-truth answers. Extensive experiments on GSM8K, MathQA, and SVAMP datasets show that ReFT significantly outperforms SFT, and the performance can be potentially further boosted by combining inference-time strategies such as majority voting and re-ranking. Note that ReFT obtains the improvement by learning from the same training questions as SFT, without relying on extra or augmented training questions. This indicates a superior generalization ability for ReFT.
6/28/2024