HGRN2: Gated Linear RNNs with State Expansion
2404.07904
0
0
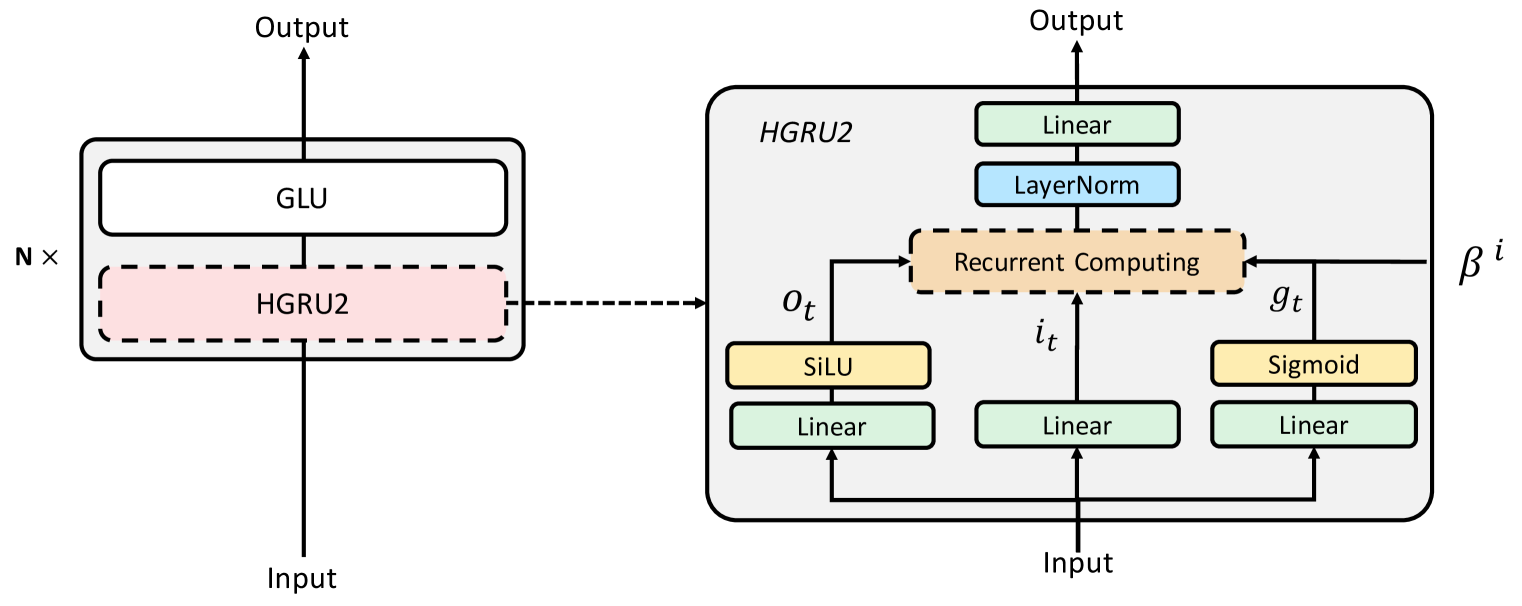
Abstract
Hierarchically gated linear RNN (HGRN,Qin et al. 2023) has demonstrated competitive training speed and performance in language modeling, while offering efficient inference. However, the recurrent state size of HGRN remains relatively small, which limits its expressiveness.To address this issue, inspired by linear attention, we introduce a simple outer-product-based state expansion mechanism so that the recurrent state size can be significantly enlarged without introducing any additional parameters. The linear attention form also allows for hardware-efficient training.Our extensive experiments verify the advantage of HGRN2 over HGRN1 in language modeling, image classification, and Long Range Arena.Our largest 3B HGRN2 model slightly outperforms Mamba and LLaMa Architecture Transformer for language modeling in a controlled experiment setting; and performs competitively with many open-source 3B models in downstream evaluation while using much fewer total training tokens.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper proposes a novel recurrent neural network architecture called "Gated Linear RNN with State Expansion" (HGRN2)
- The HGRN2 model aims to improve the efficiency and performance of regular language reasoning tasks compared to existing transformer-based and recurrent neural network models
- Key innovations include gating mechanisms and state expansion, which allow the model to better capture long-term dependencies while maintaining computational efficiency
Plain English Explanation
The researchers have developed a new type of recurrent neural network (RNN) called the "Gated Linear RNN with State Expansion" (HGRN2). RNNs are a class of machine learning models that are good at processing sequential data, like text or speech, by maintaining an internal state that gets updated over time.
The HGRN2 model builds on previous RNN architectures, but includes some important modifications. First, it uses "gating" mechanisms to selectively control the flow of information through the network. This helps the model focus on the most relevant parts of the input and maintain long-term memory. Second, it "expands" the internal state of the network by projecting it into a higher-dimensional space. This allows the model to represent more complex patterns in the data.
The key advantage of the HGRN2 model is that it can achieve strong performance on language-related tasks, like text understanding or generation, while being more computationally efficient than transformer-based models that are commonly used for these problems. This efficiency comes from the RNN's inherent sequential processing and the specific architectural choices in the HGRN2 design.
Technical Explanation
The paper introduces the "Gated Linear RNN with State Expansion" (HGRN2) model, which builds upon the gated linear RNN architecture. The key innovations in HGRN2 are the inclusion of gating mechanisms and state expansion.
The gating mechanism allows the model to selectively control the flow of information through the network. This is implemented using gates that determine how much of the current input and previous hidden state should be used to update the current hidden state. This helps the model focus on the most relevant parts of the input and maintain long-term memory.
The state expansion component projects the hidden state into a higher-dimensional space, allowing the model to represent more complex patterns in the data. This is done by learning a linear transformation matrix that maps the hidden state to the expanded state.
The authors evaluate the HGRN2 model on a range of language tasks, including language modeling, question answering, and text classification. They compare its performance to transformer-based models and other RNN architectures, such as the gated linear RNN. The results show that HGRN2 can achieve competitive or better performance while being more computationally efficient.
Critical Analysis
The paper provides a thorough evaluation of the HGRN2 model and its performance compared to other state-of-the-art approaches. The authors acknowledge some limitations of the work, such as the fact that the state expansion component adds computational overhead, which may limit the model's efficiency on certain hardware.
Additionally, the paper does not explore the interpretability of the HGRN2 model or how the gating and state expansion mechanisms contribute to its performance. Understanding the internal workings of neural networks is an important area of research, and further analysis in this direction could provide valuable insights.
Another potential area for future work is exploring the application of the HGRN2 architecture to graph-based reasoning tasks, which could leverage the model's ability to capture long-term dependencies and represent complex patterns.
Conclusion
The HGRN2 model proposed in this paper represents an interesting advancement in recurrent neural network architectures for language-related tasks. By incorporating gating mechanisms and state expansion, the model is able to achieve strong performance while remaining more computationally efficient than transformer-based approaches.
The paper provides a solid technical foundation and experimental evaluation of the HGRN2 model. While there are some areas for further research, the authors have made a valuable contribution to the field of efficient and effective neural networks for regular language reasoning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Advancing Regular Language Reasoning in Linear Recurrent Neural Networks
Ting-Han Fan, Ta-Chung Chi, Alexander I. Rudnicky
0
0
In recent studies, linear recurrent neural networks (LRNNs) have achieved Transformer-level performance in natural language and long-range modeling, while offering rapid parallel training and constant inference cost. With the resurgence of interest in LRNNs, we study whether they can learn the hidden rules in training sequences, such as the grammatical structures of regular language. We theoretically analyze some existing LRNNs and discover their limitations in modeling regular language. Motivated by this analysis, we propose a new LRNN equipped with a block-diagonal and input-dependent transition matrix. Experiments suggest that the proposed model is the only LRNN capable of performing length extrapolation on regular language tasks such as Sum, Even Pair, and Modular Arithmetic. The code is released at url{https://github.com/tinghanf/RegluarLRNN}.
4/10/2024
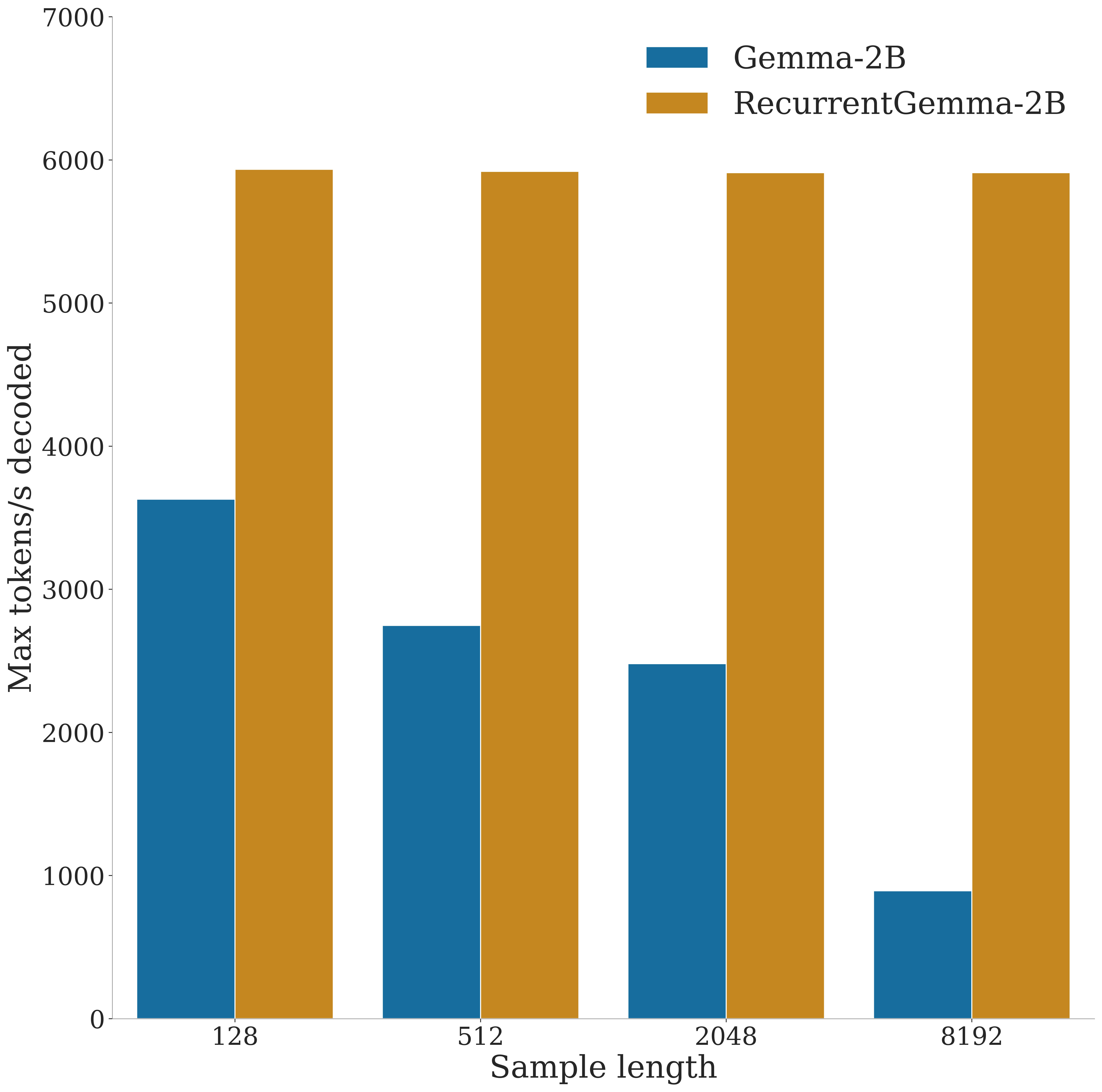
RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
Aleksandar Botev, Soham De, Samuel L Smith, Anushan Fernando, George-Cristian Muraru, Ruba Haroun, Leonard Berrada, Razvan Pascanu, Pier Giuseppe Sessa, Robert Dadashi, L'eonard Hussenot, Johan Ferret, Sertan Girgin, Olivier Bachem, Alek Andreev, Kathleen Kenealy, Thomas Mesnard, Cassidy Hardin, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivi`ere, Mihir Sanjay Kale, Juliette Love, Pouya Tafti, Armand Joulin, Noah Fiedel, Evan Senter, Yutian Chen, Srivatsan Srinivasan, Guillaume Desjardins, David Budden, Arnaud Doucet, Sharad Vikram, Adam Paszke, Trevor Gale, Sebastian Borgeaud, Charlie Chen, Andy Brock, Antonia Paterson, Jenny Brennan, Meg Risdal, Raj Gundluru, Nesh Devanathan, Paul Mooney, Nilay Chauhan, Phil Culliton, Luiz GUStavo Martins, Elisa Bandy, David Huntsperger, Glenn Cameron, Arthur Zucker, Tris Warkentin, Ludovic Peran, Minh Giang, Zoubin Ghahramani, Cl'ement Farabet, Koray Kavukcuoglu, Demis Hassabis, Raia Hadsell, Yee Whye Teh, Nando de Frietas
0
0
We introduce RecurrentGemma, an open language model which uses Google's novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
4/12/2024
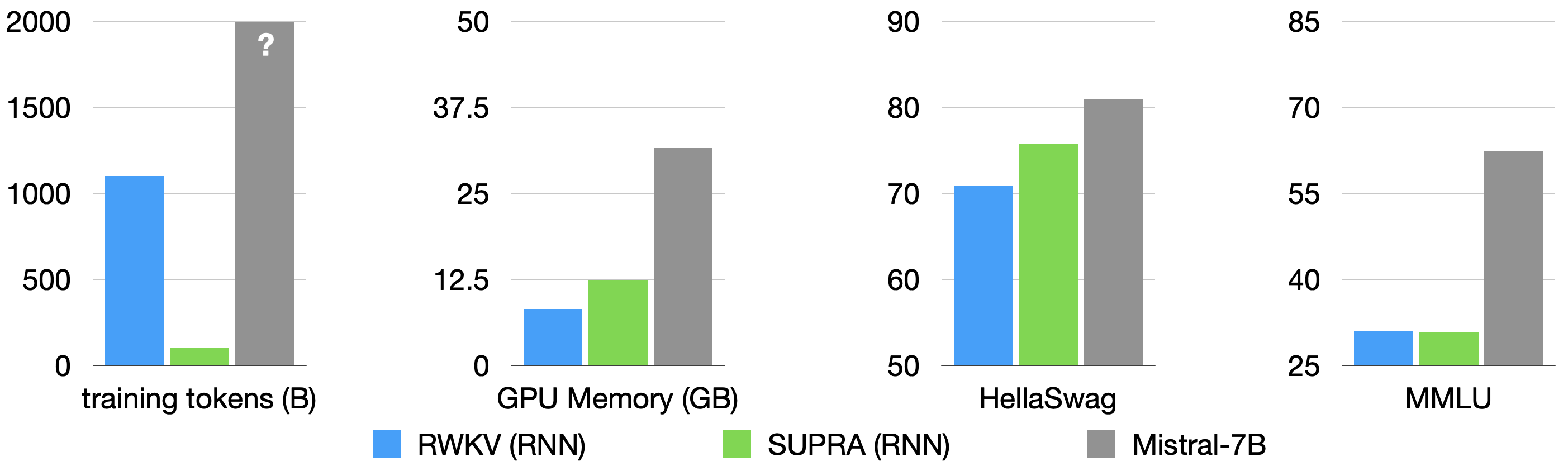
Linearizing Large Language Models
Jean Mercat, Igor Vasiljevic, Sedrick Keh, Kushal Arora, Achal Dave, Adrien Gaidon, Thomas Kollar
0
0
Linear transformers have emerged as a subquadratic-time alternative to softmax attention and have garnered significant interest due to their fixed-size recurrent state that lowers inference cost. However, their original formulation suffers from poor scaling and underperforms compute-matched transformers. Recent linear models such as RWKV and Mamba have attempted to address these shortcomings by proposing novel time-mixing and gating architectures, but pre-training large language models requires significant data and compute investments. Thus, the search for subquadratic architectures is limited by the availability of compute and quality pre-training datasets. As a cost-effective alternative to pre-training linear transformers, we propose Scalable UPtraining for Recurrent Attention (SUPRA). We present a method to uptrain existing large pre-trained transformers into Recurrent Neural Networks (RNNs) with a modest compute budget. This allows us to leverage the strong pre-training data and performance of existing transformer LLMs, while requiring 5% of the training cost. We find that our linearization technique leads to competitive performance on standard benchmarks, but we identify persistent in-context learning and long-context modeling shortfalls for even the largest linear models. Our code and models can be found at https://github.com/TRI-ML/linear_open_lm.
5/13/2024
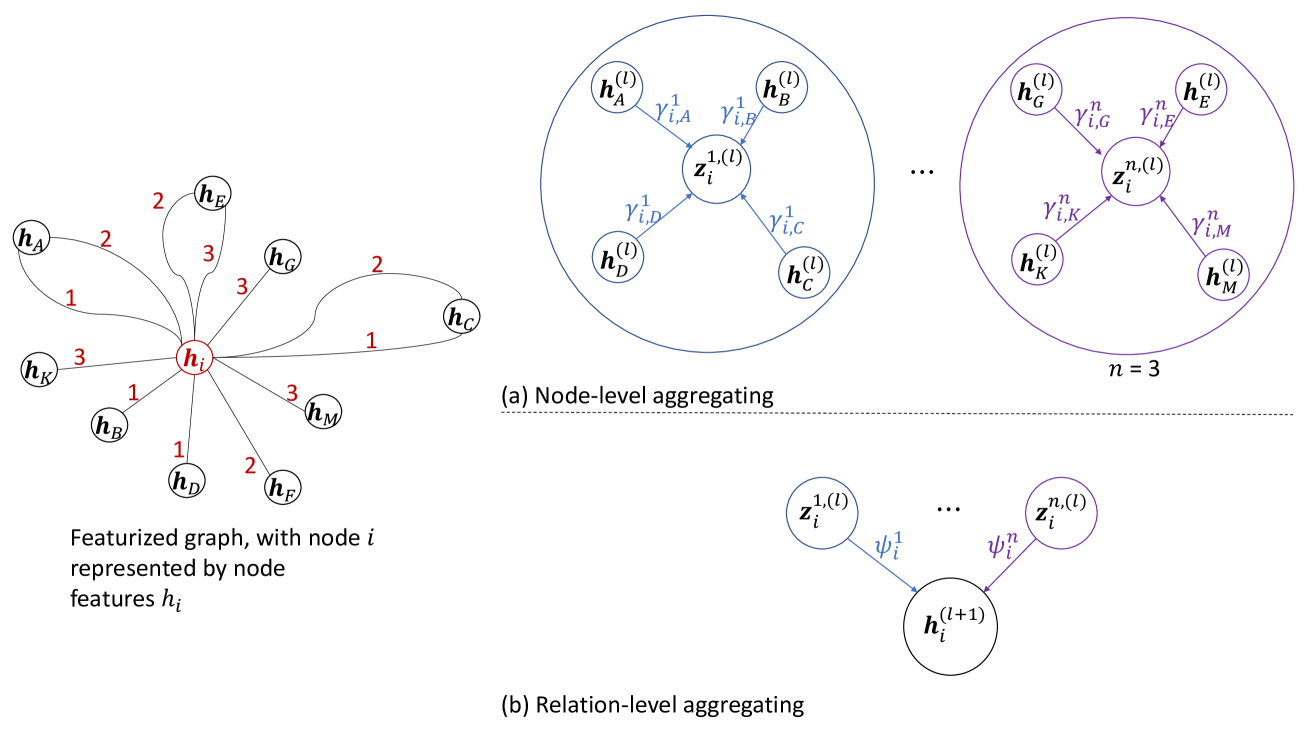
Hierarchical Attention Models for Multi-Relational Graphs
Roshni G. Iyer, Wei Wang, Yizhou Sun
0
0
We present Bi-Level Attention-Based Relational Graph Convolutional Networks (BR-GCN), unique neural network architectures that utilize masked self-attentional layers with relational graph convolutions, to effectively operate on highly multi-relational data. BR-GCN models use bi-level attention to learn node embeddings through (1) node-level attention, and (2) relation-level attention. The node-level self-attentional layers use intra-relational graph interactions to learn relation-specific node embeddings using a weighted aggregation of neighborhood features in a sparse subgraph region. The relation-level self-attentional layers use inter-relational graph interactions to learn the final node embeddings using a weighted aggregation of relation-specific node embeddings. The BR-GCN bi-level attention mechanism extends Transformer-based multiplicative attention from the natural language processing (NLP) domain, and Graph Attention Networks (GAT)-based attention, to large-scale heterogeneous graphs (HGs). On node classification, BR-GCN outperforms baselines from 0.29% to 14.95% as a stand-alone model, and on link prediction, BR-GCN outperforms baselines from 0.02% to 7.40% as an auto-encoder model. We also conduct ablation studies to evaluate the quality of BR-GCN's relation-level attention and discuss how its learning of graph structure may be transferred to enrich other graph neural networks (GNNs). Through various experiments, we show that BR-GCN's attention mechanism is both scalable and more effective in learning compared to state-of-the-art GNNs.
4/16/2024