Linearizing Large Language Models
2405.06640
1
0
Abstract
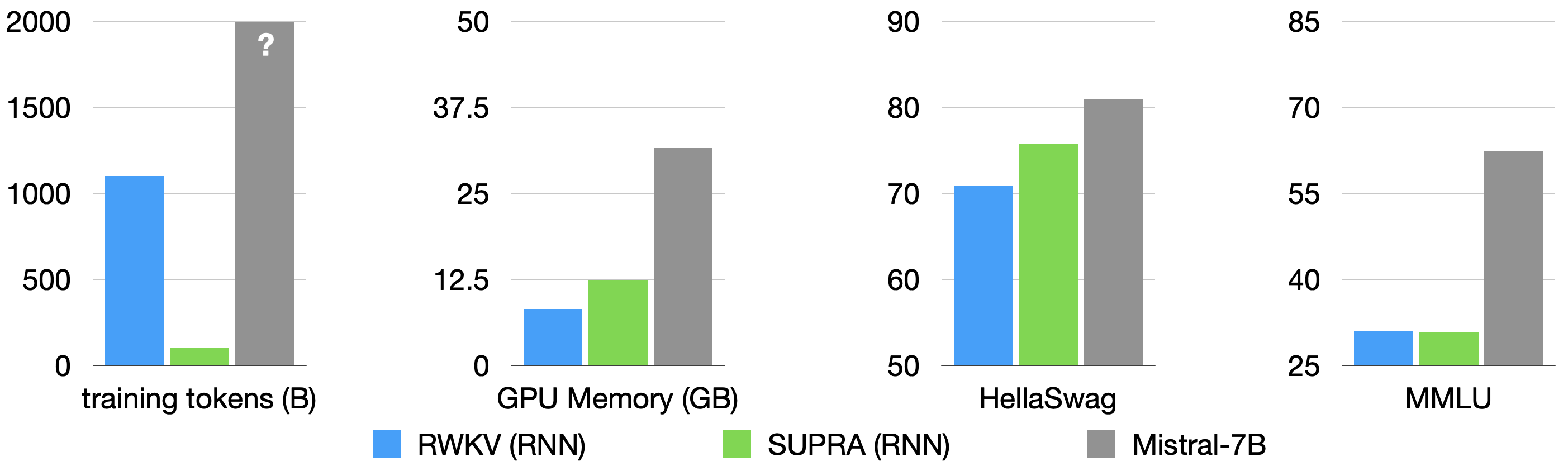
Linear transformers have emerged as a subquadratic-time alternative to softmax attention and have garnered significant interest due to their fixed-size recurrent state that lowers inference cost. However, their original formulation suffers from poor scaling and underperforms compute-matched transformers. Recent linear models such as RWKV and Mamba have attempted to address these shortcomings by proposing novel time-mixing and gating architectures, but pre-training large language models requires significant data and compute investments. Thus, the search for subquadratic architectures is limited by the availability of compute and quality pre-training datasets. As a cost-effective alternative to pre-training linear transformers, we propose Scalable UPtraining for Recurrent Attention (SUPRA). We present a method to uptrain existing large pre-trained transformers into Recurrent Neural Networks (RNNs) with a modest compute budget. This allows us to leverage the strong pre-training data and performance of existing transformer LLMs, while requiring 5% of the training cost. We find that our linearization technique leads to competitive performance on standard benchmarks, but we identify persistent in-context learning and long-context modeling shortfalls for even the largest linear models. Our code and models can be found at https://github.com/TRI-ML/linear_open_lm.
Create account to get full access
Overview
- This paper explores techniques for linearizing large language models, which can significantly reduce the computational cost of inference.
- The authors investigate the application of linear attention mechanisms, tensor decomposition, and other approaches to improve the efficiency of transformer-based models.
- The paper presents experimental results demonstrating the effectiveness of these techniques in reducing model size and inference time, while maintaining competitive performance on various language tasks.
Plain English Explanation
The paper discusses ways to make large language models, like those used in chatbots and text generation, more efficient and faster to use. These models can be very computationally intensive, requiring a lot of processing power and time to generate responses.
The researchers explore different techniques to "linearize" these models, which means finding ways to simplify the complex mathematical operations they perform. This could involve things like using a more efficient attention mechanism or decomposing the model's parameters into more compact representations.
By making these models more linear and efficient, the authors show they can significantly reduce the amount of computing power and time needed to run the models, while still maintaining good performance on language tasks. This could make it more practical to deploy these powerful AI models in real-world applications, like faster response times for chatbots or more efficient training of language models.
Technical Explanation
The paper explores several techniques to linearize large language models and improve their computational efficiency:
-
Linear Attention: The authors investigate the use of linear attention mechanisms, which can approximate the standard attention used in transformer models at a lower computational cost. This builds on prior work on linear-cost attention.
-
Tensor Decomposition: The researchers also explore tensor decomposition methods, such as tensor trains, to compactly represent the model parameters and reduce the overall model size.
-
Other Approaches: In addition, the paper examines other techniques like efficient large language model architectures and accelerated inference for long sequences.
The authors conduct extensive experiments to evaluate the effectiveness of these linearization techniques. They measure the impact on model size, inference time, and performance on various language tasks, demonstrating significant improvements in efficiency while maintaining competitive task-specific results.
Critical Analysis
The paper provides a comprehensive exploration of different approaches to linearizing large language models, which is an important area of research given the computational demands of these models. The authors thoroughly evaluate the techniques and present compelling experimental results.
However, the paper does not address some potential limitations or areas for further investigation. For example, it would be interesting to understand how well these linearization methods generalize to a broader range of language models and tasks, beyond the specific architectures and benchmarks used in the study.
Additionally, the paper does not delve into the potential trade-offs or side effects of these linearization techniques, such as any impact on model robustness, generalization, or interpretability. These are important considerations that could be explored in future research.
Overall, the paper makes a valuable contribution to the field of efficient large language model design, but there are opportunities for further research to address the limitations and explore the broader implications of these linearization approaches.
Conclusion
This paper presents several innovative techniques for linearizing large language models, which can significantly reduce the computational cost of inference without sacrificing model performance. The authors' work demonstrates the potential for improving the practical deployment of powerful language AI systems, enabling faster response times, more efficient training, and broader accessibility.
The findings in this paper are an important step forward in the ongoing effort to make large language models more efficient and scalable, paving the way for their wider adoption in real-world applications. As the field continues to evolve, further research on the trade-offs and broader implications of these linearization methods will be crucial to realize the full potential of these transformative AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
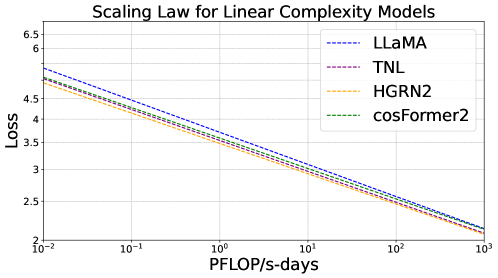
Scaling Laws for Linear Complexity Language Models
Xuyang Shen, Dong Li, Ruitao Leng, Zhen Qin, Weigao Sun, Yiran Zhong
0
0
The interest in linear complexity models for large language models is on the rise, although their scaling capacity remains uncertain. In this study, we present the scaling laws for linear complexity language models to establish a foundation for their scalability. Specifically, we examine the scaling behaviors of three efficient linear architectures. These include TNL, a linear attention model with data-independent decay; HGRN2, a linear RNN with data-dependent decay; and cosFormer2, a linear attention model without decay. We also include LLaMA as a baseline architecture for softmax attention for comparison. These models were trained with six variants, ranging from 70M to 7B parameters on a 300B-token corpus, and evaluated with a total of 1,376 intermediate checkpoints on various downstream tasks. These tasks include validation loss, commonsense reasoning, and information retrieval and generation. The study reveals that existing linear complexity language models exhibit similar scaling capabilities as conventional transformer-based models while also demonstrating superior linguistic proficiency and knowledge retention.
6/26/2024
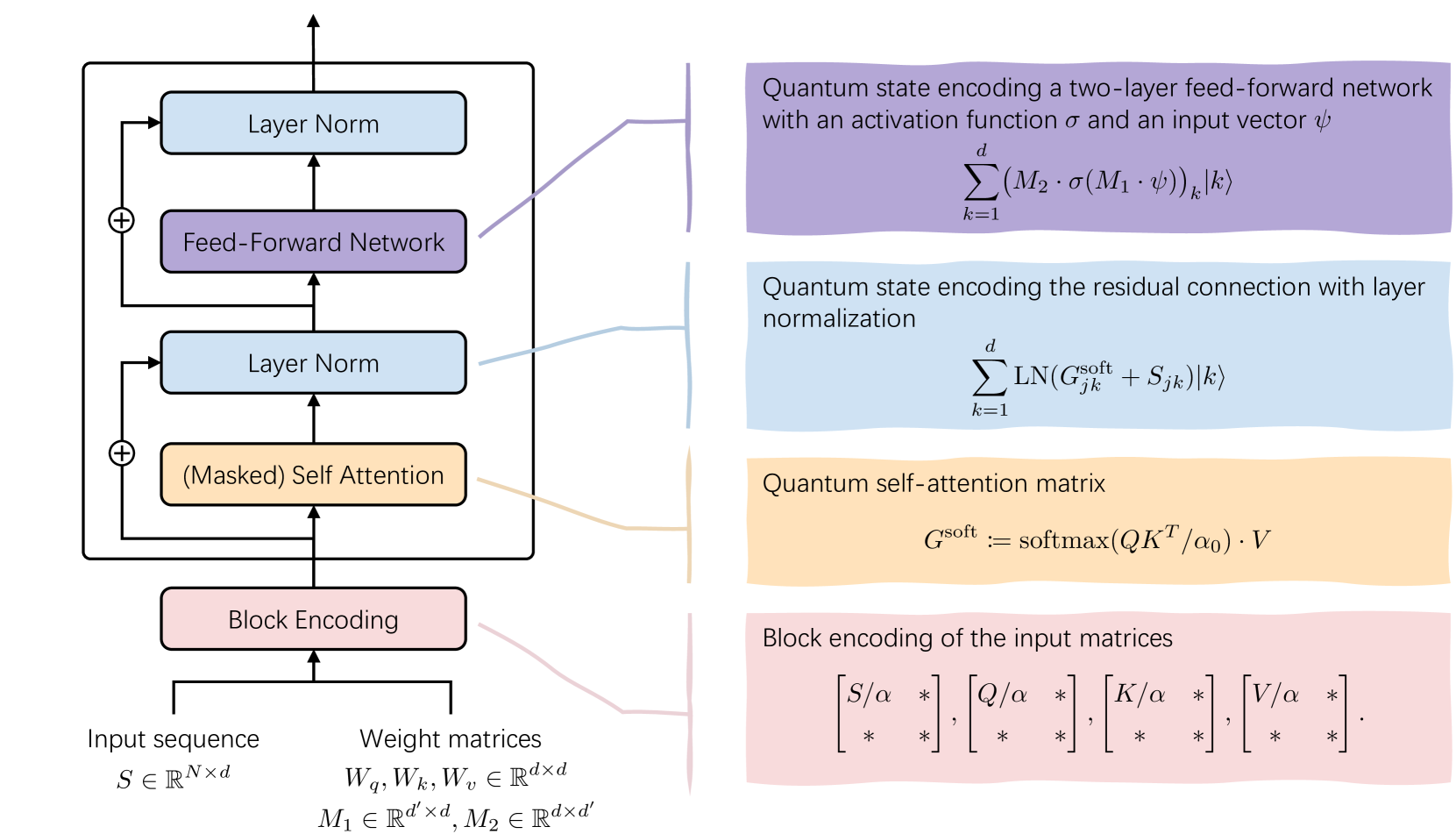
Quantum linear algebra is all you need for Transformer architectures
Naixu Guo, Zhan Yu, Matthew Choi, Aman Agrawal, Kouhei Nakaji, Al'an Aspuru-Guzik, Patrick Rebentrost
0
0
Generative machine learning methods such as large-language models are revolutionizing the creation of text and images. While these models are powerful they also harness a large amount of computational resources. The transformer is a key component in large language models that aims to generate a suitable completion of a given partial sequence. In this work, we investigate transformer architectures under the lens of fault-tolerant quantum computing. The input model is one where trained weight matrices are given as block encodings and we construct the query, key, and value matrices for the transformer. We show how to prepare a block encoding of the self-attention matrix, with a new subroutine for the row-wise application of the softmax function. In addition, we combine quantum subroutines to construct important building blocks in the transformer, the residual connection and layer normalization, and the feed-forward neural network. Our subroutines prepare an amplitude encoding of the transformer output, which can be measured to obtain a prediction. Based on common open-source large-language models, we provide insights into the behavior of important parameters determining the run time of the quantum algorithm. We discuss the potential and challenges for obtaining a quantum advantage.
6/3/2024

Small-E: Small Language Model with Linear Attention for Efficient Speech Synthesis
Th'eodor Lemerle, Nicolas Obin, Axel Roebel
0
0
Recent advancements in text-to-speech (TTS) powered by language models have showcased remarkable capabilities in achieving naturalness and zero-shot voice cloning. Notably, the decoder-only transformer is the prominent architecture in this domain. However, transformers face challenges stemming from their quadratic complexity in sequence length, impeding training on lengthy sequences and resource-constrained hardware. Moreover they lack specific inductive bias with regards to the monotonic nature of TTS alignments. In response, we propose to replace transformers with emerging recurrent architectures and introduce specialized cross-attention mechanisms for reducing repeating and skipping issues. Consequently our architecture can be efficiently trained on long samples and achieve state-of-the-art zero-shot voice cloning against baselines of comparable size. Our implementation and demos are available at https://github.com/theodorblackbird/lina-speech.
6/12/2024
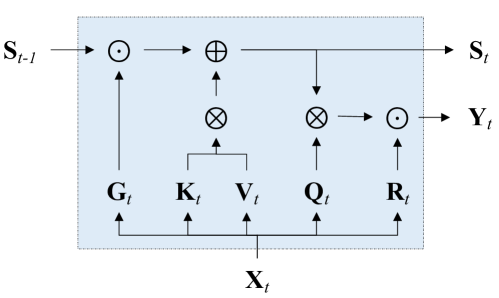
Gated Linear Attention Transformers with Hardware-Efficient Training
Songlin Yang, Bailin Wang, Yikang Shen, Rameswar Panda, Yoon Kim
0
0
Transformers with linear attention allow for efficient parallel training but can simultaneously be formulated as an RNN with 2D (matrix-valued) hidden states, thus enjoying linear-time inference complexity. However, linear attention generally underperforms ordinary softmax attention. Moreover, current implementations of linear attention lack I/O-awareness and are thus slower than highly optimized implementations of softmax attention. This work describes a hardware-efficient algorithm for linear attention that trades off memory movement against parallelizability. The resulting implementation, dubbed FLASHLINEARATTENTION, is faster than FLASHATTENTION-2 (Dao, 2023) as a standalone layer even on short sequence lengths (e.g., 1K). We then generalize this algorithm to a more expressive variant of linear attention with data-dependent gates. When used as a replacement for the standard attention layer in Transformers, the resulting gated linear attention (GLA) Transformer is found to perform competitively against the LLaMA-architecture Transformer (Touvron et al., 2023) as well recent linear-time-inference baselines such as RetNet (Sun et al., 2023a) and Mamba (Gu & Dao, 2023) on moderate-scale language modeling experiments. GLA Transformer is especially effective at length generalization, enabling a model trained on 2K to generalize to sequences longer than 20K without significant perplexity degradations. For training speed, the GLA Transformer has higher throughput than a similarly-sized Mamba model.
6/6/2024