RecurrentGemma: Moving Past Transformers for Efficient Open Language Models
2404.07839
0
18
Abstract
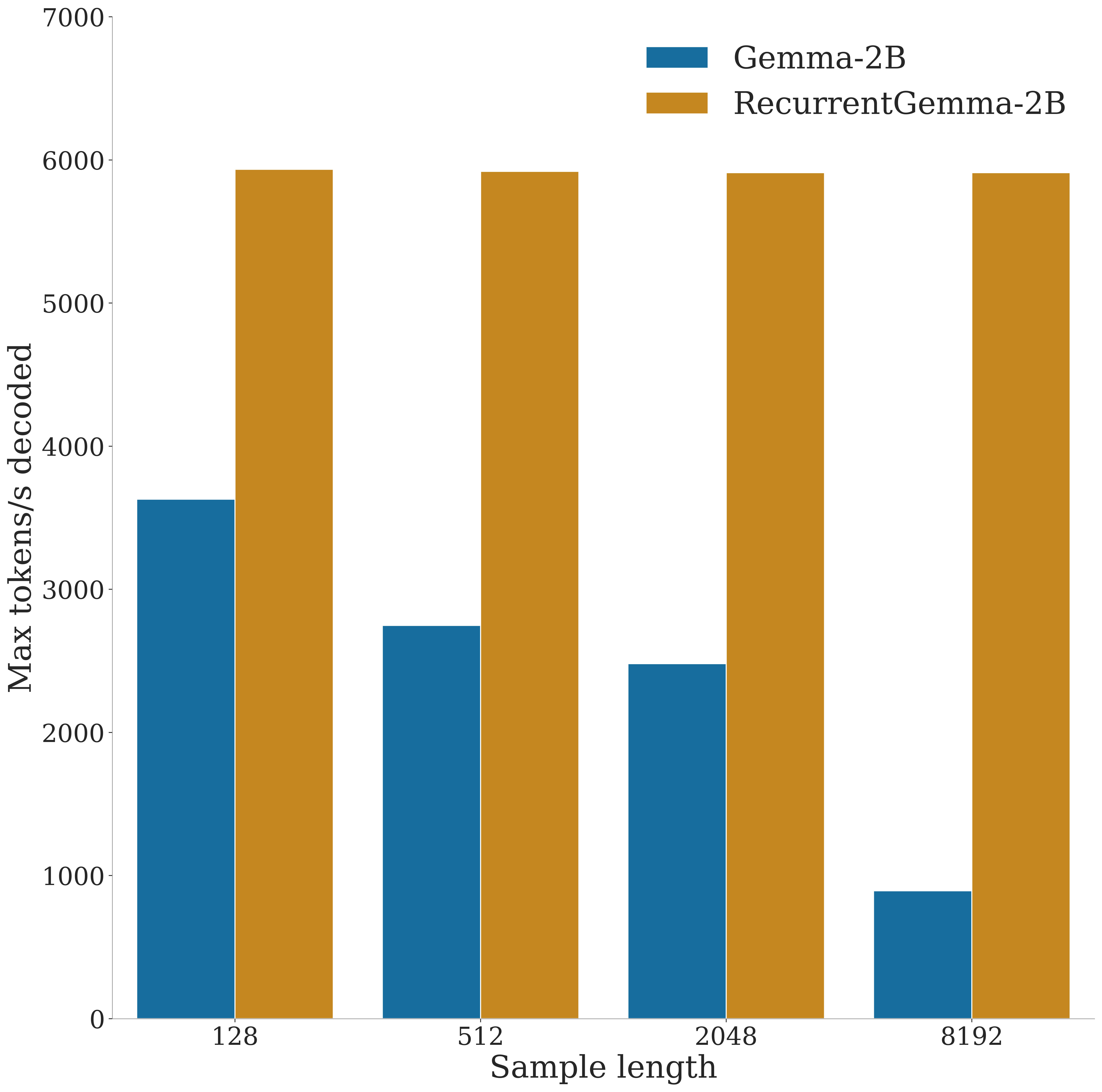
We introduce RecurrentGemma, an open language model which uses Google's novel Griffin architecture. Griffin combines linear recurrences with local attention to achieve excellent performance on language. It has a fixed-sized state, which reduces memory use and enables efficient inference on long sequences. We provide a pre-trained model with 2B non-embedding parameters, and an instruction tuned variant. Both models achieve comparable performance to Gemma-2B despite being trained on fewer tokens.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper introduces a new language model called RecurrentGemma, which aims to move beyond the current Transformer-based models for more efficient open-ended language tasks.
- RecurrentGemma uses a recurrent neural network (RNN) architecture instead of the standard Transformer, with the goal of achieving better performance and lower computational requirements.
- The paper presents the model architecture, training details, and experimental results comparing RecurrentGemma to state-of-the-art Transformer models.
Plain English Explanation
The researchers behind this paper have developed a new type of language model called RecurrentGemma. Language models are AI systems that can understand and generate human language. The most popular language models today are based on a neural network architecture called Transformers, which have become very powerful but also computationally intensive.
RecurrentGemma takes a different approach, using a type of neural network called a recurrent neural network (RNN) instead of Transformers. RNNs have a different internal structure that the researchers believe can achieve similar language understanding capabilities as Transformers, but with lower computational requirements. This could make RecurrentGemma more efficient and practical to deploy, especially for open-ended language tasks like chatbots or virtual assistants.
The paper walks through the details of the RecurrentGemma model architecture, how it was trained, and the results of experiments comparing it to state-of-the-art Transformer language models. The key idea is to explore alternatives to the dominant Transformer approach in an effort to create more efficient and practical language AI systems.
Technical Explanation
The paper introduces a new language model architecture called RecurrentGemma, which uses a recurrent neural network (RNN) design instead of the more prevalent Transformer architecture.
The core of the RecurrentGemma model is a gated recurrent unit (GRU) RNN, which processes text sequentially rather than the more parallel Transformer approach. The GRU RNN is combined with a Gemma module that the authors claim enhances the model's ability to capture long-range dependencies.
To train RecurrentGemma, the researchers used a large corpus of online text data, as well as techniques like prompt-tuning and HGRN2 to further improve performance.
Experimental results showed that RecurrentGemma achieved similar or better performance compared to state-of-the-art Transformer language models like LLAVA on a variety of open-ended language tasks. Importantly, RecurrentGemma also had lower computational requirements, suggesting it could be a more practical and efficient alternative to Transformers for certain applications.
Critical Analysis
The paper provides a thorough technical description of the RecurrentGemma model and the training techniques used. However, it does not delve deeply into the potential limitations or caveats of the approach.
For example, the authors acknowledge that Transformers have advantages in terms of parallelization and capturing long-range dependencies, which the RNN-based RecurrentGemma aims to address. But it's unclear how significant these advantages are in practice, or if there are other tradeoffs (e.g. reduced flexibility, harder to scale) that come with the RNN architecture.
Additionally, the experimental results are mainly focused on performance metrics, without much discussion of real-world applicability or potential issues that may arise when deploying a RecurrentGemma-based system. Aspects like robustness, fairness, and alignment with human values are important considerations that are not addressed.
Overall, the paper presents a potentially promising alternative to Transformer language models, but more in-depth analysis of the approach's limitations and broader implications would be valuable for assessing its true potential and risks.
Conclusion
The RecurrentGemma paper explores a novel direction in language model architecture, moving away from the dominant Transformer design in favor of a recurrent neural network-based approach. The key goal is to create a more efficient and practical language AI system, without sacrificing too much performance.
The technical details and experimental results suggest RecurrentGemma can achieve comparable or better results than state-of-the-art Transformer models, while requiring lower computational resources. This could make it a more viable option for real-world applications, especially in areas like conversational AI where efficiency is important.
However, the paper does not delve deeply into the potential limitations and broader implications of the RecurrentGemma approach. Further research and analysis will be needed to fully understand how this model compares to Transformers and where it might be most effectively deployed. Overall, the paper represents an interesting step forward in the ongoing quest to develop more capable and practical language AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Gemma: Open Models Based on Gemini Research and Technology
Gemma Team, Thomas Mesnard, Cassidy Hardin, Robert Dadashi, Surya Bhupatiraju, Shreya Pathak, Laurent Sifre, Morgane Rivi`ere, Mihir Sanjay Kale, Juliette Love, Pouya Tafti, L'eonard Hussenot, Pier Giuseppe Sessa, Aakanksha Chowdhery, Adam Roberts, Aditya Barua, Alex Botev, Alex Castro-Ros, Ambrose Slone, Am'elie H'eliou, Andrea Tacchetti, Anna Bulanova, Antonia Paterson, Beth Tsai, Bobak Shahriari, Charline Le Lan, Christopher A. Choquette-Choo, Cl'ement Crepy, Daniel Cer, Daphne Ippolito, David Reid, Elena Buchatskaya, Eric Ni, Eric Noland, Geng Yan, George Tucker, George-Christian Muraru, Grigory Rozhdestvenskiy, Henryk Michalewski, Ian Tenney, Ivan Grishchenko, Jacob Austin, James Keeling, Jane Labanowski, Jean-Baptiste Lespiau, Jeff Stanway, Jenny Brennan, Jeremy Chen, Johan Ferret, Justin Chiu, Justin Mao-Jones, Katherine Lee, Kathy Yu, Katie Millican, Lars Lowe Sjoesund, Lisa Lee, Lucas Dixon, Machel Reid, Maciej Miku{l}a, Mateo Wirth, Michael Sharman, Nikolai Chinaev, Nithum Thain, Olivier Bachem, Oscar Chang, Oscar Wahltinez, Paige Bailey, Paul Michel, Petko Yotov, Rahma Chaabouni, Ramona Comanescu, Reena Jana, Rohan Anil, Ross McIlroy, Ruibo Liu, Ryan Mullins, Samuel L Smith, Sebastian Borgeaud, Sertan Girgin, Sholto Douglas, Shree Pandya, Siamak Shakeri, Soham De, Ted Klimenko, Tom Hennigan, Vlad Feinberg, Wojciech Stokowiec, Yu-hui Chen, Zafarali Ahmed, Zhitao Gong, Tris Warkentin, Ludovic Peran, Minh Giang, Cl'ement Farabet, Oriol Vinyals, Jeff Dean, Koray Kavukcuoglu, Demis Hassabis, Zoubin Ghahramani, Douglas Eck, Joelle Barral, Fernando Pereira, Eli Collins, Armand Joulin, Noah Fiedel, Evan Senter, Alek Andreev, Kathleen Kenealy
0
0
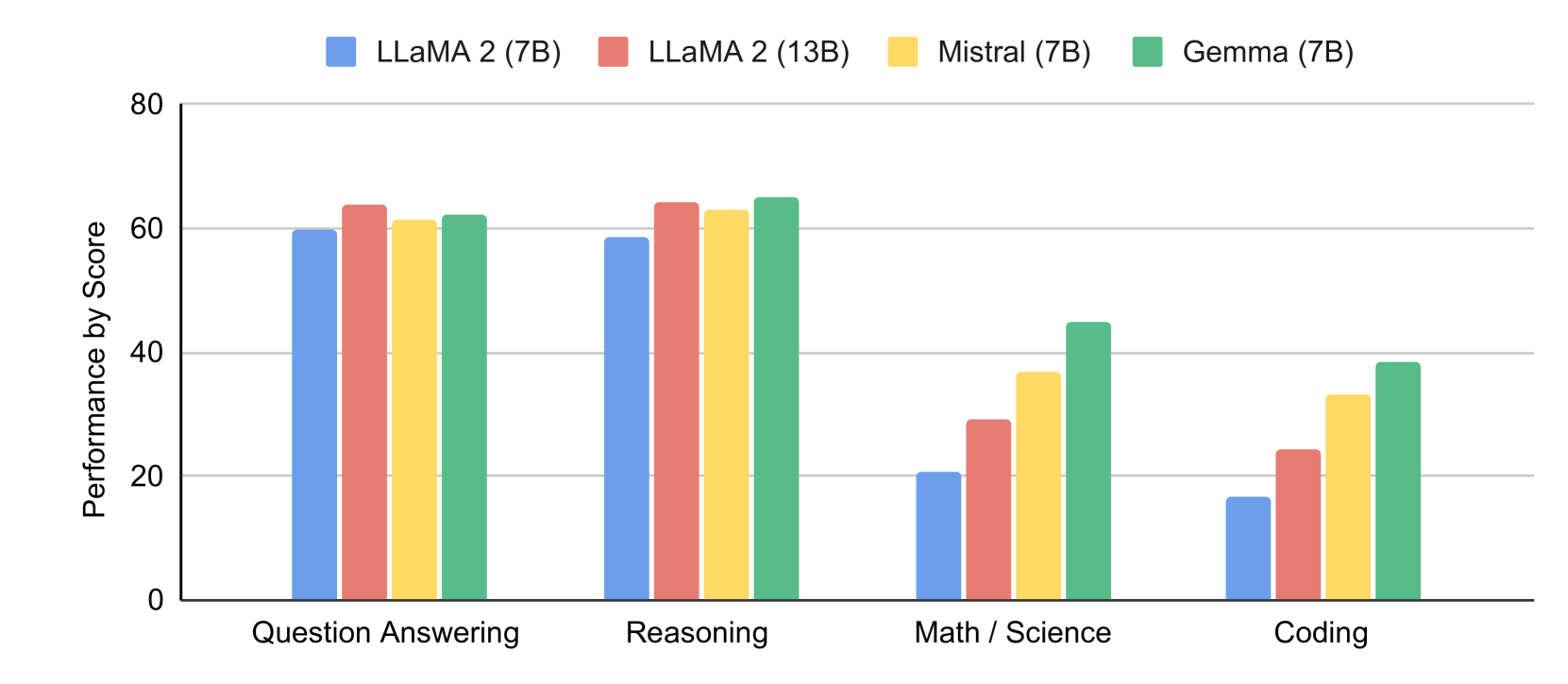
This work introduces Gemma, a family of lightweight, state-of-the art open models built from the research and technology used to create Gemini models. Gemma models demonstrate strong performance across academic benchmarks for language understanding, reasoning, and safety. We release two sizes of models (2 billion and 7 billion parameters), and provide both pretrained and fine-tuned checkpoints. Gemma outperforms similarly sized open models on 11 out of 18 text-based tasks, and we present comprehensive evaluations of safety and responsibility aspects of the models, alongside a detailed description of model development. We believe the responsible release of LLMs is critical for improving the safety of frontier models, and for enabling the next wave of LLM innovations.
4/17/2024
LLaVA-Gemma: Accelerating Multimodal Foundation Models with a Compact Language Model
Musashi Hinck, Matthew L. Olson, David Cobbley, Shao-Yen Tseng, Vasudev Lal
0
0
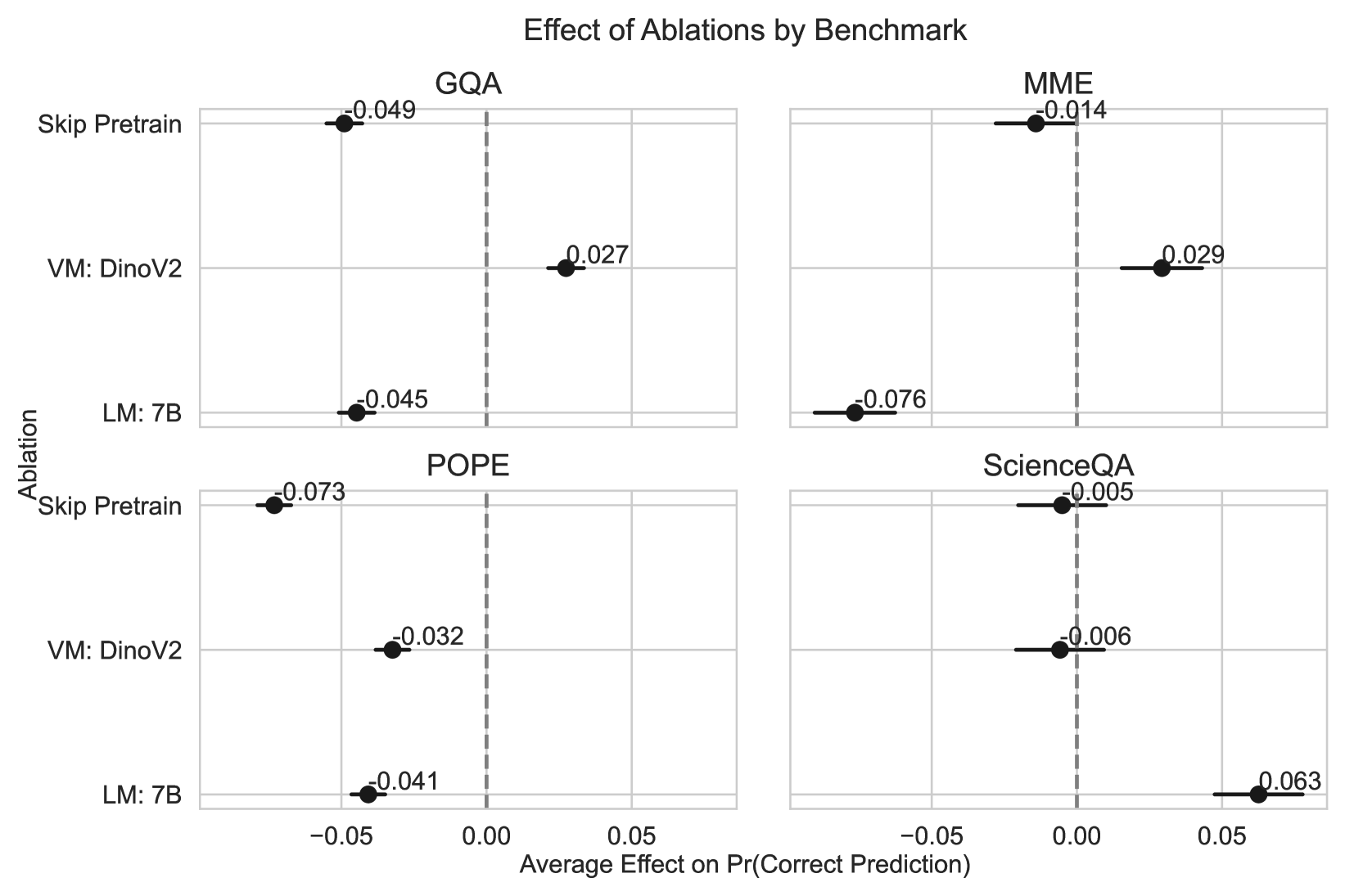
We train a suite of multimodal foundation models (MMFM) using the popular LLaVA framework with the recently released Gemma family of large language models (LLMs). Of particular interest is the 2B parameter Gemma model, which provides opportunities to construct capable small-scale MMFMs. In line with findings from other papers in this space, we test the effect of ablating three design features: pretraining the connector, utilizing a more powerful image backbone, and increasing the size of the language backbone. The resulting models, which we call LLaVA-Gemma, exhibit moderate performance on an array of evaluations, but fail to improve past the current comparably sized SOTA models. Closer analysis of performance shows mixed effects; skipping pretraining tends to reduce performance, larger vision models sometimes improve performance, and increasing language model size has inconsistent effects. We publicly release training recipes, code and weights for our models for the LLaVA-Gemma models.
4/3/2024
HGRN2: Gated Linear RNNs with State Expansion
Zhen Qin, Songlin Yang, Weixuan Sun, Xuyang Shen, Dong Li, Weigao Sun, Yiran Zhong
0
0
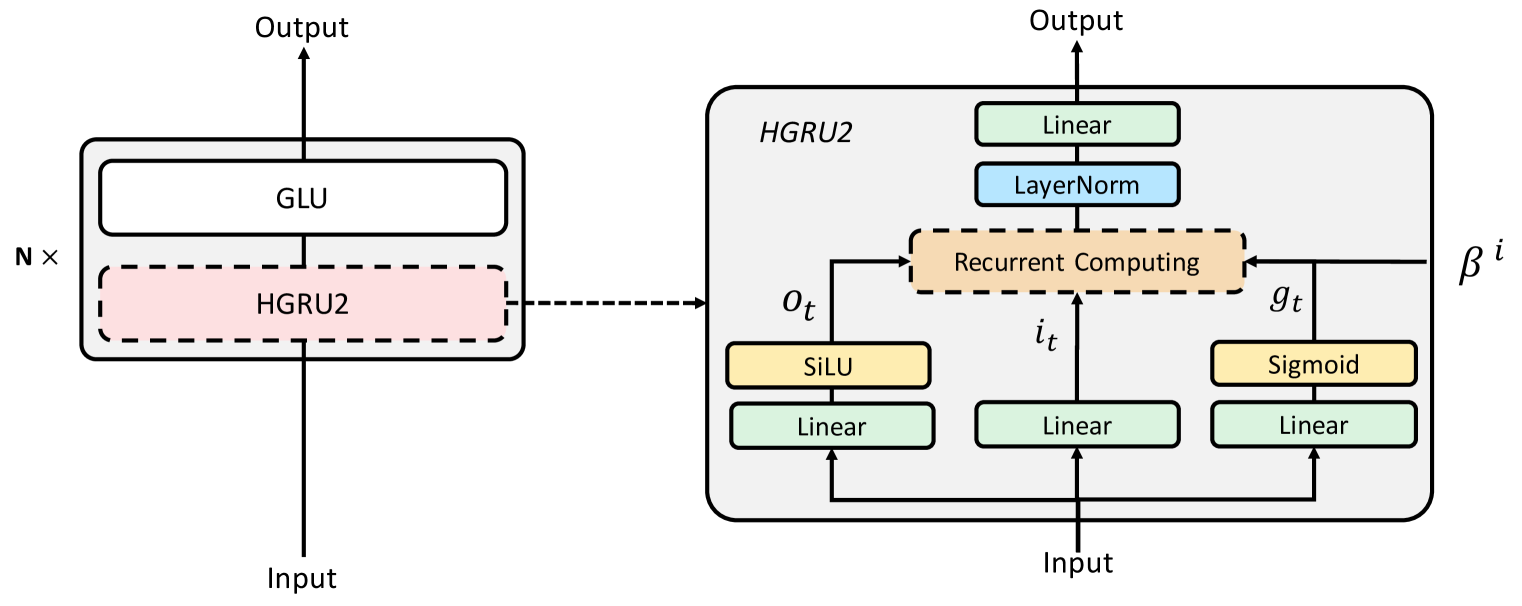
Hierarchically gated linear RNN (HGRN,Qin et al. 2023) has demonstrated competitive training speed and performance in language modeling, while offering efficient inference. However, the recurrent state size of HGRN remains relatively small, which limits its expressiveness.To address this issue, inspired by linear attention, we introduce a simple outer-product-based state expansion mechanism so that the recurrent state size can be significantly enlarged without introducing any additional parameters. The linear attention form also allows for hardware-efficient training.Our extensive experiments verify the advantage of HGRN2 over HGRN1 in language modeling, image classification, and Long Range Arena.Our largest 3B HGRN2 model slightly outperforms Mamba and LLaMa Architecture Transformer for language modeling in a controlled experiment setting; and performs competitively with many open-source 3B models in downstream evaluation while using much fewer total training tokens.
4/12/2024
Prompt-prompted Mixture of Experts for Efficient LLM Generation
Harry Dong, Beidi Chen, Yuejie Chi
0
0
With the development of transformer-based large language models (LLMs), they have been applied to many fields due to their remarkable utility, but this comes at a considerable computational cost at deployment. Fortunately, some methods such as pruning or constructing a mixture of experts (MoE) aim at exploiting sparsity in transformer feedforward (FF) blocks to gain boosts in speed and reduction in memory requirements. However, these techniques can be very costly and inflexible in practice, as they often require training or are restricted to specific types of architectures. To address this, we introduce GRIFFIN, a novel training-free MoE that selects unique FF experts at the sequence level for efficient generation across a plethora of LLMs with different non-ReLU activation functions. This is possible due to a critical observation that many trained LLMs naturally produce highly structured FF activation patterns within a sequence, which we call flocking. Despite our method's simplicity, we show with 50% of the FF parameters, GRIFFIN maintains the original model's performance with little to no degradation on a variety of classification and generation tasks, all while improving latency (e.g. 1.25$times$ speed-up in Llama 2 13B on an NVIDIA L40). Code is available at https://github.com/hdong920/GRIFFIN.
4/8/2024