HiddenGuard: Fine-Grained Safe Generation with Specialized Representation Router

0

Sign in to get full access
Overview
- The paper presents HiddenGuard, a system for fine-grained safe text generation using a specialized representation router.
- HiddenGuard aims to address challenges with refusal alignment by routing potentially unsafe content through specialized models.
- The system uses a combination of techniques, including a specialized representation router, to identify and handle potentially unsafe content during the generation process.
Plain English Explanation
The paper introduces HiddenGuard, a system designed to generate text in a safe and controlled manner. The key idea is to use a specialized "representation router" to identify and handle potentially unsafe content during the generation process.
Traditionally, text generation systems have struggled with the problem of "refusal alignment" - ensuring that the generated text aligns with the intended safety and ethical standards. HiddenGuard aims to address this challenge by routing potentially problematic content through specialized models that can identify and handle it appropriately.
For example, if the main generation model starts to produce text that could be harmful or offensive, HiddenGuard's representation router would detect this and redirect the generation process to a specialized model that is trained to generate safe and appropriate content instead. This allows the system to maintain fine-grained control over the generated text, ensuring that it meets the desired safety and ethical criteria.
Technical Explanation
The core of HiddenGuard is the specialized representation router, which is responsible for identifying and routing potentially unsafe content during the generation process. This router is trained on a diverse set of data, including examples of harmful or undesirable content, to learn to recognize and handle such content effectively.
When the main generation model starts to produce potentially unsafe text, the representation router steps in and redirects the generation to a specialized "safe" model. This specialized model is trained to generate text that aligns with the desired safety and ethical standards, ensuring that the final output is free of harmful or undesirable content.
The paper also describes other techniques used in HiddenGuard, such as the use of fine-grained control mechanisms and the integration of external safety checks. These additional components help to further refine and enhance the system's ability to generate safe and ethically-aligned text.
Critical Analysis
The paper acknowledges some of the potential limitations and challenges of the HiddenGuard approach. For example, the system's effectiveness is heavily dependent on the quality and diversity of the training data used to train the representation router and the specialized "safe" models. If the training data is biased or incomplete, the system may struggle to handle certain types of unsafe content.
Additionally, the paper notes that the computational overhead of the representation router and the specialized models may be a concern, particularly in real-time or resource-constrained applications. The authors suggest that further research is needed to optimize the system's efficiency and scalability.
Another potential issue is the inherent difficulty in defining and evaluating "safe" and "ethical" text generation, as these concepts can be highly subjective and context-dependent. The paper does not delve deeply into the philosophical and ethical considerations surrounding these issues, which could be an area for further exploration and discussion.
Conclusion
HiddenGuard represents a promising approach to addressing the challenge of fine-grained safe text generation. By using a specialized representation router and targeted safe generation models, the system aims to maintain tight control over the content being generated, reducing the risk of harmful or undesirable outputs.
While the paper highlights some of the technical and practical challenges, the overall concept of HiddenGuard is an important step towards developing more robust and responsible text generation systems. As the field of natural language processing continues to advance, the need for such safety-focused approaches will only grow more critical.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!HiddenGuard: Fine-Grained Safe Generation with Specialized Representation Router
Lingrui Mei, Shenghua Liu, Yiwei Wang, Baolong Bi, Ruibin Yuan, Xueqi Cheng
As Large Language Models (LLMs) grow increasingly powerful, ensuring their safety and alignment with human values remains a critical challenge. Ideally, LLMs should provide informative responses while avoiding the disclosure of harmful or sensitive information. However, current alignment approaches, which rely heavily on refusal strategies, such as training models to completely reject harmful prompts or applying coarse filters are limited by their binary nature. These methods either fully deny access to information or grant it without sufficient nuance, leading to overly cautious responses or failures to detect subtle harmful content. For example, LLMs may refuse to provide basic, public information about medication due to misuse concerns. Moreover, these refusal-based methods struggle to handle mixed-content scenarios and lack the ability to adapt to context-dependent sensitivities, which can result in over-censorship of benign content. To overcome these challenges, we introduce HiddenGuard, a novel framework for fine-grained, safe generation in LLMs. HiddenGuard incorporates Prism (rePresentation Router for In-Stream Moderation), which operates alongside the LLM to enable real-time, token-level detection and redaction of harmful content by leveraging intermediate hidden states. This fine-grained approach allows for more nuanced, context-aware moderation, enabling the model to generate informative responses while selectively redacting or replacing sensitive information, rather than outright refusal. We also contribute a comprehensive dataset with token-level fine-grained annotations of potentially harmful information across diverse contexts. Our experiments demonstrate that HiddenGuard achieves over 90% in F1 score for detecting and redacting harmful content while preserving the overall utility and informativeness of the model's responses.
Read more10/4/2024
💬
0
RigorLLM: Resilient Guardrails for Large Language Models against Undesired Content
Zhuowen Yuan, Zidi Xiong, Yi Zeng, Ning Yu, Ruoxi Jia, Dawn Song, Bo Li
Recent advancements in Large Language Models (LLMs) have showcased remarkable capabilities across various tasks in different domains. However, the emergence of biases and the potential for generating harmful content in LLMs, particularly under malicious inputs, pose significant challenges. Current mitigation strategies, while effective, are not resilient under adversarial attacks. This paper introduces Resilient Guardrails for Large Language Models (RigorLLM), a novel framework designed to efficiently and effectively moderate harmful and unsafe inputs and outputs for LLMs. By employing a multi-faceted approach that includes energy-based training data augmentation through Langevin dynamics, optimizing a safe suffix for inputs via minimax optimization, and integrating a fusion-based model combining robust KNN with LLMs based on our data augmentation, RigorLLM offers a robust solution to harmful content moderation. Our experimental evaluations demonstrate that RigorLLM not only outperforms existing baselines like OpenAI API and Perspective API in detecting harmful content but also exhibits unparalleled resilience to jailbreaking attacks. The innovative use of constrained optimization and a fusion-based guardrail approach represents a significant step forward in developing more secure and reliable LLMs, setting a new standard for content moderation frameworks in the face of evolving digital threats.
Read more7/25/2024
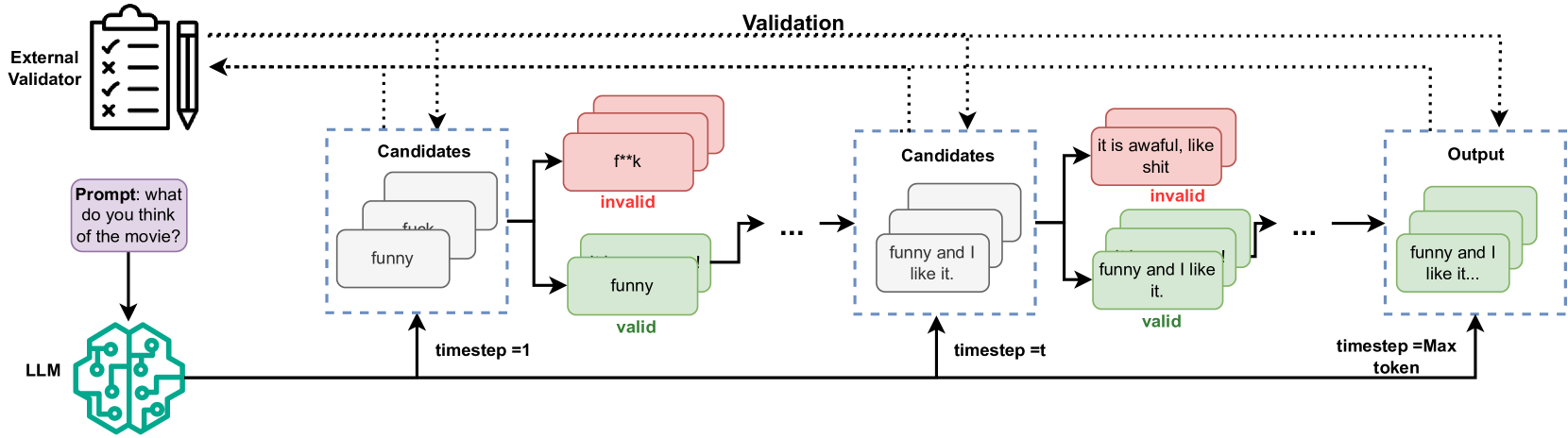
0
A Framework for Real-time Safeguarding the Text Generation of Large Language
Ximing Dong, Dayi Lin, Shaowei Wang, Ahmed E. Hassan
Large Language Models (LLMs) have significantly advanced natural language processing (NLP) tasks but also pose ethical and societal risks due to their propensity to generate harmful content. To address this, various approaches have been developed to safeguard LLMs from producing unsafe content. However, existing methods have limitations, including the need for training specific control models and proactive intervention during text generation, that lead to quality degradation and increased computational overhead. To mitigate those limitations, we propose LLMSafeGuard, a lightweight framework to safeguard LLM text generation in real-time. LLMSafeGuard integrates an external validator into the beam search algorithm during decoding, rejecting candidates that violate safety constraints while allowing valid ones to proceed. We introduce a similarity based validation approach, simplifying constraint introduction and eliminating the need for control model training. Additionally, LLMSafeGuard employs a context-wise timing selection strategy, intervening LLMs only when necessary. We evaluate LLMSafeGuard on two tasks, detoxification and copyright safeguarding, and demonstrate its superior performance over SOTA baselines. For instance, LLMSafeGuard reduces the average toxic score of. LLM output by 29.7% compared to the best baseline meanwhile preserving similar linguistic quality as natural output in detoxification task. Similarly, in the copyright task, LLMSafeGuard decreases the Longest Common Subsequence (LCS) by 56.2% compared to baselines. Moreover, our context-wise timing selection strategy reduces inference time by at least 24% meanwhile maintaining comparable effectiveness as validating each time step. LLMSafeGuard also offers tunable parameters to balance its effectiveness and efficiency.
Read more5/3/2024

0
Adaptive Guardrails For Large Language Models via Trust Modeling and In-Context Learning
Jinwei Hu, Yi Dong, Xiaowei Huang
Guardrails have become an integral part of Large language models (LLMs), by moderating harmful or toxic response in order to maintain LLMs' alignment to human expectations. However, the existing guardrail methods do not consider different needs and access rights of individual users, and treat all the users with the same rule. This study introduces an adaptive guardrail mechanism, supported by trust modeling and enhanced with in-context learning, to dynamically modulate access to sensitive content based on user trust metrics. By leveraging a combination of direct interaction trust and authority-verified trust, the system precisely tailors the strictness of content moderation to align with the user's credibility and the specific context of their inquiries. Our empirical evaluations demonstrate that the adaptive guardrail effectively meets diverse user needs, outperforming existing guardrails in practicality while securing sensitive information and precisely managing potentially hazardous content through a context-aware knowledge base. This work is the first to introduce trust-oriented concept within a guardrail system, offering a scalable solution that enriches the discourse on ethical deployment for next-generation LLMs.
Read more8/20/2024