RigorLLM: Resilient Guardrails for Large Language Models against Undesired Content

0
💬
Sign in to get full access
Overview
- Provides a template for citing AI research papers in a standardized "PRIME AI Style"
- Covers key elements like authors, title, pages, and DOI
- Aims to establish a consistent citation format for the AI research community
Plain English Explanation
The provided paper presents a template for citing AI research papers in a standardized "PRIME AI Style." This format includes key elements such as the authors, title, pages, and DOI. The goal is to establish a consistent citation style for the AI research community, similar to how other fields have standardized citation formats like APA or MLA. This would make it easier to reference and track AI research publications.
Technical Explanation
The paper outlines the key components of the proposed "PRIME AI Style" citation format:
- Authors: The names of the authors who conducted the research
- Title: The title of the research paper
- Pages: The page numbers where the paper can be found
- DOI: The Digital Object Identifier, a unique code that identifies the paper
The paper emphasizes the importance of establishing a standardized citation style for the AI research community, as this would improve the organization and accessibility of published work in the field. By consistently citing papers in this format, researchers and readers can more easily locate and reference relevant studies.
Critical Analysis
The paper provides a clear and concise template for citing AI research papers, which could be a valuable contribution to the field. However, it doesn't address potential challenges or limitations in implementing this citation style. For example, it doesn't mention how this format would integrate with existing citation management tools or databases.
Additionally, the paper does not discuss how this style might be adopted and enforced within the AI research community. It would be helpful to have more information on the process of establishing and promoting the "PRIME AI Style" as a new standard.
Conclusion
The proposed "PRIME AI Style" citation format presented in this paper could help standardize the way AI research is referenced and tracked. By providing a consistent structure for citing key details like authors, titles, and DOIs, this template could improve the organization and accessibility of published AI studies. While the paper outlines the basic components of the format, further discussion on implementation and adoption within the research community would be beneficial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
RigorLLM: Resilient Guardrails for Large Language Models against Undesired Content
Zhuowen Yuan, Zidi Xiong, Yi Zeng, Ning Yu, Ruoxi Jia, Dawn Song, Bo Li
Recent advancements in Large Language Models (LLMs) have showcased remarkable capabilities across various tasks in different domains. However, the emergence of biases and the potential for generating harmful content in LLMs, particularly under malicious inputs, pose significant challenges. Current mitigation strategies, while effective, are not resilient under adversarial attacks. This paper introduces Resilient Guardrails for Large Language Models (RigorLLM), a novel framework designed to efficiently and effectively moderate harmful and unsafe inputs and outputs for LLMs. By employing a multi-faceted approach that includes energy-based training data augmentation through Langevin dynamics, optimizing a safe suffix for inputs via minimax optimization, and integrating a fusion-based model combining robust KNN with LLMs based on our data augmentation, RigorLLM offers a robust solution to harmful content moderation. Our experimental evaluations demonstrate that RigorLLM not only outperforms existing baselines like OpenAI API and Perspective API in detecting harmful content but also exhibits unparalleled resilience to jailbreaking attacks. The innovative use of constrained optimization and a fusion-based guardrail approach represents a significant step forward in developing more secure and reliable LLMs, setting a new standard for content moderation frameworks in the face of evolving digital threats.
Read more7/25/2024

0
LoRA-Guard: Parameter-Efficient Guardrail Adaptation for Content Moderation of Large Language Models
Hayder Elesedy, Pedro M. Esperanc{c}a, Silviu Vlad Oprea, Mete Ozay
Guardrails have emerged as an alternative to safety alignment for content moderation of large language models (LLMs). Existing model-based guardrails have not been designed for resource-constrained computational portable devices, such as mobile phones, more and more of which are running LLM-based applications locally. We introduce LoRA-Guard, a parameter-efficient guardrail adaptation method that relies on knowledge sharing between LLMs and guardrail models. LoRA-Guard extracts language features from the LLMs and adapts them for the content moderation task using low-rank adapters, while a dual-path design prevents any performance degradation on the generative task. We show that LoRA-Guard outperforms existing approaches with 100-1000x lower parameter overhead while maintaining accuracy, enabling on-device content moderation.
Read more7/4/2024
🤖
0
Current state of LLM Risks and AI Guardrails
Suriya Ganesh Ayyamperumal, Limin Ge
Large language models (LLMs) have become increasingly sophisticated, leading to widespread deployment in sensitive applications where safety and reliability are paramount. However, LLMs have inherent risks accompanying them, including bias, potential for unsafe actions, dataset poisoning, lack of explainability, hallucinations, and non-reproducibility. These risks necessitate the development of guardrails to align LLMs with desired behaviors and mitigate potential harm. This work explores the risks associated with deploying LLMs and evaluates current approaches to implementing guardrails and model alignment techniques. We examine intrinsic and extrinsic bias evaluation methods and discuss the importance of fairness metrics for responsible AI development. The safety and reliability of agentic LLMs (those capable of real-world actions) are explored, emphasizing the need for testability, fail-safes, and situational awareness. Technical strategies for securing LLMs are presented, including a layered protection model operating at external, secondary, and internal levels. System prompts, Retrieval-Augmented Generation (RAG) architectures, and techniques to minimize bias and protect privacy are highlighted. Effective guardrail design requires a deep understanding of the LLM's intended use case, relevant regulations, and ethical considerations. Striking a balance between competing requirements, such as accuracy and privacy, remains an ongoing challenge. This work underscores the importance of continuous research and development to ensure the safe and responsible use of LLMs in real-world applications.
Read more6/21/2024
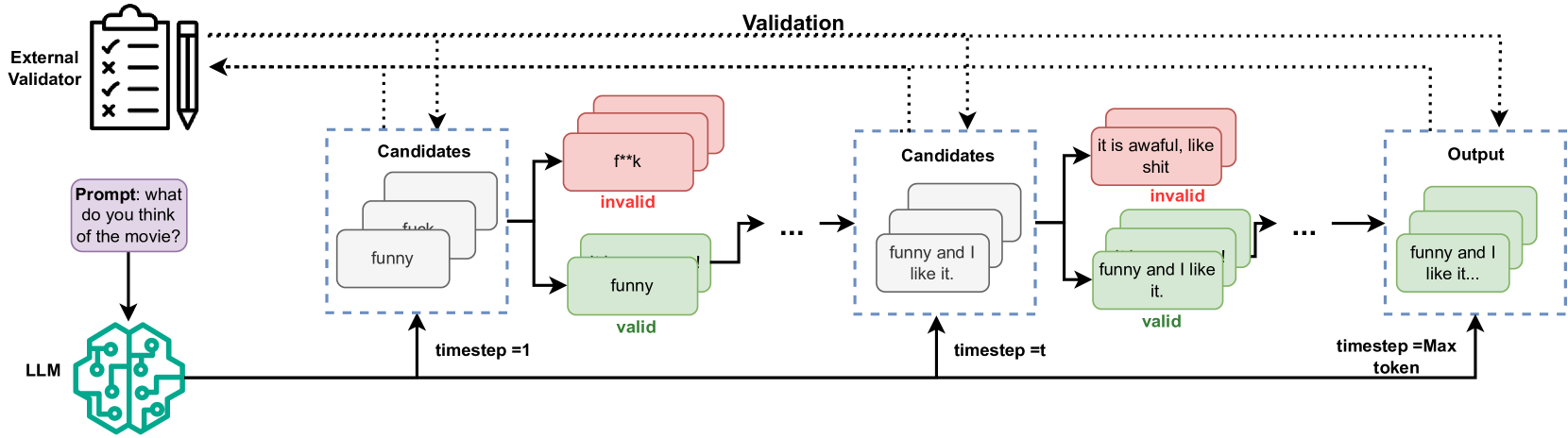
0
A Framework for Real-time Safeguarding the Text Generation of Large Language
Ximing Dong, Dayi Lin, Shaowei Wang, Ahmed E. Hassan
Large Language Models (LLMs) have significantly advanced natural language processing (NLP) tasks but also pose ethical and societal risks due to their propensity to generate harmful content. To address this, various approaches have been developed to safeguard LLMs from producing unsafe content. However, existing methods have limitations, including the need for training specific control models and proactive intervention during text generation, that lead to quality degradation and increased computational overhead. To mitigate those limitations, we propose LLMSafeGuard, a lightweight framework to safeguard LLM text generation in real-time. LLMSafeGuard integrates an external validator into the beam search algorithm during decoding, rejecting candidates that violate safety constraints while allowing valid ones to proceed. We introduce a similarity based validation approach, simplifying constraint introduction and eliminating the need for control model training. Additionally, LLMSafeGuard employs a context-wise timing selection strategy, intervening LLMs only when necessary. We evaluate LLMSafeGuard on two tasks, detoxification and copyright safeguarding, and demonstrate its superior performance over SOTA baselines. For instance, LLMSafeGuard reduces the average toxic score of. LLM output by 29.7% compared to the best baseline meanwhile preserving similar linguistic quality as natural output in detoxification task. Similarly, in the copyright task, LLMSafeGuard decreases the Longest Common Subsequence (LCS) by 56.2% compared to baselines. Moreover, our context-wise timing selection strategy reduces inference time by at least 24% meanwhile maintaining comparable effectiveness as validating each time step. LLMSafeGuard also offers tunable parameters to balance its effectiveness and efficiency.
Read more5/3/2024