Adaptive Guardrails For Large Language Models via Trust Modeling and In-Context Learning

0

Sign in to get full access
Overview
- Explores adaptive guardrails for large language models (LLMs) to improve safety and trustworthiness
- Proposes a framework that leverages trust modeling and in-context learning
- Aims to enable LLMs to calibrate their outputs based on context and user feedback
Plain English Explanation
The paper discusses ways to make large language models (LLMs) more reliable and trustworthy. LLMs are powerful AI systems that can generate human-like text, but they can sometimes produce biased, unsafe, or inappropriate content. The researchers suggest a framework that allows LLMs to adapt their responses based on the specific context and any feedback they receive from users.
The key idea is to have the LLM learn to model its own trustworthiness in a given situation. This "trust model" would help the LLM understand when it should be more cautious or uncertain about its outputs. The LLM can then adjust its behavior accordingly, providing more appropriate and reliable responses.
This approach aims to give LLMs a better sense of their own capabilities and limitations, allowing them to self-regulate and apply appropriate guardrails based on the specific context. It could help address concerns about the safety and reliability of LLMs, especially in sensitive domains like healthcare or finance.
Technical Explanation
The paper proposes a framework that combines two key elements: trust modeling and in-context learning.
Trust Modeling: The LLM learns to predict its own trustworthiness in a given context. This "trust model" is trained alongside the main language model, allowing the LLM to assess the reliability of its own outputs. The trust model considers factors like the input prompt, the LLM's confidence in its response, and any user feedback.
In-Context Learning: The LLM can then use this trust information to adapt its behavior in real-time. When the trust model indicates low confidence or high risk, the LLM can apply appropriate guardrails, such as providing more caveats, refraining from generating certain types of content, or seeking clarification from the user.
The researchers demonstrate the effectiveness of this approach through experiments on a variety of tasks, including language generation, question answering, and code generation. They show that the adaptive guardrails can significantly improve the safety and reliability of the LLM's outputs without compromising its core capabilities.
Critical Analysis
The paper presents a promising approach to enhancing the trustworthiness of large language models, but there are a few potential limitations and areas for further research:
-
The trust model's accuracy and reliability: The effectiveness of the framework ultimately depends on the trust model's ability to accurately assess the LLM's trustworthiness in different contexts. More research is needed to understand the factors that influence trust modeling and how to improve its robustness.
-
Generalization to diverse domains and tasks: While the experiments covered a range of scenarios, it's unclear how well the framework would scale to highly specialized or rapidly evolving domains, where the LLM's knowledge and capabilities may be more limited.
-
Interpretability and transparency: The inner workings of the trust model and the decision-making process behind the adaptive guardrails could benefit from greater interpretability and transparency, to help users understand the system's reasoning and build trust.
-
Potential for gaming or manipulation: In some cases, users might try to game the system by providing misleading feedback or prompts to circumvent the guardrails. Strategies to mitigate such attempts would be an important area for further research.
Overall, the proposed framework represents a significant step forward in enhancing the safety and reliability of large language models, but continued research and development will be necessary to address these and other challenges.
Conclusion
This paper presents an innovative approach to improving the trustworthiness of large language models through the integration of trust modeling and in-context learning. By enabling LLMs to assess and calibrate their own outputs based on the context and user feedback, the framework aims to provide more reliable and appropriate responses, especially in sensitive domains.
The key insights and contributions of this research could have far-reaching implications for the responsible development and deployment of large language models, helping to address pressing concerns about their safety and reliability. As these powerful AI systems become increasingly ubiquitous, such adaptive guardrail techniques may prove crucial in ensuring their beneficial and trustworthy application in real-world settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Adaptive Guardrails For Large Language Models via Trust Modeling and In-Context Learning
Jinwei Hu, Yi Dong, Xiaowei Huang
Guardrails have become an integral part of Large language models (LLMs), by moderating harmful or toxic response in order to maintain LLMs' alignment to human expectations. However, the existing guardrail methods do not consider different needs and access rights of individual users, and treat all the users with the same rule. This study introduces an adaptive guardrail mechanism, supported by trust modeling and enhanced with in-context learning, to dynamically modulate access to sensitive content based on user trust metrics. By leveraging a combination of direct interaction trust and authority-verified trust, the system precisely tailors the strictness of content moderation to align with the user's credibility and the specific context of their inquiries. Our empirical evaluations demonstrate that the adaptive guardrail effectively meets diverse user needs, outperforming existing guardrails in practicality while securing sensitive information and precisely managing potentially hazardous content through a context-aware knowledge base. This work is the first to introduce trust-oriented concept within a guardrail system, offering a scalable solution that enriches the discourse on ethical deployment for next-generation LLMs.
Read more8/20/2024

0
Building Guardrails for Large Language Models
Yi Dong, Ronghui Mu, Gaojie Jin, Yi Qi, Jinwei Hu, Xingyu Zhao, Jie Meng, Wenjie Ruan, Xiaowei Huang
As Large Language Models (LLMs) become more integrated into our daily lives, it is crucial to identify and mitigate their risks, especially when the risks can have profound impacts on human users and societies. Guardrails, which filter the inputs or outputs of LLMs, have emerged as a core safeguarding technology. This position paper takes a deep look at current open-source solutions (Llama Guard, Nvidia NeMo, Guardrails AI), and discusses the challenges and the road towards building more complete solutions. Drawing on robust evidence from previous research, we advocate for a systematic approach to construct guardrails for LLMs, based on comprehensive consideration of diverse contexts across various LLMs applications. We propose employing socio-technical methods through collaboration with a multi-disciplinary team to pinpoint precise technical requirements, exploring advanced neural-symbolic implementations to embrace the complexity of the requirements, and developing verification and testing to ensure the utmost quality of the final product.
Read more5/30/2024
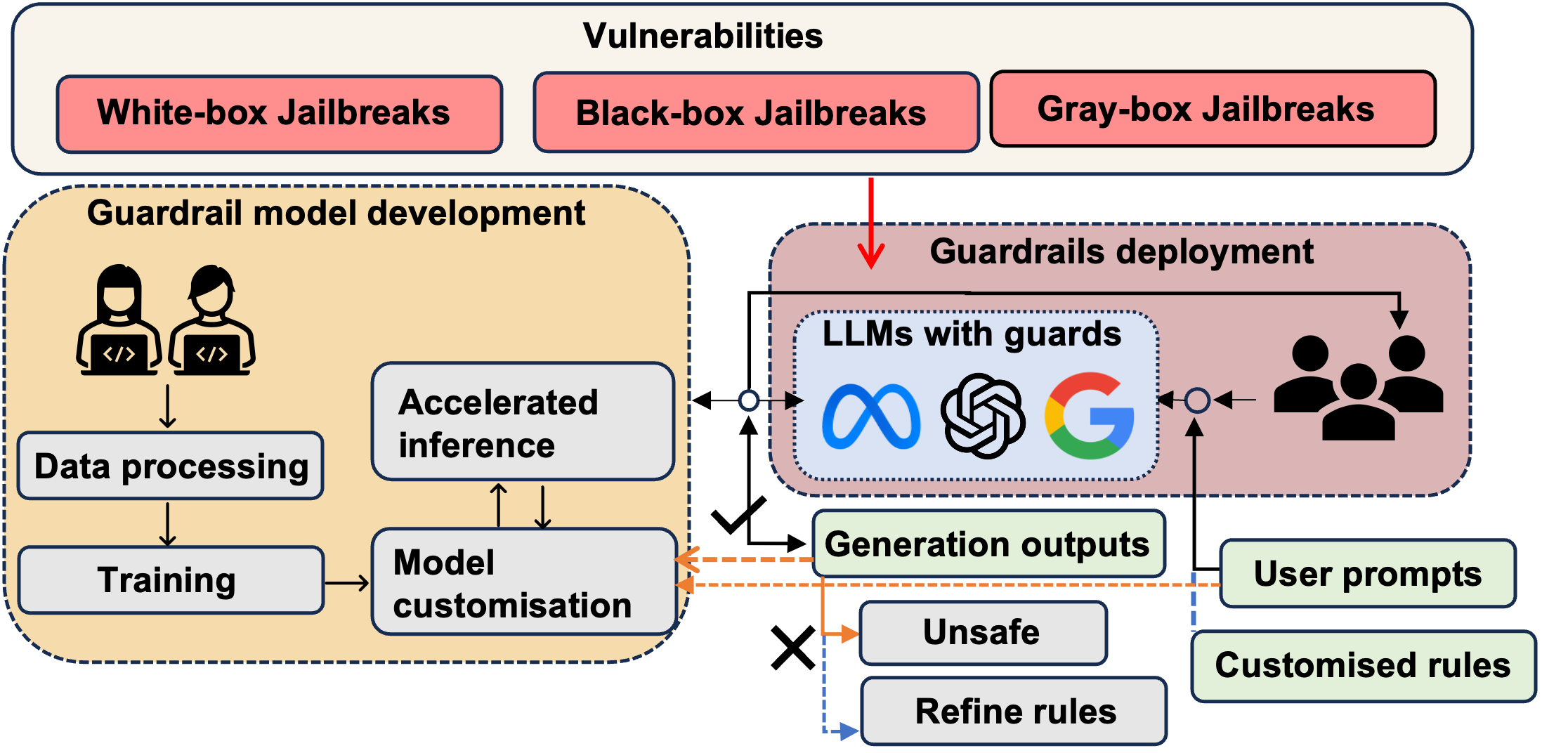
0
Safeguarding Large Language Models: A Survey
Yi Dong, Ronghui Mu, Yanghao Zhang, Siqi Sun, Tianle Zhang, Changshun Wu, Gaojie Jin, Yi Qi, Jinwei Hu, Jie Meng, Saddek Bensalem, Xiaowei Huang
In the burgeoning field of Large Language Models (LLMs), developing a robust safety mechanism, colloquially known as safeguards or guardrails, has become imperative to ensure the ethical use of LLMs within prescribed boundaries. This article provides a systematic literature review on the current status of this critical mechanism. It discusses its major challenges and how it can be enhanced into a comprehensive mechanism dealing with ethical issues in various contexts. First, the paper elucidates the current landscape of safeguarding mechanisms that major LLM service providers and the open-source community employ. This is followed by the techniques to evaluate, analyze, and enhance some (un)desirable properties that a guardrail might want to enforce, such as hallucinations, fairness, privacy, and so on. Based on them, we review techniques to circumvent these controls (i.e., attacks), to defend the attacks, and to reinforce the guardrails. While the techniques mentioned above represent the current status and the active research trends, we also discuss several challenges that cannot be easily dealt with by the methods and present our vision on how to implement a comprehensive guardrail through the full consideration of multi-disciplinary approach, neural-symbolic method, and systems development lifecycle.
Read more6/6/2024

0
LoRA-Guard: Parameter-Efficient Guardrail Adaptation for Content Moderation of Large Language Models
Hayder Elesedy, Pedro M. Esperanc{c}a, Silviu Vlad Oprea, Mete Ozay
Guardrails have emerged as an alternative to safety alignment for content moderation of large language models (LLMs). Existing model-based guardrails have not been designed for resource-constrained computational portable devices, such as mobile phones, more and more of which are running LLM-based applications locally. We introduce LoRA-Guard, a parameter-efficient guardrail adaptation method that relies on knowledge sharing between LLMs and guardrail models. LoRA-Guard extracts language features from the LLMs and adapts them for the content moderation task using low-rank adapters, while a dual-path design prevents any performance degradation on the generative task. We show that LoRA-Guard outperforms existing approaches with 100-1000x lower parameter overhead while maintaining accuracy, enabling on-device content moderation.
Read more7/4/2024