Hierarchical Decision Mamba

0
💬
Sign in to get full access
Overview
- Recent advancements in imitation learning have focused on incorporating sequence models, which provide a structured flow of information to effectively mimic task behaviors.
- Decision Transformer (DT) and Hierarchical Decision Transformer (HDT) are Transformer-based approaches to learn task policies.
- The Mamba architecture has shown to outperform Transformers across various task domains.
- This work introduces two novel methods, Decision Mamba (DM) and Hierarchical Decision Mamba (HDM), aimed at enhancing the performance of the Transformer models.
Plain English Explanation
Imitation learning is a technique where an AI system learns to perform a task by observing and mimicking human behavior. Recent advancements in this field have focused on using sequence models, which can capture the flow of information over time, to more effectively learn and replicate task behaviors.
The Decision Transformer (DT) and Hierarchical Decision Transformer (HDT) are two examples of AI models that use Transformer-based architectures to learn task policies. Transformers are a type of neural network that excel at processing and generating sequences of data, making them well-suited for imitation learning.
More recently, the Mamba architecture has been shown to outperform Transformer-based models across a variety of tasks. Mamba is a novel approach to sequence modeling that combines the strengths of different types of neural networks.
The current work introduces two new models, Decision Mamba (DM) and Hierarchical Decision Mamba (HDM), which aim to further enhance the performance of Transformer-based imitation learning approaches. These models leverage the Mamba architecture to potentially improve upon the capabilities of the earlier Transformer-based models.
Technical Explanation
This paper presents two novel imitation learning models, Decision Mamba (DM) and Hierarchical Decision Mamba (HDM), that build upon the success of the Mamba architecture.
The authors conduct extensive experiments across diverse environments, including OpenAI Gym and D4RL, using various demonstration data sets. The results show that the Mamba-based models, DM and HDM, outperform the Transformer-based Decision Transformer (DT) and Hierarchical Decision Transformer (HDT) models in the majority of the tasks.
The key insight is that the Mamba architecture, which combines the strengths of different neural network components, can more effectively capture the structured flow of information required for imitation learning compared to the Transformer-based approaches. The hierarchical version, HDM, is shown to achieve the best performance in most of the evaluated settings.
The code for the proposed models is available on GitHub.
Critical Analysis
The paper presents a comprehensive evaluation of the proposed DM and HDM models across a diverse set of environments and demonstration data. The authors have made a thoughtful effort to compare the performance of their models against the established Transformer-based approaches, providing a clear and rigorous assessment of the strengths of the Mamba-based architecture.
One potential limitation of the research is the lack of a more in-depth analysis of the specific mechanisms and design choices that contribute to the superior performance of the Mamba-based models. While the results are compelling, a deeper exploration of the underlying factors could provide further insights and guidance for future developments in this area.
Additionally, the paper does not address potential limitations or edge cases where the Mamba-based models may not perform as well as the Transformer-based approaches. Exploring such scenarios could help researchers and practitioners better understand the broader applicability and limitations of the proposed methods.
Overall, this work represents a significant contribution to the field of imitation learning, showcasing the potential of the Mamba architecture to outperform Transformer-based models in a variety of tasks. The introduction of DM and HDM models provides a promising avenue for further research and development in this domain.
Conclusion
This paper introduces two novel imitation learning models, Decision Mamba (DM) and Hierarchical Decision Mamba (HDM), that leverage the Mamba architecture to enhance the performance of Transformer-based approaches.
Through extensive experimentation across diverse environments and demonstration data sets, the authors demonstrate the superiority of the Mamba-based models over the Decision Transformer (DT) and Hierarchical Decision Transformer (HDT) in a majority of the tasks.
The key insight is that the Mamba architecture, which combines different neural network components, can more effectively capture the structured flow of information required for imitation learning compared to the Transformer-based models. The hierarchical version, HDM, is shown to achieve the best performance in most of the evaluated settings.
This work represents a significant contribution to the field of imitation learning, showcasing the potential of the Mamba architecture to outperform Transformer-based models and paving the way for further advancements in this domain.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
0
Hierarchical Decision Mamba
Andr'e Correia, Lu'is A. Alexandre
Recent advancements in imitation learning have been largely fueled by the integration of sequence models, which provide a structured flow of information to effectively mimic task behaviours. Currently, Decision Transformer (DT) and subsequently, the Hierarchical Decision Transformer (HDT), presented Transformer-based approaches to learn task policies. Recently, the Mamba architecture has shown to outperform Transformers across various task domains. In this work, we introduce two novel methods, Decision Mamba (DM) and Hierarchical Decision Mamba (HDM), aimed at enhancing the performance of the Transformer models. Through extensive experimentation across diverse environments such as OpenAI Gym and D4RL, leveraging varying demonstration data sets, we demonstrate the superiority of Mamba models over their Transformer counterparts in a majority of tasks. Results show that HDM outperforms other methods in most settings. The code can be found at https://github.com/meowatthemoon/HierarchicalDecisionMamba.
Read more5/14/2024

0
Decision Mamba: Reinforcement Learning via Hybrid Selective Sequence Modeling
Sili Huang, Jifeng Hu, Zhejian Yang, Liwei Yang, Tao Luo, Hechang Chen, Lichao Sun, Bo Yang
Recent works have shown the remarkable superiority of transformer models in reinforcement learning (RL), where the decision-making problem is formulated as sequential generation. Transformer-based agents could emerge with self-improvement in online environments by providing task contexts, such as multiple trajectories, called in-context RL. However, due to the quadratic computation complexity of attention in transformers, current in-context RL methods suffer from huge computational costs as the task horizon increases. In contrast, the Mamba model is renowned for its efficient ability to process long-term dependencies, which provides an opportunity for in-context RL to solve tasks that require long-term memory. To this end, we first implement Decision Mamba (DM) by replacing the backbone of Decision Transformer (DT). Then, we propose a Decision Mamba-Hybrid (DM-H) with the merits of transformers and Mamba in high-quality prediction and long-term memory. Specifically, DM-H first generates high-value sub-goals from long-term memory through the Mamba model. Then, we use sub-goals to prompt the transformer, establishing high-quality predictions. Experimental results demonstrate that DM-H achieves state-of-the-art in long and short-term tasks, such as D4RL, Grid World, and Tmaze benchmarks. Regarding efficiency, the online testing of DM-H in the long-term task is 28$times$ times faster than the transformer-based baselines.
Read more6/4/2024
🏅
0
Mamba as Decision Maker: Exploring Multi-scale Sequence Modeling in Offline Reinforcement Learning
Jiahang Cao, Qiang Zhang, Ziqing Wang, Jingkai Sun, Jiaxu Wang, Hao Cheng, Yecheng Shao, Wen Zhao, Gang Han, Yijie Guo, Renjing Xu
Sequential modeling has demonstrated remarkable capabilities in offline reinforcement learning (RL), with Decision Transformer (DT) being one of the most notable representatives, achieving significant success. However, RL trajectories possess unique properties to be distinguished from the conventional sequence (e.g., text or audio): (1) local correlation, where the next states in RL are theoretically determined solely by current states and actions based on the Markov Decision Process (MDP), and (2) global correlation, where each step's features are related to long-term historical information due to the time-continuous nature of trajectories. In this paper, we propose a novel action sequence predictor, named Mamba Decision Maker (MambaDM), where Mamba is expected to be a promising alternative for sequence modeling paradigms, owing to its efficient modeling of multi-scale dependencies. In particular, we introduce a novel mixer module that proficiently extracts and integrates both global and local features of the input sequence, effectively capturing interrelationships in RL datasets. Extensive experiments demonstrate that MambaDM achieves state-of-the-art performance in Atari and OpenAI Gym datasets. Furthermore, we empirically investigate the scaling laws of MambaDM, finding that increasing model size does not bring performance improvement, but scaling the dataset amount by 2x for MambaDM can obtain up to 33.7% score improvement on Atari dataset. This paper delves into the sequence modeling capabilities of MambaDM in the RL domain, paving the way for future advancements in robust and efficient decision-making systems.
Read more9/12/2024
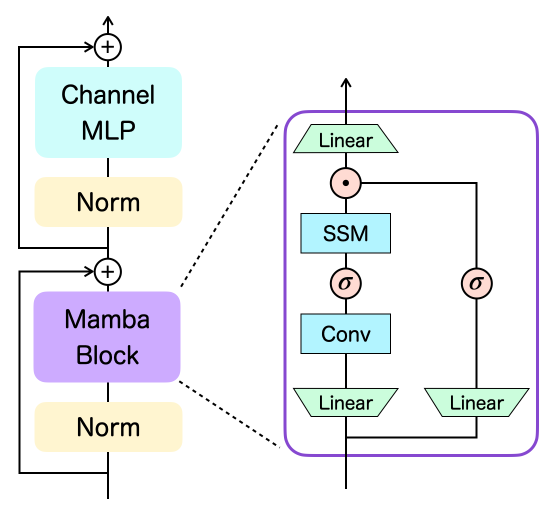
0
Decision Mamba: Reinforcement Learning via Sequence Modeling with Selective State Spaces
Toshihiro Ota
Decision Transformer, a promising approach that applies Transformer architectures to reinforcement learning, relies on causal self-attention to model sequences of states, actions, and rewards. While this method has shown competitive results, this paper investigates the integration of the Mamba framework, known for its advanced capabilities in efficient and effective sequence modeling, into the Decision Transformer architecture, focusing on the potential performance enhancements in sequential decision-making tasks. Our study systematically evaluates this integration by conducting a series of experiments across various decision-making environments, comparing the modified Decision Transformer, Decision Mamba, with its traditional counterpart. This work contributes to the advancement of sequential decision-making models, suggesting that the architecture and training methodology of neural networks can significantly impact their performance in complex tasks, and highlighting the potential of Mamba as a valuable tool for improving the efficacy of Transformer-based models in reinforcement learning scenarios.
Read more4/1/2024