Hierarchical Patch Diffusion Models for High-Resolution Video Generation
2406.07792
0
0

Abstract
Diffusion models have demonstrated remarkable performance in image and video synthesis. However, scaling them to high-resolution inputs is challenging and requires restructuring the diffusion pipeline into multiple independent components, limiting scalability and complicating downstream applications. This makes it very efficient during training and unlocks end-to-end optimization on high-resolution videos. We improve PDMs in two principled ways. First, to enforce consistency between patches, we develop deep context fusion -- an architectural technique that propagates the context information from low-scale to high-scale patches in a hierarchical manner. Second, to accelerate training and inference, we propose adaptive computation, which allocates more network capacity and computation towards coarse image details. The resulting model sets a new state-of-the-art FVD score of 66.32 and Inception Score of 87.68 in class-conditional video generation on UCF-101 $256^2$, surpassing recent methods by more than 100%. Then, we show that it can be rapidly fine-tuned from a base $36times 64$ low-resolution generator for high-resolution $64 times 288 times 512$ text-to-video synthesis. To the best of our knowledge, our model is the first diffusion-based architecture which is trained on such high resolutions entirely end-to-end. Project webpage: https://snap-research.github.io/hpdm.
Create account to get full access
Overview
- This paper presents a hierarchical patch diffusion model for generating high-resolution videos.
- The model uses a multi-scale approach to generate video frames by first generating low-resolution patches and then progressively refining them to higher resolutions.
- The authors claim this approach leads to improved video quality and faster generation times compared to previous methods.
Plain English Explanation
The paper describes a new way to generate high-quality videos using a machine learning technique called diffusion models. Diffusion models work by progressively adding noise to an image or video, and then learning how to reverse that process to generate new content.
The key innovation in this paper is a hierarchical patch-based approach. Instead of generating an entire high-resolution video frame at once, the model first generates low-resolution patches of the frame. It then refines those patches to higher resolutions, gradually building up the full high-resolution frame.
This hierarchical approach has a few advantages. First, it allows the model to focus on smaller, more manageable parts of the frame, which can lead to better quality. Second, it's more computationally efficient than generating the entire high-res frame at once. And third, the multi-scale nature of the process helps the model capture details at different scales, resulting in more realistic and coherent videos.
Overall, this paper presents an interesting new way to generate high-quality videos using diffusion models. The hierarchical patch-based approach seems to offer some advantages over previous video generation techniques.
Technical Explanation
The core of the paper's approach is a hierarchical patch diffusion model. Instead of generating an entire high-resolution video frame at once, the model first generates low-resolution patches of the frame. It then refines those patches to higher resolutions, gradually building up the full high-resolution frame.
This is done using a multi-scale architecture. The model has separate diffusion modules for generating the low-res patches, mid-res patches, and high-res patches. These modules are trained simultaneously, with the outputs of the lower-res modules feeding into the higher-res modules.
The authors claim this approach has several benefits. First, it allows the model to focus on smaller, more manageable parts of the frame, which can lead to better quality. Second, it's more computationally efficient than generating the entire high-res frame at once. And third, the multi-scale nature of the process helps the model capture details at different scales, resulting in more realistic and coherent videos.
To evaluate their approach, the authors conducted experiments on several high-resolution video datasets. They compared their hierarchical patch model to previous state-of-the-art video diffusion models, and found that it achieved better video quality and faster generation times.
Critical Analysis
The paper presents a novel and promising approach to high-resolution video generation using diffusion models. The hierarchical patch-based architecture seems to offer real advantages in terms of video quality and generation speed.
That said, the paper does not explore some potential limitations or challenges of this approach. For example, the authors don't discuss how well the model would scale to even higher resolutions or longer video sequences. There may be practical limits to how far the hierarchical refinement can go before it becomes unwieldy.
Additionally, the paper focuses primarily on quantitative metrics like FID and IS scores. It would be helpful to see more qualitative analysis of the generated videos, including potential artifacts or coherence issues that may arise from the patch-based approach.
[Further research could also explore ways to make the model even more efficient, perhaps by drawing on techniques like DistrifusionDistributed Parallel Inference for High-Resolution Diffusion or MVDiff: Scalable and Flexible Multi-View Diffusion.](https://aimodels.fyi/papers/arxiv/diffusiondollar2dollar-dynamic-3d-content-generation-via-score) Overall, this paper represents an interesting step forward in high-res video generation, but there is likely room for further innovation and refinement.
Conclusion
This paper introduces a hierarchical patch-based diffusion model for generating high-resolution videos. By first generating low-resolution patches and then progressively refining them to higher resolutions, the model is able to produce videos with better quality and faster generation times compared to previous approaches.
The key innovation is the multi-scale, patch-based architecture, which allows the model to focus on manageable parts of the frame and capture details at different scales. While the paper demonstrates promising results, there are likely opportunities to further improve the model's efficiency and explore the limits of its scalability.
Overall, this research represents an interesting advance in the field of video generation using diffusion models. The hierarchical patch-based approach could inspire future work in this area and help drive progress towards more realistic and coherent high-resolution video synthesis.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

DiffuseHigh: Training-free Progressive High-Resolution Image Synthesis through Structure Guidance
Younghyun Kim, Geunmin Hwang, Eunbyung Park
0
0
Recent surge in large-scale generative models has spurred the development of vast fields in computer vision. In particular, text-to-image diffusion models have garnered widespread adoption across diverse domain due to their potential for high-fidelity image generation. Nonetheless, existing large-scale diffusion models are confined to generate images of up to 1K resolution, which is far from meeting the demands of contemporary commercial applications. Directly sampling higher-resolution images often yields results marred by artifacts such as object repetition and distorted shapes. Addressing the aforementioned issues typically necessitates training or fine-tuning models on higher resolution datasets. However, this undertaking poses a formidable challenge due to the difficulty in collecting large-scale high-resolution contents and substantial computational resources. While several preceding works have proposed alternatives, they often fail to produce convincing results. In this work, we probe the generative ability of diffusion models at higher resolution beyond its original capability and propose a novel progressive approach that fully utilizes generated low-resolution image to guide the generation of higher resolution image. Our method obviates the need for additional training or fine-tuning which significantly lowers the burden of computational costs. Extensive experiments and results validate the efficiency and efficacy of our method.
6/27/2024
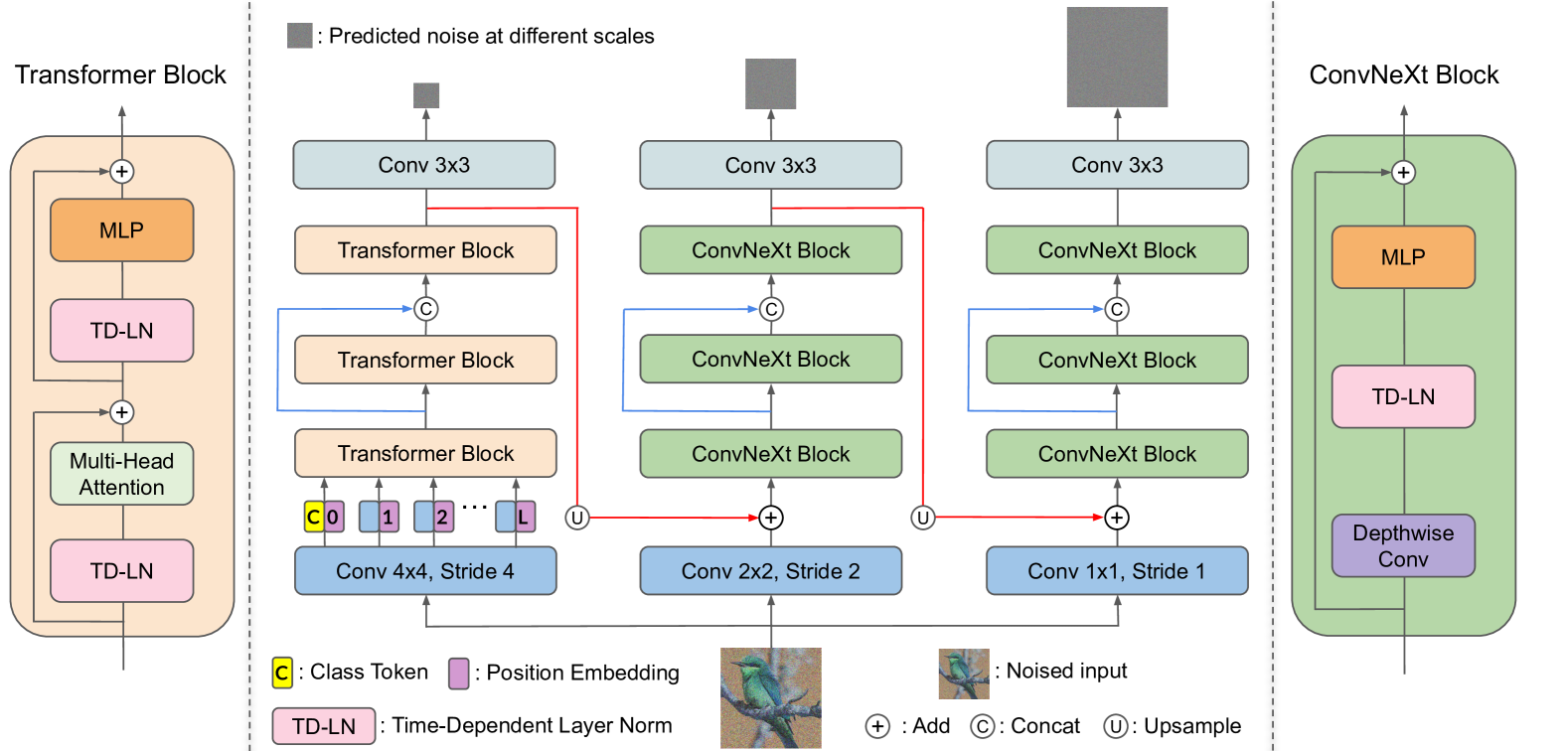
Alleviating Distortion in Image Generation via Multi-Resolution Diffusion Models
Qihao Liu, Zhanpeng Zeng, Ju He, Qihang Yu, Xiaohui Shen, Liang-Chieh Chen
0
0
This paper presents innovative enhancements to diffusion models by integrating a novel multi-resolution network and time-dependent layer normalization. Diffusion models have gained prominence for their effectiveness in high-fidelity image generation. While conventional approaches rely on convolutional U-Net architectures, recent Transformer-based designs have demonstrated superior performance and scalability. However, Transformer architectures, which tokenize input data (via patchification), face a trade-off between visual fidelity and computational complexity due to the quadratic nature of self-attention operations concerning token length. While larger patch sizes enable attention computation efficiency, they struggle to capture fine-grained visual details, leading to image distortions. To address this challenge, we propose augmenting the Diffusion model with the Multi-Resolution network (DiMR), a framework that refines features across multiple resolutions, progressively enhancing detail from low to high resolution. Additionally, we introduce Time-Dependent Layer Normalization (TD-LN), a parameter-efficient approach that incorporates time-dependent parameters into layer normalization to inject time information and achieve superior performance. Our method's efficacy is demonstrated on the class-conditional ImageNet generation benchmark, where DiMR-XL variants outperform prior diffusion models, setting new state-of-the-art FID scores of 1.70 on ImageNet 256 x 256 and 2.89 on ImageNet 512 x 512. Project page: https://qihao067.github.io/projects/DiMR
6/14/2024

DistriFusion: Distributed Parallel Inference for High-Resolution Diffusion Models
Muyang Li, Tianle Cai, Jiaxin Cao, Qinsheng Zhang, Han Cai, Junjie Bai, Yangqing Jia, Ming-Yu Liu, Kai Li, Song Han
0
0
Diffusion models have achieved great success in synthesizing high-quality images. However, generating high-resolution images with diffusion models is still challenging due to the enormous computational costs, resulting in a prohibitive latency for interactive applications. In this paper, we propose DistriFusion to tackle this problem by leveraging parallelism across multiple GPUs. Our method splits the model input into multiple patches and assigns each patch to a GPU. However, naively implementing such an algorithm breaks the interaction between patches and loses fidelity, while incorporating such an interaction will incur tremendous communication overhead. To overcome this dilemma, we observe the high similarity between the input from adjacent diffusion steps and propose displaced patch parallelism, which takes advantage of the sequential nature of the diffusion process by reusing the pre-computed feature maps from the previous timestep to provide context for the current step. Therefore, our method supports asynchronous communication, which can be pipelined by computation. Extensive experiments show that our method can be applied to recent Stable Diffusion XL with no quality degradation and achieve up to a 6.1$times$ speedup on eight NVIDIA A100s compared to one. Our code is publicly available at https://github.com/mit-han-lab/distrifuser.
4/17/2024

4Diffusion: Multi-view Video Diffusion Model for 4D Generation
Haiyu Zhang, Xinyuan Chen, Yaohui Wang, Xihui Liu, Yunhong Wang, Yu Qiao
0
0
Current 4D generation methods have achieved noteworthy efficacy with the aid of advanced diffusion generative models. However, these methods lack multi-view spatial-temporal modeling and encounter challenges in integrating diverse prior knowledge from multiple diffusion models, resulting in inconsistent temporal appearance and flickers. In this paper, we propose a novel 4D generation pipeline, namely 4Diffusion aimed at generating spatial-temporally consistent 4D content from a monocular video. We first design a unified diffusion model tailored for multi-view video generation by incorporating a learnable motion module into a frozen 3D-aware diffusion model to capture multi-view spatial-temporal correlations. After training on a curated dataset, our diffusion model acquires reasonable temporal consistency and inherently preserves the generalizability and spatial consistency of the 3D-aware diffusion model. Subsequently, we propose 4D-aware Score Distillation Sampling loss, which is based on our multi-view video diffusion model, to optimize 4D representation parameterized by dynamic NeRF. This aims to eliminate discrepancies arising from multiple diffusion models, allowing for generating spatial-temporally consistent 4D content. Moreover, we devise an anchor loss to enhance the appearance details and facilitate the learning of dynamic NeRF. Extensive qualitative and quantitative experiments demonstrate that our method achieves superior performance compared to previous methods.
6/3/2024