PatchScaler: An Efficient Patch-independent Diffusion Model for Super-Resolution

0

Sign in to get full access
Overview
- This paper introduces PatchScaler, an efficient patch-independent diffusion model for super-resolution.
- PatchScaler aims to improve the performance and efficiency of diffusion-based super-resolution models by overcoming the limitations of patch-based approaches.
- The model leverages a novel patch-independent architecture and training strategy to enable high-quality super-resolution without the need for complex multi-stage processing.
Plain English Explanation
The goal of this research is to develop a more efficient and effective way to create high-quality super-resolution images using diffusion models. Diffusion models are a type of machine learning algorithm that can be used to generate new images by gradually adding "noise" to an input image and then removing that noise in a controlled way.
One of the challenges with using diffusion models for super-resolution is that they often work best on small, local "patches" of an image, rather than the full image at once. This can lead to inefficiencies and quality issues. The PatchScaler model introduced in this paper addresses this by using a novel architecture and training approach that allows the model to process the full image in a single pass, without relying on patches.
The key ideas behind PatchScaler are:
- Using a patch-independent architecture that can process the entire image at once, rather than breaking it into smaller patches.
- Developing a training strategy that enables this patch-independent approach while still maintaining high-quality super-resolution results.
By overcoming the limitations of patch-based approaches, the researchers show that PatchScaler can achieve state-of-the-art super-resolution performance while being more efficient and simpler to use than previous methods. This could lead to improvements in applications like high-resolution image editing, medical imaging, and video processing.
Technical Explanation
The core innovation of PatchScaler is its patch-independent architecture and training strategy. Rather than relying on a multi-stage, patch-based approach like many previous diffusion-based super-resolution models, PatchScaler is designed to process the full input image in a single forward pass.
The key components of the PatchScaler model include:
- A novel encoder-decoder architecture that takes the full low-resolution input image and directly generates the corresponding high-resolution output.
- A training strategy that combines a global perceptual loss with a local adversarial loss to ensure high-quality, patch-independent super-resolution.
- Efficient inference through parallel processing of the input image, enabled by the patch-independent design.
Through extensive experiments, the authors demonstrate that PatchScaler outperforms state-of-the-art diffusion-based super-resolution models on several benchmark datasets, while also being more computationally efficient. The model's ability to generate high-quality super-resolution images without the need for complex multi-stage processing or patch-based approaches is a significant advancement in the field.
Critical Analysis
The PatchScaler paper presents a compelling and well-executed solution to the challenges of using diffusion models for super-resolution. The patch-independent architecture and training strategy are novel contributions that address key limitations of prior work.
One potential area for further research is the model's performance on larger, high-resolution input images. While the authors demonstrate strong results on standard benchmark datasets, it would be valuable to understand how PatchScaler scales to even higher resolutions and more complex scenes. CutDiffusion and DiffScaler have explored some techniques for improving diffusion-based models for high-resolution generation, and these could potentially be integrated with the PatchScaler approach.
Additionally, the authors note that their method may have limitations when dealing with highly detailed or structured content, such as text or fine-grained patterns. Exploring ways to further improve the model's handling of these challenging cases could be a fruitful area for future research.
Overall, the PatchScaler paper represents a significant contribution to the field of diffusion-based super-resolution. The authors have demonstrated a novel and effective approach that addresses important limitations of prior work, opening up new possibilities for high-quality, efficient image upscaling in a wide range of applications.
Conclusion
The PatchScaler paper introduces an innovative diffusion-based super-resolution model that overcomes the limitations of patch-based approaches through its novel patch-independent architecture and training strategy. By processing the full input image in a single pass, PatchScaler achieves state-of-the-art performance while being more computationally efficient than previous methods.
This research represents an important step forward in the development of practical and effective diffusion models for high-quality image super-resolution. The proposed techniques could lead to significant improvements in applications such as medical imaging, video processing, and high-resolution image editing, ultimately benefiting a wide range of users and industries.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
PatchScaler: An Efficient Patch-independent Diffusion Model for Super-Resolution
Yong Liu, Hang Dong, Jinshan Pan, Qingji Dong, Kai Chen, Rongxiang Zhang, Lean Fu, Fei Wang
Diffusion models significantly improve the quality of super-resolved images with their impressive content generation capabilities. However, the huge computational costs limit the applications of these methods.Recent efforts have explored reasonable inference acceleration to reduce the number of sampling steps, but the computational cost remains high as each step is performed on the entire image.This paper introduces PatchScaler, a patch-independent diffusion-based single image super-resolution (SR) method, designed to enhance the efficiency of the inference process.The proposed method is motivated by the observation that not all the image patches within an image need the same sampling steps for reconstructing high-resolution images.Based on this observation, we thus develop a Patch-adaptive Group Sampling (PGS) to divide feature patches into different groups according to the patch-level reconstruction difficulty and dynamically assign an appropriate sampling configuration for each group so that the inference speed can be better accelerated.In addition, to improve the denoising ability at each step of the sampling, we develop a texture prompt to guide the estimations of the diffusion model by retrieving high-quality texture priors from a patch-independent reference texture memory.Experiments show that our PatchScaler achieves favorable performance in both quantitative and qualitative evaluations with fast inference speed.Our code and model are available at url{https://github.com/yongliuy/PatchScaler}.
Read more6/12/2024

0
Accelerating Image Super-Resolution Networks with Pixel-Level Classification
Jinho Jeong, Jinwoo Kim, Younghyun Jo, Seon Joo Kim
In recent times, the need for effective super-resolution (SR) techniques has surged, especially for large-scale images ranging 2K to 8K resolutions. For DNN-based SISR, decomposing images into overlapping patches is typically necessary due to computational constraints. In such patch-decomposing scheme, one can allocate computational resources differently based on each patch's difficulty to further improve efficiency while maintaining SR performance. However, this approach has a limitation: computational resources is uniformly allocated within a patch, leading to lower efficiency when the patch contain pixels with varying levels of restoration difficulty. To address the issue, we propose the Pixel-level Classifier for Single Image Super-Resolution (PCSR), a novel method designed to distribute computational resources adaptively at the pixel level. A PCSR model comprises a backbone, a pixel-level classifier, and a set of pixel-level upsamplers with varying capacities. The pixel-level classifier assigns each pixel to an appropriate upsampler based on its restoration difficulty, thereby optimizing computational resource usage. Our method allows for performance and computational cost balance during inference without re-training. Our experiments demonstrate PCSR's advantage over existing patch-distributing methods in PSNR-FLOP trade-offs across different backbone models and benchmarks. The code is available at https://github.com/3587jjh/PCSR.
Read more8/1/2024
0
Make a Cheap Scaling: A Self-Cascade Diffusion Model for Higher-Resolution Adaptation
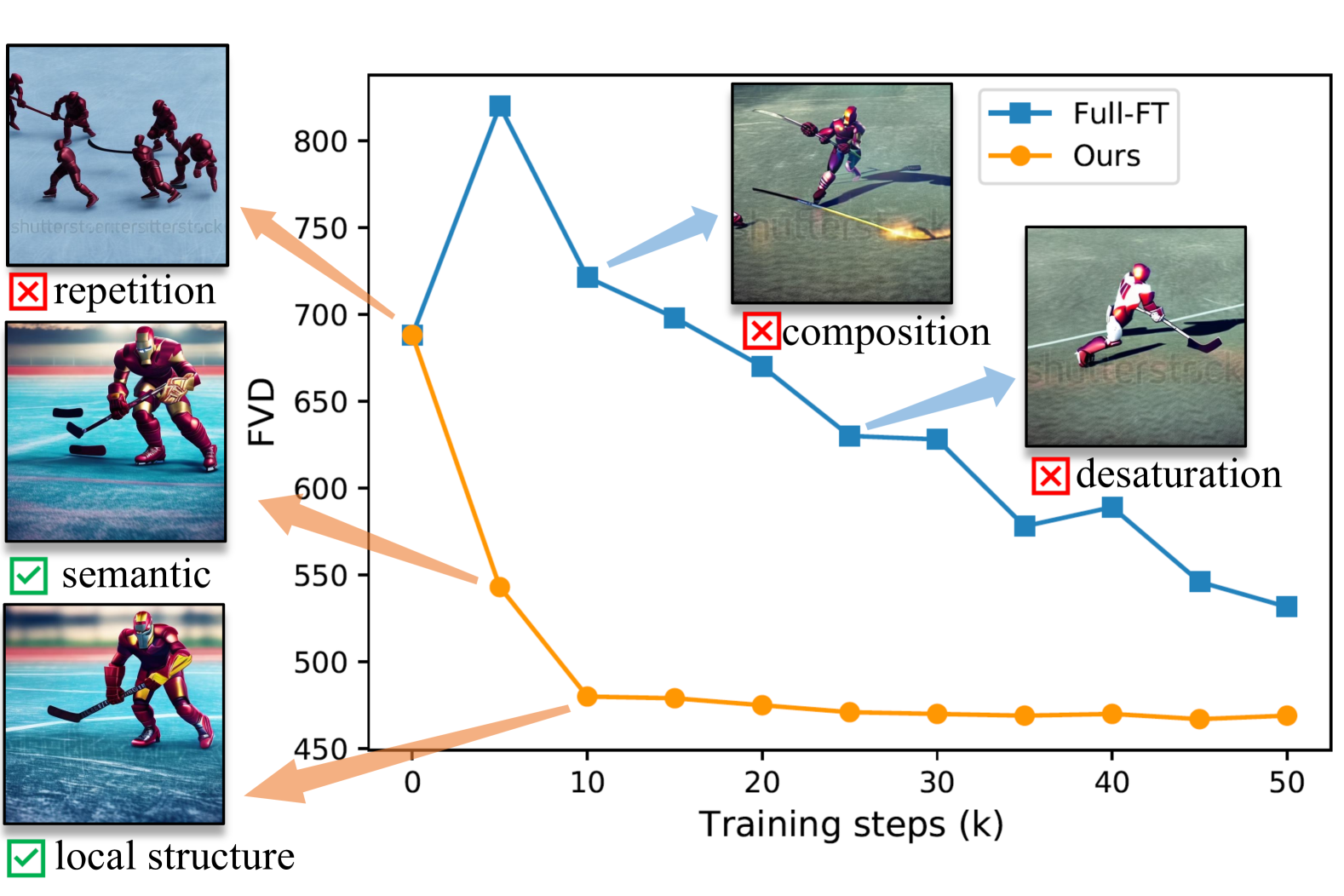
Lanqing Guo, Yingqing He, Haoxin Chen, Menghan Xia, Xiaodong Cun, Yufei Wang, Siyu Huang, Yong Zhang, Xintao Wang, Qifeng Chen, Ying Shan, Bihan Wen
Diffusion models have proven to be highly effective in image and video generation; however, they encounter challenges in the correct composition of objects when generating images of varying sizes due to single-scale training data. Adapting large pre-trained diffusion models to higher resolution demands substantial computational and optimization resources, yet achieving generation capabilities comparable to low-resolution models remains challenging. This paper proposes a novel self-cascade diffusion model that leverages the knowledge gained from a well-trained low-resolution image/video generation model, enabling rapid adaptation to higher-resolution generation. Building on this, we employ the pivot replacement strategy to facilitate a tuning-free version by progressively leveraging reliable semantic guidance derived from the low-resolution model. We further propose to integrate a sequence of learnable multi-scale upsampler modules for a tuning version capable of efficiently learning structural details at a new scale from a small amount of newly acquired high-resolution training data. Compared to full fine-tuning, our approach achieves a $5times$ training speed-up and requires only 0.002M tuning parameters. Extensive experiments demonstrate that our approach can quickly adapt to higher-resolution image and video synthesis by fine-tuning for just $10k$ steps, with virtually no additional inference time.
Read more9/23/2024

0
Hierarchical Patch Diffusion Models for High-Resolution Video Generation
Ivan Skorokhodov, Willi Menapace, Aliaksandr Siarohin, Sergey Tulyakov
Diffusion models have demonstrated remarkable performance in image and video synthesis. However, scaling them to high-resolution inputs is challenging and requires restructuring the diffusion pipeline into multiple independent components, limiting scalability and complicating downstream applications. This makes it very efficient during training and unlocks end-to-end optimization on high-resolution videos. We improve PDMs in two principled ways. First, to enforce consistency between patches, we develop deep context fusion -- an architectural technique that propagates the context information from low-scale to high-scale patches in a hierarchical manner. Second, to accelerate training and inference, we propose adaptive computation, which allocates more network capacity and computation towards coarse image details. The resulting model sets a new state-of-the-art FVD score of 66.32 and Inception Score of 87.68 in class-conditional video generation on UCF-101 $256^2$, surpassing recent methods by more than 100%. Then, we show that it can be rapidly fine-tuned from a base $36times 64$ low-resolution generator for high-resolution $64 times 288 times 512$ text-to-video synthesis. To the best of our knowledge, our model is the first diffusion-based architecture which is trained on such high resolutions entirely end-to-end. Project webpage: https://snap-research.github.io/hpdm.
Read more6/13/2024