Towards Hierarchical Multi-Agent Workflows for Zero-Shot Prompt Optimization

0
Sign in to get full access
Overview
- This paper proposes a hierarchical multi-agent workflow for optimizing language model prompts in a zero-shot manner.
- The approach involves using a team of specialized agents to collaboratively explore and refine prompts, without requiring labeled training data.
- The authors demonstrate the effectiveness of their method on various tasks, including few-shot learning, knowledge probing, and safety-critical applications.
Plain English Explanation
The research presented in this paper explores a new way to optimize the prompts used to get high-quality outputs from large language models. Prompts are the instructions or requests we give to these models to generate relevant and informative text.
The key insight of this work is that we can use a team of specialized software "agents" to collaboratively explore and refine prompts, without needing a lot of labeled training data. Each agent has a particular area of expertise, like generating concise prompts or ensuring the output is safe and appropriate.
By having these agents work together in a structured way, the researchers show they can find high-performing prompts for a variety of tasks, from few-shot learning to probing a model's knowledge to safety-critical applications. This is an important step forward, as manually designing good prompts can be very time-consuming and difficult.
Overall, this hierarchical multi-agent approach represents an exciting new direction for prompt optimization, building on recent work in areas like task-aware prompt engineering and exploring the capabilities of prompted language models. It has the potential to make it much easier to get high-quality outputs from these powerful language models, with important applications in education, content creation, and beyond.
Technical Explanation
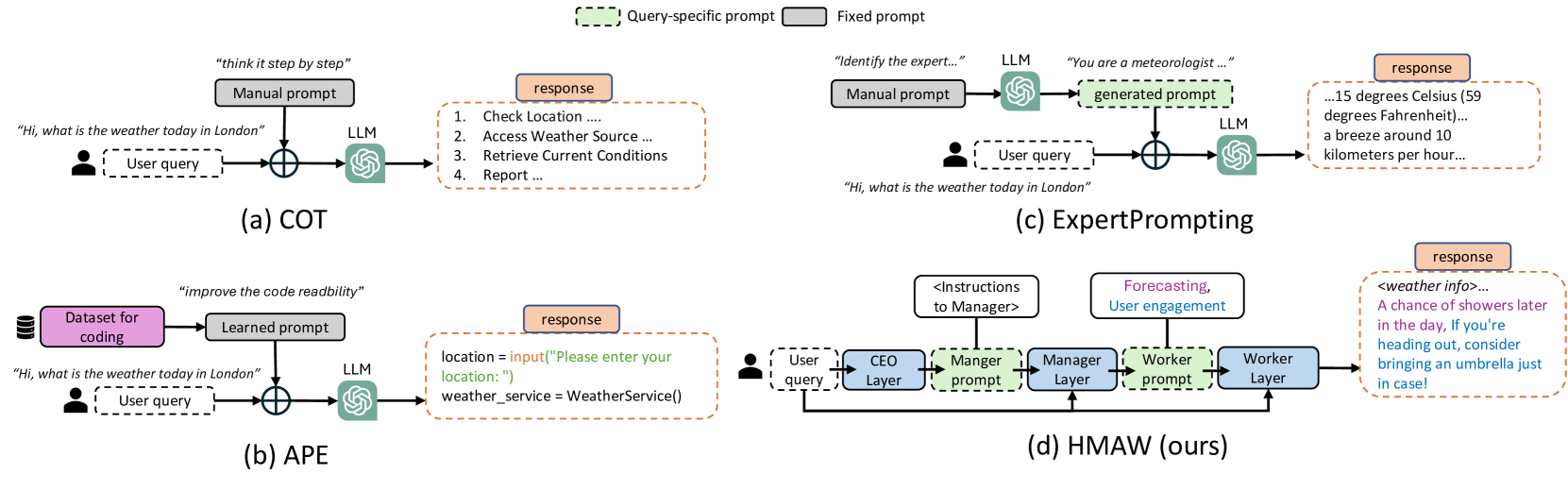
The core idea of this paper is to use a hierarchical multi-agent workflow to optimize prompts for large language models in a zero-shot manner. The authors propose an architecture with several specialized agents, each focused on a particular aspect of prompt quality, such as conciseness, safety, or task-specificity.
These agents collaboratively explore the prompt space, refining and iterating on prompts to find high-performing ones without the need for labeled training data. The hierarchical structure allows for higher-level agents to coordinate the efforts of lower-level agents, guiding the overall optimization process.
The researchers evaluate their method on a range of tasks, including few-shot learning, knowledge probing, and safety-critical applications. They show that their multi-agent approach outperforms single-agent baselines and can discover prompts that achieve state-of-the-art performance, even in challenging zero-shot settings.
This work builds on recent advancements in prompt-based language model optimization and semantic-guided prompt organization. By introducing a multi-agent framework, the authors demonstrate the potential for collaborative, task-driven prompt engineering to unlock the full potential of large language models.
Critical Analysis
The authors present a compelling approach to prompt optimization, with a well-designed multi-agent architecture and thorough experimental evaluation. However, a few potential limitations and areas for further research are worth noting:
-
The scalability of the multi-agent system: As the number of agents and the complexity of the task domain increases, the coordination and communication between agents may become a bottleneck. Further research is needed to understand the scaling properties of this approach.
-
The reliance on a fixed set of agent types: The current implementation uses a predefined set of agent specialties (e.g., conciseness, safety). An interesting direction would be to explore more flexible, adaptive agent capabilities that can emerge during the optimization process.
-
The need for a diverse and representative set of evaluation tasks: While the authors cover a range of applications, there may be other domains or use cases where the multi-agent approach does not perform as well. Expanding the evaluation to a broader set of tasks would help better understand the strengths and limitations of the proposed method.
-
The potential for bias and fairness issues: As with any language model optimization technique, there are important considerations around algorithmic bias and fairness that should be carefully examined, especially for safety-critical applications.
Overall, this work represents an exciting step forward in the field of prompt engineering and language model optimization. By introducing a collaborative, multi-agent framework, the authors have opened up new avenues for further research and real-world applications.
Conclusion
The paper presents a novel hierarchical multi-agent workflow for optimizing language model prompts in a zero-shot manner. This approach leverages a team of specialized agents to collaboratively explore and refine prompts, without requiring labeled training data.
The authors demonstrate the effectiveness of their method on a variety of tasks, including few-shot learning, knowledge probing, and safety-critical applications. This work builds on recent advancements in prompt-based optimization and represents an important step forward in unlocking the full potential of large language models.
While the proposed system shows promising results, there are a few areas for further research, such as scalability, agent adaptability, and fairness considerations. Overall, this multi-agent prompt optimization framework has the potential to significantly streamline and improve the process of getting high-quality outputs from language models, with far-reaching implications for fields like education, content creation, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Towards Hierarchical Multi-Agent Workflows for Zero-Shot Prompt Optimization
Yuchi Liu, Jaskirat Singh, Gaowen Liu, Ali Payani, Liang Zheng
Large language models (LLMs) have shown great progress in responding to user questions, allowing for a multitude of diverse applications. Yet, the quality of LLM outputs heavily depends on the prompt design, where a good prompt might enable the LLM to answer a very challenging question correctly. Therefore, recent works have developed many strategies for improving the prompt, including both manual crafting and in-domain optimization. However, their efficacy in unrestricted scenarios remains questionable, as the former depends on human design for specific questions and the latter usually generalizes poorly to unseen scenarios. To address these problems, we give LLMs the freedom to design the best prompts according to themselves. Specifically, we include a hierarchy of LLMs, first constructing a prompt with precise instructions and accurate wording in a hierarchical manner, and then using this prompt to generate the final answer to the user query. We term this pipeline Hierarchical Multi-Agent Workflow, or HMAW. In contrast with prior works, HMAW imposes no human restriction and requires no training, and is completely task-agnostic while capable of adjusting to the nuances of the underlying task. Through both quantitative and qualitative experiments across multiple benchmarks, we verify that despite its simplicity, the proposed approach can create detailed and suitable prompts, further boosting the performance of current LLMs.
Read more5/31/2024
🛠️
0
PromptWizard: Task-Aware Agent-driven Prompt Optimization Framework
Eshaan Agarwal, Vivek Dani, Tanuja Ganu, Akshay Nambi
Large language models (LLMs) have revolutionized AI across diverse domains, showcasing remarkable capabilities. Central to their success is the concept of prompting, which guides model output generation. However, manual prompt engineering is labor-intensive and domain-specific, necessitating automated solutions. This paper introduces PromptWizard, a novel framework leveraging LLMs to iteratively synthesize and refine prompts tailored to specific tasks. Unlike existing approaches, PromptWizard optimizes both prompt instructions and in-context examples, maximizing model performance. The framework iteratively refines prompts by mutating instructions and incorporating negative examples to deepen understanding and ensure diversity. It further enhances both instructions and examples with the aid of a critic, synthesizing new instructions and examples enriched with detailed reasoning steps for optimal performance. PromptWizard offers several key features and capabilities, including computational efficiency compared to state-of-the-art approaches, adaptability to scenarios with varying amounts of training data, and effectiveness with smaller LLMs. Rigorous evaluation across 35 tasks on 8 datasets demonstrates PromptWizard's superiority over existing prompt strategies, showcasing its efficacy and scalability in prompt optimization.
Read more5/29/2024
0
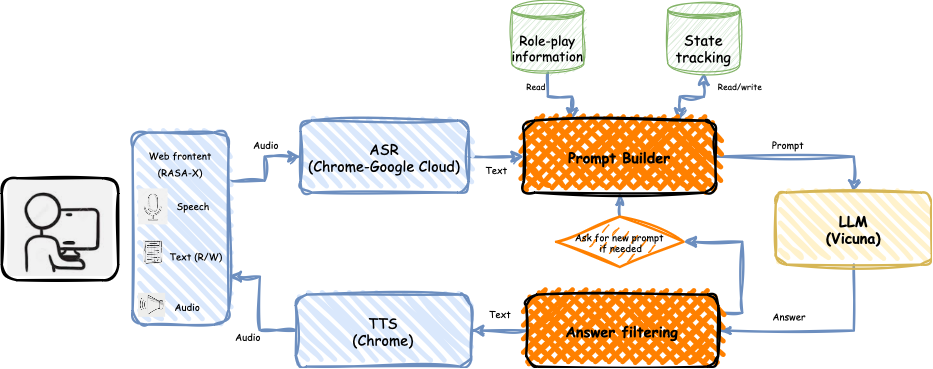
Role-Play Zero-Shot Prompting with Large Language Models for Open-Domain Human-Machine Conversation
Ahmed Njifenjou, Virgile Sucal, Bassam Jabaian, Fabrice Lef`evre
Recently, various methods have been proposed to create open-domain conversational agents with Large Language Models (LLMs). These models are able to answer user queries, but in a one-way Q&A format rather than a true conversation. Fine-tuning on particular datasets is the usual way to modify their style to increase conversational ability, but this is expensive and usually only available in a few languages. In this study, we explore role-play zero-shot prompting as an efficient and cost-effective solution for open-domain conversation, using capable multilingual LLMs (Beeching et al., 2023) trained to obey instructions. We design a prompting system that, when combined with an instruction-following model - here Vicuna (Chiang et al., 2023) - produces conversational agents that match and even surpass fine-tuned models in human evaluation in French in two different tasks.
Read more6/27/2024

0
RePrompt: Planning by Automatic Prompt Engineering for Large Language Models Agents
Weizhe Chen, Sven Koenig, Bistra Dilkina
In this past year, large language models (LLMs) have had remarkable success in domains outside the traditional natural language processing, and people are starting to explore the usage of LLMs in more general and close to application domains like code generation, travel planning, and robot controls. Connecting these LLMs with great capacity and external tools, people are building the so-called LLM agents, which are supposed to help people do all kinds of work in everyday life. In all these domains, the prompt to the LLMs has been shown to make a big difference in what the LLM would generate and thus affect the performance of the LLM agents. Therefore, automatic prompt engineering has become an important question for many researchers and users of LLMs. In this paper, we propose a novel method, textsc{RePrompt}, which does gradient descent to optimize the step-by-step instructions in the prompt of the LLM agents based on the chat history obtained from interactions with LLM agents. By optimizing the prompt, the LLM will learn how to plan in specific domains. We have used experiments in PDDL generation and travel planning to show that our method could generally improve the performance for different reasoning tasks when using the updated prompt as the initial prompt.
Read more6/18/2024