Dance-to-Music Generation with Encoder-based Textual Inversion

0
Sign in to get full access
Overview
- This paper presents a method for generating dance animations synchronized with music.
- The approach uses diffusion models, a type of generative AI model, along with a technique called "textual inversion" to create dance-to-music generation.
- Textual inversion allows the model to learn a visual representation from textual descriptions, enabling the generation of dance animations from music input.
Plain English Explanation
The researchers developed a system that can create dance animations that match the rhythm and style of a given piece of music. They used a diffusion model, which is a type of machine learning model that can generate new images or animations, and a technique called "textual inversion" to teach the model how to translate music into dance.
Textual inversion allows the model to learn a visual representation from text descriptions, so it can generate dance animations that match the characteristics of the music, such as the beat and rhythm. For example, the model could learn that a "lively dance" corresponds to certain body movements and then generate a dance animation that matches the energy of an upbeat song.
This approach enables generating personalized dance animations that are synchronized with any music input, which could have applications in areas like video game animation, virtual concerts, and dance training. It also demonstrates how diffusion models and textual inversion can be used together to create unique and expressive forms of content generation.
Technical Explanation
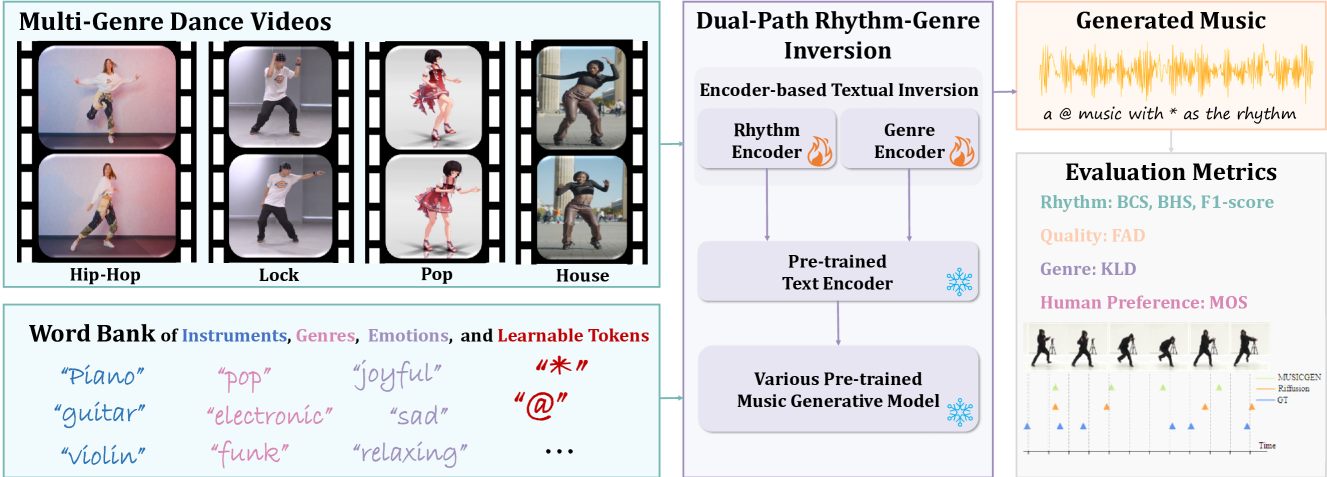
The paper introduces a method for generating dance animations that are synchronized with a given music input. The approach uses a diffusion model, which is a type of generative AI model that can create new images or animations by learning from a training dataset.
To enable the diffusion model to translate music into dance, the researchers employ a technique called "textual inversion." Textual inversion allows the model to learn a visual representation from text descriptions, effectively teaching it how to associate certain dance movements and styles with particular musical characteristics.
The system works as follows:
- The diffusion model is first trained on a dataset of dance animations.
- Then, using textual inversion, the model learns to map textual descriptions of dance styles and movements to the corresponding visual representations.
- Finally, the trained model can generate new dance animations that are synchronized with a given music input, by leveraging the learned associations between music and dance.
The key innovation is the combination of diffusion models and textual inversion, which enables the generation of highly expressive and personalized dance animations from music alone. This approach outperforms previous methods that relied on explicitly defined dance-music mappings or required large datasets of dance-music pairs.
The paper presents results demonstrating the system's ability to generate diverse dance animations that match the rhythm, tempo, and style of various music inputs. The generated dances exhibit natural movements and appear synchronized with the music, showcasing the potential of this technique for applications in areas like video game animation, virtual concerts, and dance training.
Critical Analysis
The paper presents a novel and promising approach for generating dance animations from music input using diffusion models and textual inversion. However, there are a few potential limitations and areas for further research:
-
Dataset Size and Diversity: The success of the approach relies on the quality and diversity of the dance animation dataset used for training. A larger and more comprehensive dataset could potentially lead to even more realistic and diverse dance generation.
-
Evaluation Metrics: The paper primarily evaluates the system's performance through qualitative assessments of the generated dance animations. Developing more objective, quantitative metrics to assess synchronization, naturalness, and diversity of the generated dances could provide a more rigorous evaluation.
-
Real-time Interaction: The current system generates dance animations in a non-interactive, one-way fashion from music input. Exploring ways to enable real-time, interactive dance generation, where the system can dynamically respond to changing music input, could further enhance the practical applications of this approach.
-
Transferability to Other Domains: While the paper focuses on dance-to-music generation, the underlying principles of using diffusion models and textual inversion could potentially be applied to other domains, such as generating animations for other types of movements (e.g., facial expressions, full-body gestures) or translating between different modalities (e.g., text-to-image, image-to-sound).
Overall, the paper presents a compelling and innovative approach to dance-to-music generation that leverages the strengths of diffusion models and textual inversion. Further research and refinement in the areas mentioned could lead to even more powerful and versatile content generation systems.
Conclusion
This paper introduces a novel method for generating dance animations that are synchronized with music input. By combining diffusion models and textual inversion, the researchers demonstrate a system that can translate music characteristics, such as rhythm and style, into corresponding dance movements and animations.
The key contribution of this work is the integration of diffusion models and textual inversion, which enables the model to learn the association between music and dance without requiring large datasets of paired examples. This approach results in expressive and personalized dance animations that match the input music, showcasing the potential of this technique for applications in areas like video game animation, virtual concerts, and dance training.
While the paper presents promising results, there are opportunities for further research, such as expanding the dataset, developing more comprehensive evaluation metrics, and exploring real-time interactive capabilities. Nonetheless, this work represents an important step forward in the field of generative AI-powered content creation, and the underlying principles could potentially be applied to other domains beyond dance-to-music generation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Dance-to-Music Generation with Encoder-based Textual Inversion
Sifei Li, Weiming Dong, Yuxin Zhang, Fan Tang, Chongyang Ma, Oliver Deussen, Tong-Yee Lee, Changsheng Xu
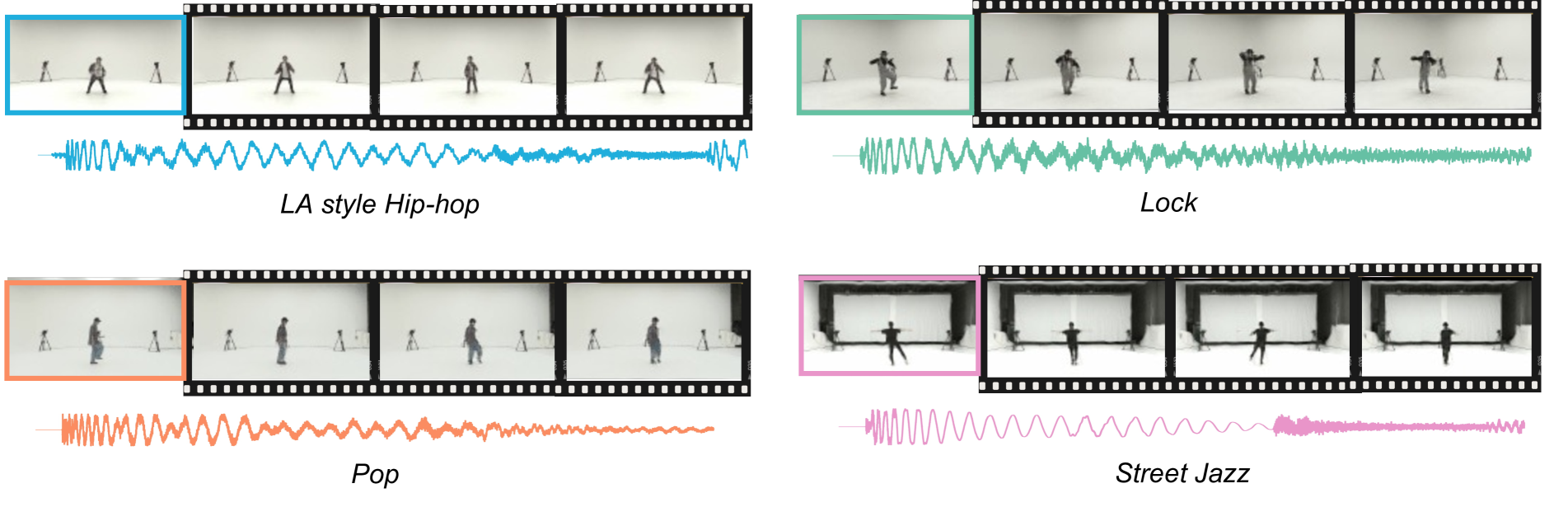
The seamless integration of music with dance movements is essential for communicating the artistic intent of a dance piece. This alignment also significantly improves the immersive quality of gaming experiences and animation productions. Although there has been remarkable advancement in creating high-fidelity music from textual descriptions, current methodologies mainly focus on modulating overall characteristics such as genre and emotional tone. They often overlook the nuanced management of temporal rhythm, which is indispensable in crafting music for dance, since it intricately aligns the musical beats with the dancers' movements. Recognizing this gap, we propose an encoder-based textual inversion technique to augment text-to-music models with visual control, facilitating personalized music generation. Specifically, we develop dual-path rhythm-genre inversion to effectively integrate the rhythm and genre of a dance motion sequence into the textual space of a text-to-music model. Contrary to traditional textual inversion methods, which directly update text embeddings to reconstruct a single target object, our approach utilizes separate rhythm and genre encoders to obtain text embeddings for two pseudo-words, adapting to the varying rhythms and genres. We collect a new dataset called In-the-wild Dance Videos (InDV) and demonstrate that our approach outperforms state-of-the-art methods across multiple evaluation metrics. Furthermore, our method is able to adapt to changes in tempo and effectively integrates with the inherent text-guided generation capability of the pre-trained model. Our source code and demo videos are available at url{https://github.com/lsfhuihuiff/Dance-to-music_Siggraph_Asia_2024}
Read more9/16/2024
0
Dance Any Beat: Blending Beats with Visuals in Dance Video Generation
Xuanchen Wang, Heng Wang, Dongnan Liu, Weidong Cai
Automated choreography advances by generating dance from music. Current methods create skeleton keypoint sequences, not full dance videos, and cannot make specific individuals dance, limiting their real-world use. These methods also need precise keypoint annotations, making data collection difficult and restricting the use of self-made video datasets. To overcome these challenges, we introduce a novel task: generating dance videos directly from images of individuals guided by music. This task enables the dance generation of specific individuals without requiring keypoint annotations, making it more versatile and applicable to various situations. Our solution, the Dance Any Beat Diffusion model (DabFusion), utilizes a reference image and a music piece to generate dance videos featuring various dance types and choreographies. The music is analyzed by our specially designed music encoder, which identifies essential features including dance style, movement, and rhythm. DabFusion excels in generating dance videos not only for individuals in the training dataset but also for any previously unseen person. This versatility stems from its approach of generating latent optical flow, which contains all necessary motion information to animate any person in the image. We evaluate DabFusion's performance using the AIST++ dataset, focusing on video quality, audio-video synchronization, and motion-music alignment. We propose a 2D Motion-Music Alignment Score (2D-MM Align), which builds on the Beat Alignment Score to more effectively evaluate motion-music alignment for this new task. Experiments show that our DabFusion establishes a solid baseline for this innovative task. Video results can be found on our project page: https://DabFusion.github.io.
Read more7/17/2024

0
High Fidelity Text-Guided Music Generation and Editing via Single-Stage Flow Matching
Gael Le Lan, Bowen Shi, Zhaoheng Ni, Sidd Srinivasan, Anurag Kumar, Brian Ellis, David Kant, Varun Nagaraja, Ernie Chang, Wei-Ning Hsu, Yangyang Shi, Vikas Chandra
We introduce a simple and efficient text-controllable high-fidelity music generation and editing model. It operates on sequences of continuous latent representations from a low frame rate 48 kHz stereo variational auto encoder codec that eliminates the information loss drawback of discrete representations. Based on a diffusion transformer architecture trained on a flow-matching objective the model can generate and edit diverse high quality stereo samples of variable duration, with simple text descriptions. We also explore a new regularized latent inversion method for zero-shot test-time text-guided editing and demonstrate its superior performance over naive denoising diffusion implicit model (DDIM) inversion for variety of music editing prompts. Evaluations are conducted on both objective and subjective metrics and demonstrate that the proposed model is not only competitive to the evaluated baselines on a standard text-to-music benchmark - quality and efficiency-wise - but also outperforms previous state of the art for music editing when combined with our proposed latent inversion. Samples are available at https://melodyflow.github.io.
Read more7/8/2024

0
MIDGET: Music Conditioned 3D Dance Generation
Jinwu Wang, Wei Mao, Miaomiao Liu
In this paper, we introduce a MusIc conditioned 3D Dance GEneraTion model, named MIDGET based on Dance motion Vector Quantised Variational AutoEncoder (VQ-VAE) model and Motion Generative Pre-Training (GPT) model to generate vibrant and highquality dances that match the music rhythm. To tackle challenges in the field, we introduce three new components: 1) a pre-trained memory codebook based on the Motion VQ-VAE model to store different human pose codes, 2) employing Motion GPT model to generate pose codes with music and motion Encoders, 3) a simple framework for music feature extraction. We compare with existing state-of-the-art models and perform ablation experiments on AIST++, the largest publicly available music-dance dataset. Experiments demonstrate that our proposed framework achieves state-of-the-art performance on motion quality and its alignment with the music.
Read more4/19/2024