High-Performance Hybrid Algorithm for Minimum Sum-of-Squares Clustering of Infinitely Tall Data

0
🔍
Sign in to get full access
Overview
- This paper introduces a new formulation of the clustering problem called Minimum Sum-of-Squares Clustering of Infinitely Tall Data (MSSC-ITD).
- It presents HPClust, a novel set of hybrid parallel approaches for effectively solving the MSSC-ITD problem.
- HPClust leverages modern high-performance computing techniques to enhance key clustering metrics: effectiveness, computational efficiency, and scalability.
- Unlike traditional data parallelism, HPClust uses multi-strategy competitive-cooperative parallelism and exploits the properties of the objective function landscape to achieve superior performance.
- The paper demonstrates that HPClust outperforms even advanced algorithms designed for small and medium-sized datasets, thanks to its inherent parallelism and improved solution quality.
Plain English Explanation
Clustering is a common task in data analysis, where the goal is to group similar data points together. This paper introduces a new and more challenging version of the clustering problem, called Minimum Sum-of-Squares Clustering of Infinitely Tall Data (MSSC-ITD).
To solve this problem, the researchers developed a novel set of techniques called HPClust. HPClust uses parallel processing to make the clustering process more efficient and accurate. Unlike simple parallelism that just speeds up the processing time, HPClust employs a more sophisticated approach called "multi-strategy competitive-cooperative parallelism."
This means HPClust uses different parallel strategies that compete and cooperate with each other to find the best clustering solution. By leveraging the characteristics of the problem's objective function, HPClust can achieve significantly better performance than even advanced clustering algorithms designed for smaller datasets.
The key benefits of HPClust are that it can cluster large datasets more effectively, efficiently, and with better scalability compared to other methods. The researchers demonstrate through experiments that HPClust outperforms traditional and state-of-the-art clustering algorithms, not just in terms of speed, but also in the quality of the clustering results.
Technical Explanation
The paper introduces the Minimum Sum-of-Squares Clustering of Infinitely Tall Data (MSSC-ITD) problem, which is a novel formulation of the clustering problem. To solve this problem, the researchers present HPClust, a set of innovative hybrid parallel approaches.
Unlike simple data parallelism that only accelerates processing time, HPClust leverages multi-strategy competitive-cooperative parallelism and exploits the properties of the objective function landscape to achieve superior performance in terms of effectiveness, computational efficiency, and scalability.
The key innovation of HPClust is its ability to outperform even advanced algorithms designed for small and medium-sized datasets. This is because HPClust is inherently parallel in nature, which improves solution quality through increased scalability and parallelism.
The paper evaluates four parallel strategies within the HPClust framework and demonstrates its superiority over traditional and cutting-edge methods in terms of key clustering metrics. The results show that parallel processing not only enhances the clustering efficiency but also the accuracy.
Critical Analysis
The paper provides a thorough evaluation of the HPClust algorithm and its performance compared to other state-of-the-art clustering methods. However, the paper does not discuss the potential limitations or caveats of the proposed approach.
For instance, the paper does not explore the impact of the specific parallel strategies used or the tradeoffs between computational efficiency and clustering quality. It would be valuable to understand how the different parallel approaches perform under various dataset characteristics and resource constraints.
Additionally, the paper focuses on synthetic data experiments, and it would be helpful to see the algorithm's performance on real-world datasets with different properties and challenges. This could provide further insights into the practical applicability and robustness of the HPClust approach.
Despite these minor limitations, the paper makes a valuable contribution to the field of parallel clustering algorithms, demonstrating the potential of leveraging modern high-performance computing techniques to enhance the effectiveness, efficiency, and scalability of clustering tasks.
Conclusion
This paper introduces a novel formulation of the clustering problem, the Minimum Sum-of-Squares Clustering of Infinitely Tall Data (MSSC-ITD), and presents HPClust, an innovative set of hybrid parallel approaches for its effective solution.
HPClust leverages modern high-performance computing techniques to enhance key clustering metrics, such as effectiveness, computational efficiency, and scalability. Unlike traditional data parallelism, HPClust employs a more sophisticated multi-strategy competitive-cooperative parallelism that exploits the properties of the objective function landscape, allowing it to outperform even advanced algorithms designed for small and medium-sized datasets.
The evaluation of HPClust demonstrates its superior performance over traditional and cutting-edge methods, highlighting the importance of parallel processing not only for improving clustering efficiency but also for enhancing the accuracy of the results.
This research advances our understanding of parallelism in clustering algorithms and showcases the benefits of a judicious hybridization of advanced parallel approaches for solving the MSSC-ITD problem. The exceptional scalability and robustness to noise exhibited by HPClust suggest its potential for practical applications in big data analysis and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
High-Performance Hybrid Algorithm for Minimum Sum-of-Squares Clustering of Infinitely Tall Data
Ravil Mussabayev, Rustam Mussabayev
This paper introduces a novel formulation of the clustering problem, namely the Minimum Sum-of-Squares Clustering of Infinitely Tall Data (MSSC-ITD), and presents HPClust, an innovative set of hybrid parallel approaches for its effective solution. By utilizing modern high-performance computing techniques, HPClust enhances key clustering metrics: effectiveness, computational efficiency, and scalability. In contrast to vanilla data parallelism, which only accelerates processing time through the MapReduce framework, our approach unlocks superior performance by leveraging the multi-strategy competitive-cooperative parallelism and intricate properties of the objective function landscape. Unlike other available algorithms that struggle to scale, our algorithm is inherently parallel in nature, improving solution quality through increased scalability and parallelism, and outperforming even advanced algorithms designed for small and medium-sized datasets. Our evaluation of HPClust, featuring four parallel strategies, demonstrates its superiority over traditional and cutting-edge methods by offering better performance in the key metrics. These results also show that parallel processing not only enhances the clustering efficiency, but the accuracy as well. Additionally, we explore the balance between computational efficiency and clustering quality, providing insights into optimal parallel strategies based on dataset specifics and resource availability. This research advances our understanding of parallelism in clustering algorithms, demonstrating that a judicious hybridization of advanced parallel approaches yields optimal results for MSSC-ITD. Experiments on synthetic data further confirm HPClust's exceptional scalability and robustness to noise.
Read more6/19/2024
0
Distributed-Memory Parallel Algorithms for Sparse Matrix and Sparse Tall-and-Skinny Matrix Multiplication
Isuru Ranawaka, Md Taufique Hussain, Charles Block, Gerasimos Gerogiannis, Josep Torrellas, Ariful Azad
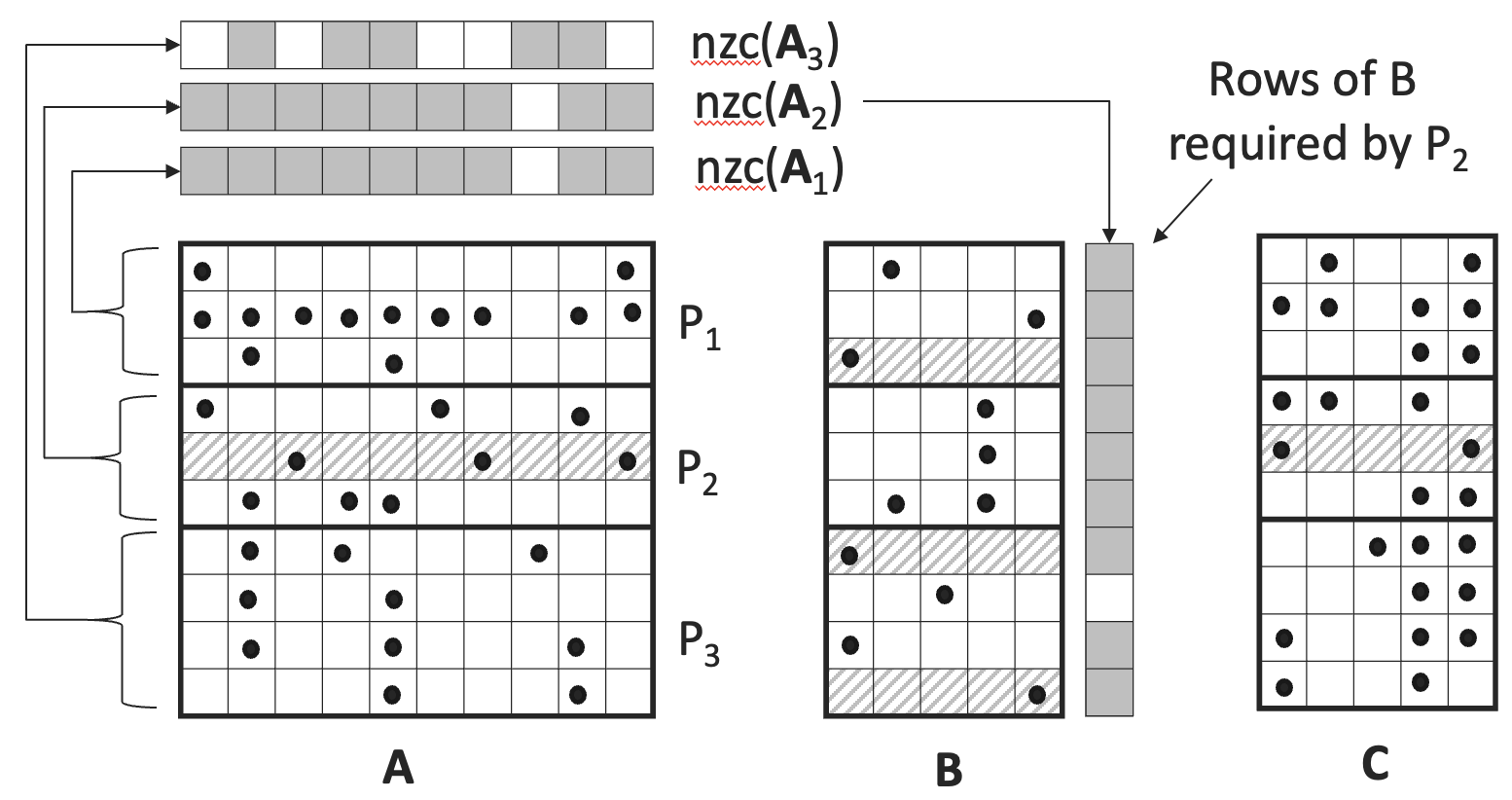
We consider a sparse matrix-matrix multiplication (SpGEMM) setting where one matrix is square and the other is tall and skinny. This special variant, called TS-SpGEMM, has important applications in multi-source breadth-first search, influence maximization, sparse graph embedding, and algebraic multigrid solvers. Unfortunately, popular distributed algorithms like sparse SUMMA deliver suboptimal performance for TS-SpGEMM. To address this limitation, we develop a novel distributed-memory algorithm tailored for TS-SpGEMM. Our approach employs customized 1D partitioning for all matrices involved and leverages sparsity-aware tiling for efficient data transfers. In addition, it minimizes communication overhead by incorporating both local and remote computations. On average, our TS-SpGEMM algorithm attains 5x performance gains over 2D and 3D SUMMA. Furthermore, we use our algorithm to implement multi-source breadth-first search and sparse graph embedding algorithms and demonstrate their scalability up to 512 Nodes (or 65,536 cores) on NERSC Perlmutter.
Read more8/23/2024
🔗
0
Fully Scalable MPC Algorithms for Clustering in High Dimension
Artur Czumaj, Guichen Gao, Shaofeng H. -C. Jiang, Robert Krauthgamer, Pavel Vesel'y
We design new parallel algorithms for clustering in high-dimensional Euclidean spaces. These algorithms run in the Massively Parallel Computation (MPC) model, and are fully scalable, meaning that the local memory in each machine may be $n^{sigma}$ for arbitrarily small fixed $sigma>0$. Importantly, the local memory may be substantially smaller than the number of clusters $k$, yet all our algorithms are fast, i.e., run in $O(1)$ rounds. We first devise a fast MPC algorithm for $O(1)$-approximation of uniform facility location. This is the first fully-scalable MPC algorithm that achieves $O(1)$-approximation for any clustering problem in general geometric setting; previous algorithms only provide $mathrm{poly}(log n)$-approximation or apply to restricted inputs, like low dimension or small number of clusters $k$; e.g. [Bhaskara and Wijewardena, ICML'18; Cohen-Addad et al., NeurIPS'21; Cohen-Addad et al., ICML'22]. We then build on this facility location result and devise a fast MPC algorithm that achieves $O(1)$-bicriteria approximation for $k$-Median and for $k$-Means, namely, it computes $(1+varepsilon)k$ clusters of cost within $O(1/varepsilon^2)$-factor of the optimum for $k$ clusters. A primary technical tool that we introduce, and may be of independent interest, is a new MPC primitive for geometric aggregation, namely, computing for every data point a statistic of its approximate neighborhood, for statistics like range counting and nearest-neighbor search. Our implementation of this primitive works in high dimension, and is based on consistent hashing (aka sparse partition), a technique that was recently used for streaming algorithms [Czumaj et al., FOCS'22].
Read more7/9/2024
0
Fast and Scalable Semi-Supervised Learning for Multi-View Subspace Clustering
Huaming Ling, Chenglong Bao, Jiebo Song, Zuoqiang Shi
In this paper, we introduce a Fast and Scalable Semi-supervised Multi-view Subspace Clustering (FSSMSC) method, a novel solution to the high computational complexity commonly found in existing approaches. FSSMSC features linear computational and space complexity relative to the size of the data. The method generates a consensus anchor graph across all views, representing each data point as a sparse linear combination of chosen landmarks. Unlike traditional methods that manage the anchor graph construction and the label propagation process separately, this paper proposes a unified optimization model that facilitates simultaneous learning of both. An effective alternating update algorithm with convergence guarantees is proposed to solve the unified optimization model. Additionally, the method employs the obtained anchor graph and landmarks' low-dimensional representations to deduce low-dimensional representations for raw data. Following this, a straightforward clustering approach is conducted on these low-dimensional representations to achieve the final clustering results. The effectiveness and efficiency of FSSMSC are validated through extensive experiments on multiple benchmark datasets of varying scales.
Read more8/13/2024