HistNERo: Historical Named Entity Recognition for the Romanian Language

0

Sign in to get full access
Overview
- This paper introduces HistNERo, a dataset for historical named entity recognition in the Romanian language.
- HistNERo contains annotated text from 19th and 20th century Romanian newspapers, allowing for the development and evaluation of named entity recognition (NER) systems on historical data.
- The paper also presents a transformer-based NER model trained on the HistNERo dataset, which outperforms previous state-of-the-art models on historical Romanian text.
Plain English Explanation
Named entity recognition (NER) is a natural language processing task that aims to identify and classify important entities like people, organizations, and locations within text. This is a valuable capability for applications like information extraction, question answering, and knowledge graph construction.
However, most NER datasets and models are built using contemporary text, which can make them less effective on historical documents that use different language and terminology. The HistNERo dataset addresses this by providing annotated text from 19th and 20th century Romanian newspapers. Researchers can use this dataset to train and evaluate NER models specifically for historical Romanian text.
The paper also presents a new NER model built using transformer-based neural networks and trained on the HistNERo dataset. This model outperforms previous state-of-the-art approaches on the historical Romanian text, demonstrating the value of having a specialized dataset and model for this domain.
Technical Explanation
The HistNERo dataset consists of over 200,000 tokens from 19th and 20th century Romanian newspaper articles, manually annotated for named entities including people, locations, organizations, and miscellaneous categories. The dataset is split into training, validation, and test sets to facilitate model development and evaluation.
The paper proposes a transformer-based NER model trained on the HistNERo dataset. The model uses the BERT transformer architecture with custom Romanian language embeddings. It applies a token-level classification head to identify the entity type of each token in the input text.
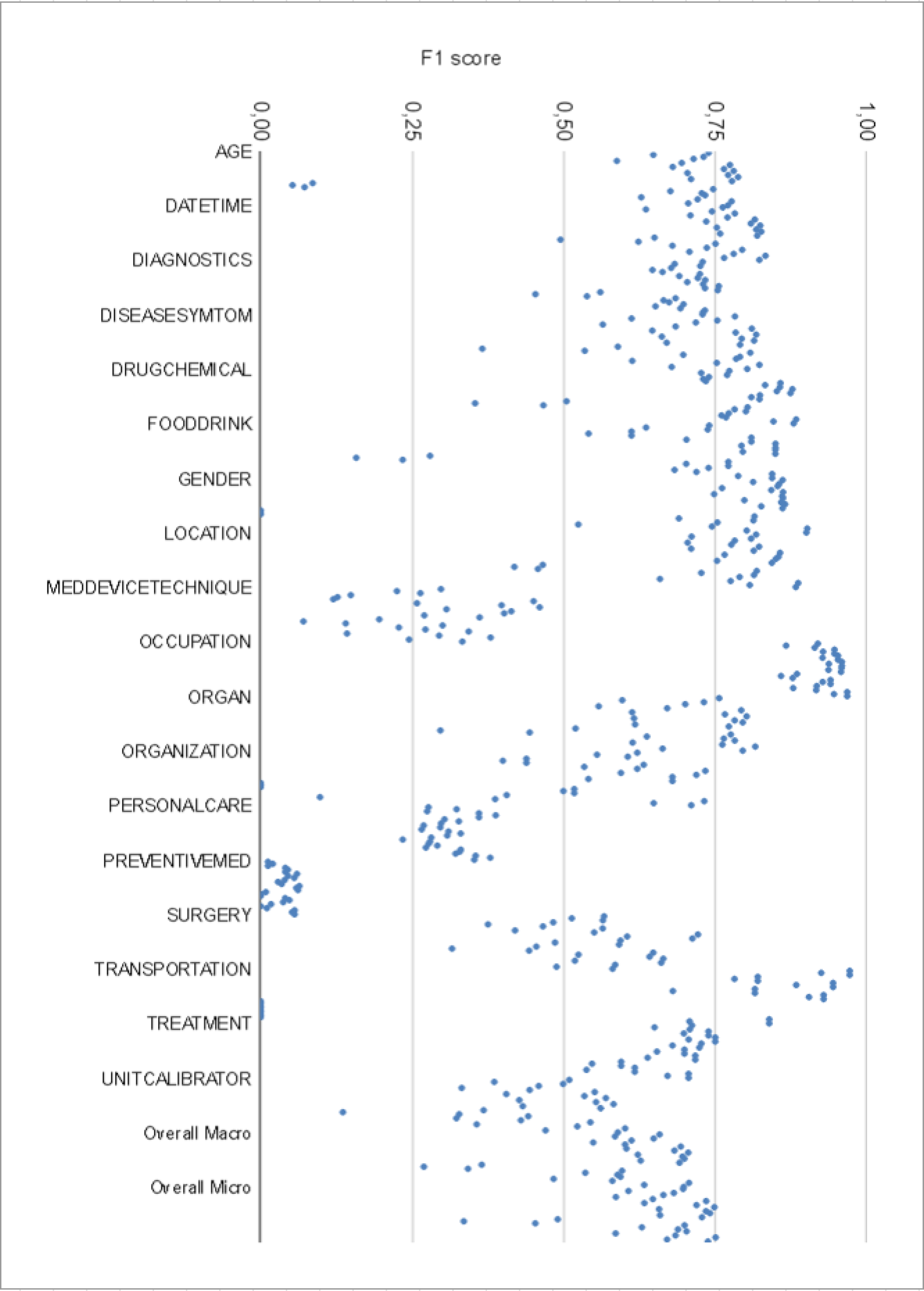
Experiments show that this HistNERo model outperforms previous state-of-the-art NER approaches, including a multilingual BERT model and a Romanian-specific model, on the historical Romanian test set. The model achieves F1 scores of over 90% for person and location entities, demonstrating its effectiveness at recognizing key named entities in the historical domain.
Critical Analysis
The HistNERo dataset and model presented in this paper make valuable contributions to historical named entity recognition, particularly for the Romanian language. By focusing on 19th and 20th century newspaper text, the researchers have created a specialized resource that can help address the challenges of applying modern NLP models to historical data.
However, the paper does not discuss the potential biases or limitations of the HistNERo dataset. The newspaper text may not be representative of all historical Romanian writing, and the manual annotation process could introduce human biases. Additionally, the model's performance on other types of historical Romanian text, such as literature or government documents, is unclear.
The paper also does not provide much insight into the specific challenges of historical NER that the HistNERo model was designed to address. Further analysis of the errors or failures of existing models on this data could have strengthened the motivation for this work.
Overall, the HistNERo dataset and model represent an important step forward for historical named entity recognition, but there is still room for further research to fully understand the unique requirements and challenges of this domain, especially for less-resourced languages like Romanian.
Conclusion
This paper introduces the HistNERo dataset and a transformer-based NER model specifically designed for historical Romanian text. The dataset provides a valuable resource for developing and evaluating named entity recognition systems on 19th and 20th century Romanian newspaper articles, while the proposed model demonstrates strong performance compared to previous approaches.
The work highlights the importance of creating specialized datasets and models for historical language processing, which can help address the limitations of contemporary NLP technologies when applied to archival text. The HistNERo project represents an important contribution to the field of historical natural language processing, and its insights may inspire similar efforts for other languages and domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
HistNERo: Historical Named Entity Recognition for the Romanian Language
Andrei-Marius Avram, Andreea Iuga, George-Vlad Manolache, Vlad-Cristian Matei, Ru{a}zvan-Gabriel Micliuc{s}, Vlad-Andrei Muntean, Manuel-Petru Sorlescu, Dragoc{s}-Andrei c{S}erban, Adrian-Dinu Urse, Vasile Pu{a}ic{s}, Dumitru-Clementin Cercel
This work introduces HistNERo, the first Romanian corpus for Named Entity Recognition (NER) in historical newspapers. The dataset contains 323k tokens of text, covering more than half of the 19th century (i.e., 1817) until the late part of the 20th century (i.e., 1990). Eight native Romanian speakers annotated the dataset with five named entities. The samples belong to one of the following four historical regions of Romania, namely Bessarabia, Moldavia, Transylvania, and Wallachia. We employed this proposed dataset to perform several experiments for NER using Romanian pre-trained language models. Our results show that the best model achieved a strict F1-score of 55.69%. Also, by reducing the discrepancies between regions through a novel domain adaption technique, we improved the performance on this corpus to a strict F1-score of 66.80%, representing an absolute gain of more than 10%.
Read more5/2/2024

0
MSNER: A Multilingual Speech Dataset for Named Entity Recognition
Quentin Meeus, Marie-Francine Moens, Hugo Van hamme
While extensively explored in text-based tasks, Named Entity Recognition (NER) remains largely neglected in spoken language understanding. Existing resources are limited to a single, English-only dataset. This paper addresses this gap by introducing MSNER, a freely available, multilingual speech corpus annotated with named entities. It provides annotations to the VoxPopuli dataset in four languages (Dutch, French, German, and Spanish). We have also releasing an efficient annotation tool that leverages automatic pre-annotations for faster manual refinement. This results in 590 and 15 hours of silver-annotated speech for training and validation, alongside a 17-hour, manually-annotated evaluation set. We further provide an analysis comparing silver and gold annotations. Finally, we present baseline NER models to stimulate further research on this newly available dataset.
Read more5/21/2024
➖
0
CNER: A tool Classifier of Named-Entity Relationships
Jefferson A. Pe~na Torres, Ra'ul E. Guti'errez De Pi~nerez
We introduce CNER, an ensemble of capable tools for extraction of semantic relationships between named entities in Spanish language. Built upon a container-based architecture, CNER integrates different Named entity recognition and relation extraction tools with a user-friendly interface that allows users to input free text or files effortlessly, facilitating streamlined analysis. Developed as a prototype version for the Natural Language Processing (NLP) Group at Universidad del Valle, CNER serves as a practical educational resource, illustrating how machine learning techniques can effectively tackle diverse NLP tasks in Spanish. Our preliminary results reveal the promising potential of CNER in advancing the understanding and development of NLP tools, particularly within Spanish-language contexts.
Read more5/20/2024
0
Medical Spoken Named Entity Recognition
Khai Le-Duc, David Thulke, Hung-Phong Tran, Long Vo-Dang, Khai-Nguyen Nguyen, Truong-Son Hy, Ralf Schluter
Spoken Named Entity Recognition (NER) aims to extracting named entities from speech and categorizing them into types like person, location, organization, etc. In this work, we present VietMed-NER - the first spoken NER dataset in the medical domain. To our best knowledge, our real-world dataset is the largest spoken NER dataset in the world in terms of the number of entity types, featuring 18 distinct types. Secondly, we present baseline results using various state-of-the-art pre-trained models: encoder-only and sequence-to-sequence. We found that pre-trained multilingual models XLM-R outperformed all monolingual models on both reference text and ASR output. Also in general, encoders perform better than sequence-to-sequence models for the NER task. By simply translating, the transcript is applicable not just to Vietnamese but to other languages as well. All code, data and models are made publicly available here: https://github.com/leduckhai/MultiMed
Read more7/23/2024